背景
最近我们把消息队列从 kafka 迁移到 nats, 主要原因是kafka的延迟不能忍受,5ms 其实也不小了,但在几千上万个 topic 的情况下,延迟有时会上升至数百 ms(我猜 topic 多的情况下顺序写的优势不再存在)。迁移到 nats 之后, 使用 Publish-Subscribe 的延迟大概就 1ms, 真香!
但小部分场景需要用到 JetStream 来做持久化,使用了 JetStream 一段时间后发现,每天会随机的丢几条消息,发生的时间完全没有规律。
排查过程
通过命令行查 Stream 消息,发现丢失的消息是有被持久化的,所以问题要么出在服务端:没有把消息发送给客户端;要么客户端把消息弄丢了。 大概看了一些服务端的代码,感觉没有头绪,想想还是从客户端入手比较简单。
首先在客户端接收原始消息那里加了一行日志,经过核对发现客户端确实收到了消息,但没有返回到上层,中间某个地方把消息弄丢了。
再看丢消息的时间点刚好在超时时间的临界点,猜想应该是超时处理的时候把消息丢了。于是写了一个消费者测试代码,把超时时间从 1 秒 调到 0.1 秒,发现 丢消息的概率显著提升。
最后确实发现了丢消息的地方(代码)。
但中间由于我加 debug 日志不够,产生了一个让我费解的疑问。具体如下:
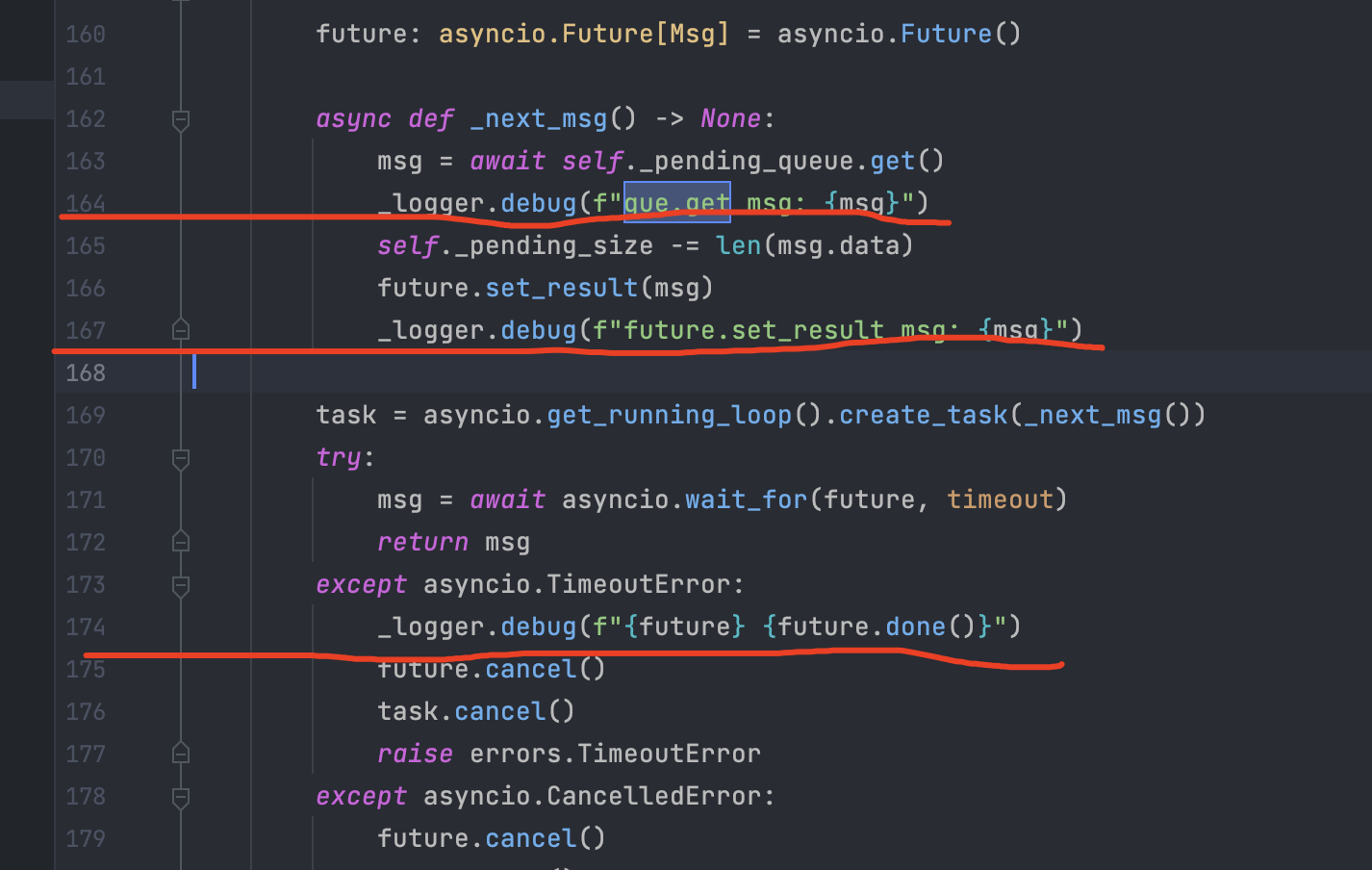
我在 164、167、174 行加了 debug 代码。
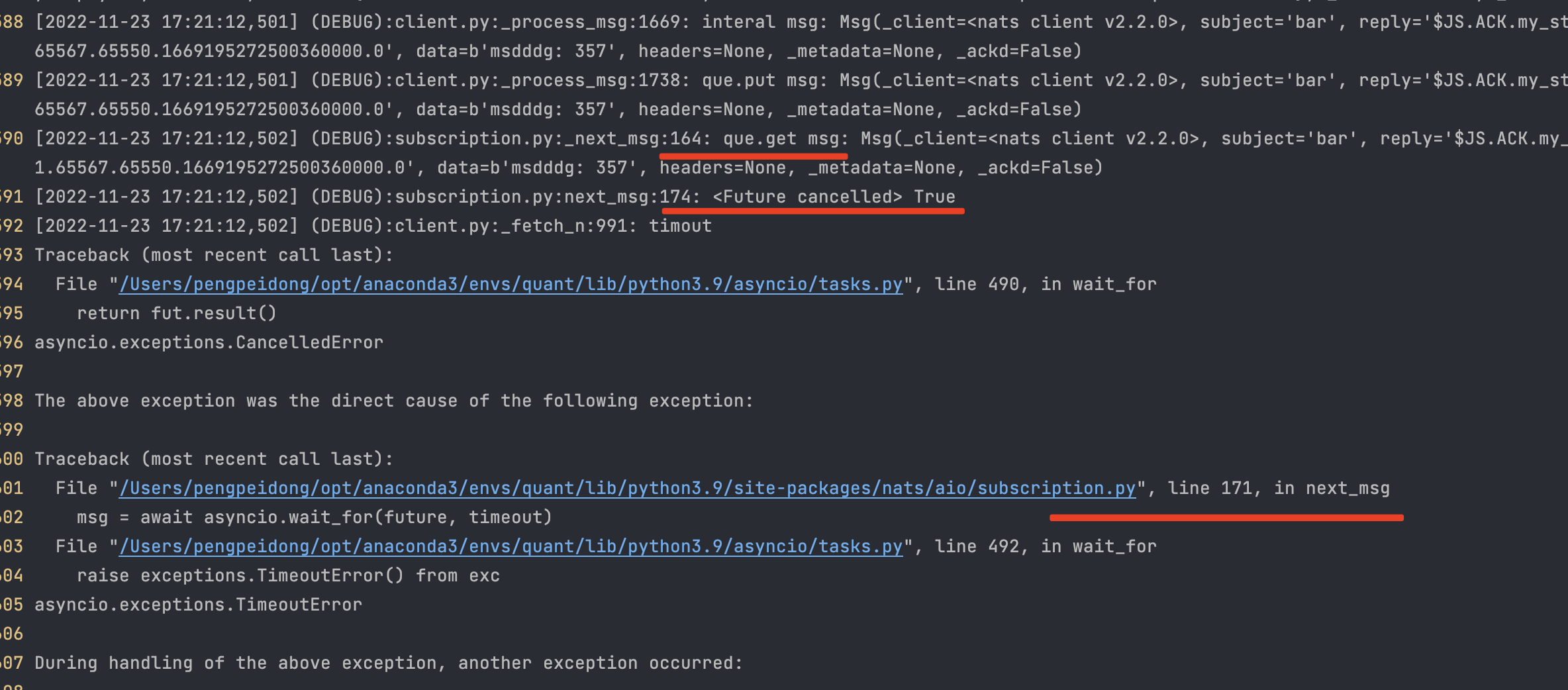
从日志截图来看,代码运行到 164 后直接到了 174 行,167 行没有被运行。这里让我很不接,明明没有协程切换,为什么 167 行没有执行到。
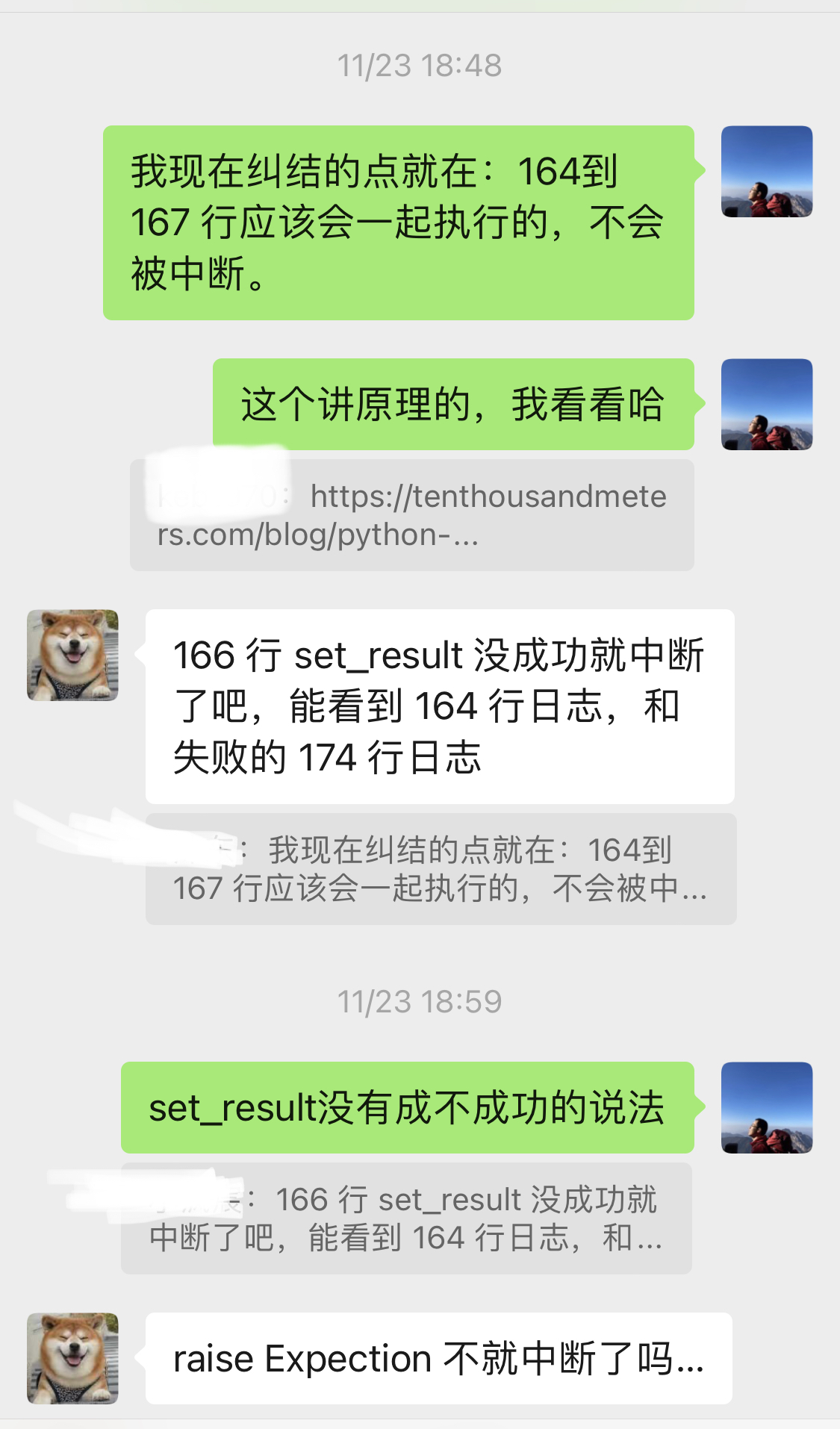
知道在前同事群里请教,才发现是 166 行 set_result 报错了,所以没有执行到 167 行。
消除这个疑问之后,发现了问题的本源:
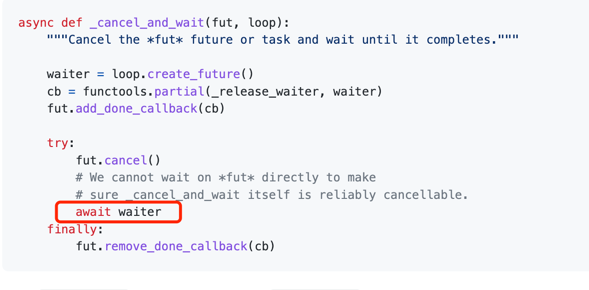
获取消息超时后,会取消future,但问题是取消的过程中可能发生协程切换,如果切换到
pending_queue.get()这个协程方法,就会导致丢掉一条消息。