第一讲 消息系统 ABC
定义
维基百科版: 消息系统是一组规范,利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步数据传递。
传输模型
核心作用
第二讲 kafka 术语
- Record: 消息
- Topic: 主题
- Partition: 分区,有序不变,每个主题至少有一个分区,从 0 开始
- Offset: 分区位移,表示分区中消息的位置信息,单调递增且不变
- Replica: 副本,每个分区可有多个副本,仅 Leader 副本对外提供服务,Follower 副本仅做数据备份
- Producer: 生产者,发布信息
- Consumer: 消息者,消费消息
- Consumer Offset: 消费者位移,表示消费者消费进度
- Consumer Group: 多个消费者组成一个组,共同消费一个主题,实现高吞吐
- Rebalance: 重平衡,消费组某个成员挂掉后,其他消费者自动重新分配订阅主题的过程
示意图如下:
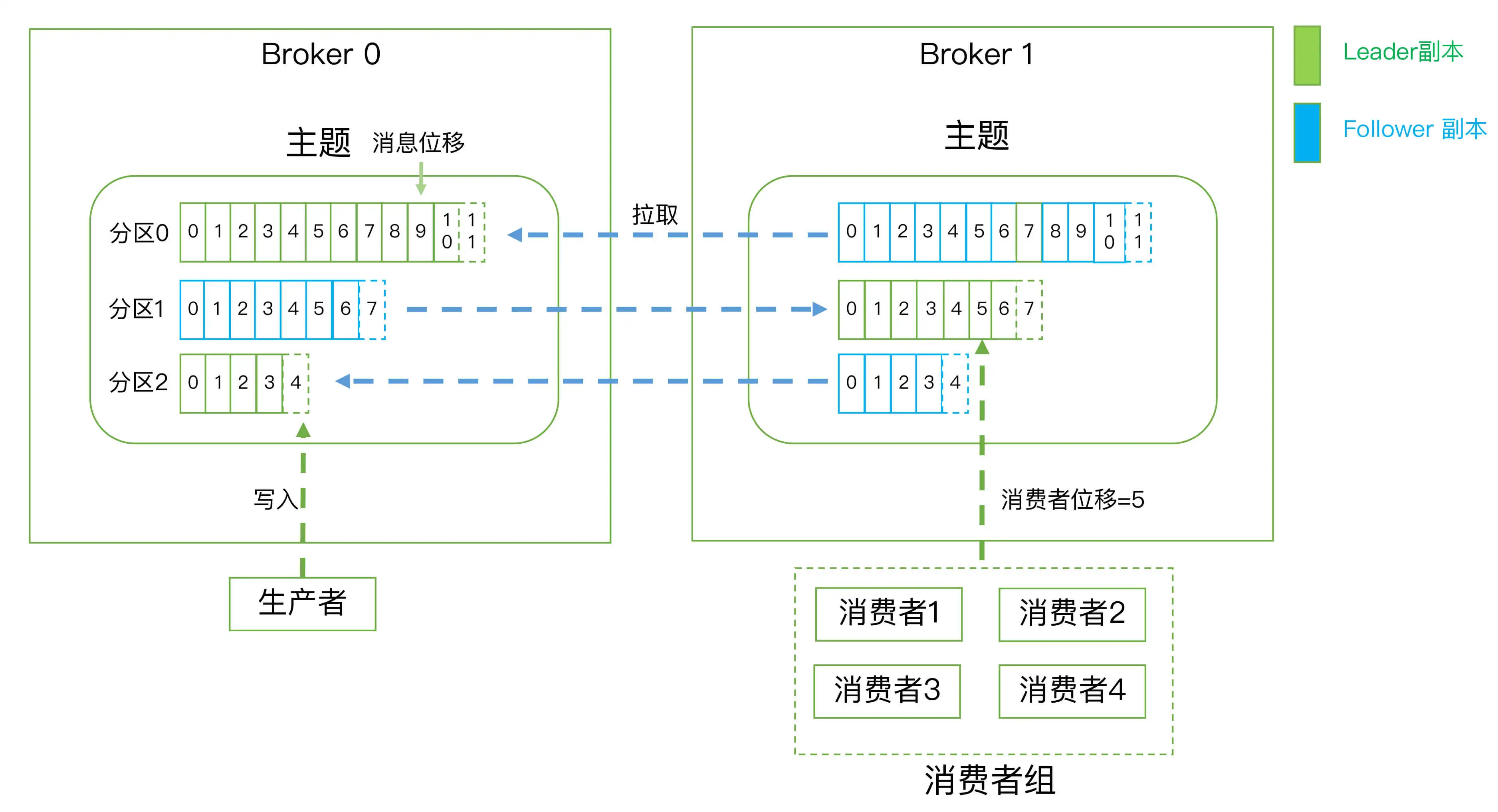
问:kafka 为什么不像 mysql 那样允许 follower 对外提供服务?
- kafka 使用不是典型的读多写少的场景
- 分区 Leader 分布在不同的 Broker 节点, 已提供了负载均衡的功能
第四讲 kafka 发现版本
Apache Kafka
社区版, 迭代速度快,社区响应度高
Confluent Kafka
kafka创始人创建的商业公司Confluent, 为 kafka 提供了很多高级特性, 如跨数据中心备份、集群监控
CDH/HDP Kafka
大数据云公司提供版本,集成在数据平台中
第六讲 线上集群部署
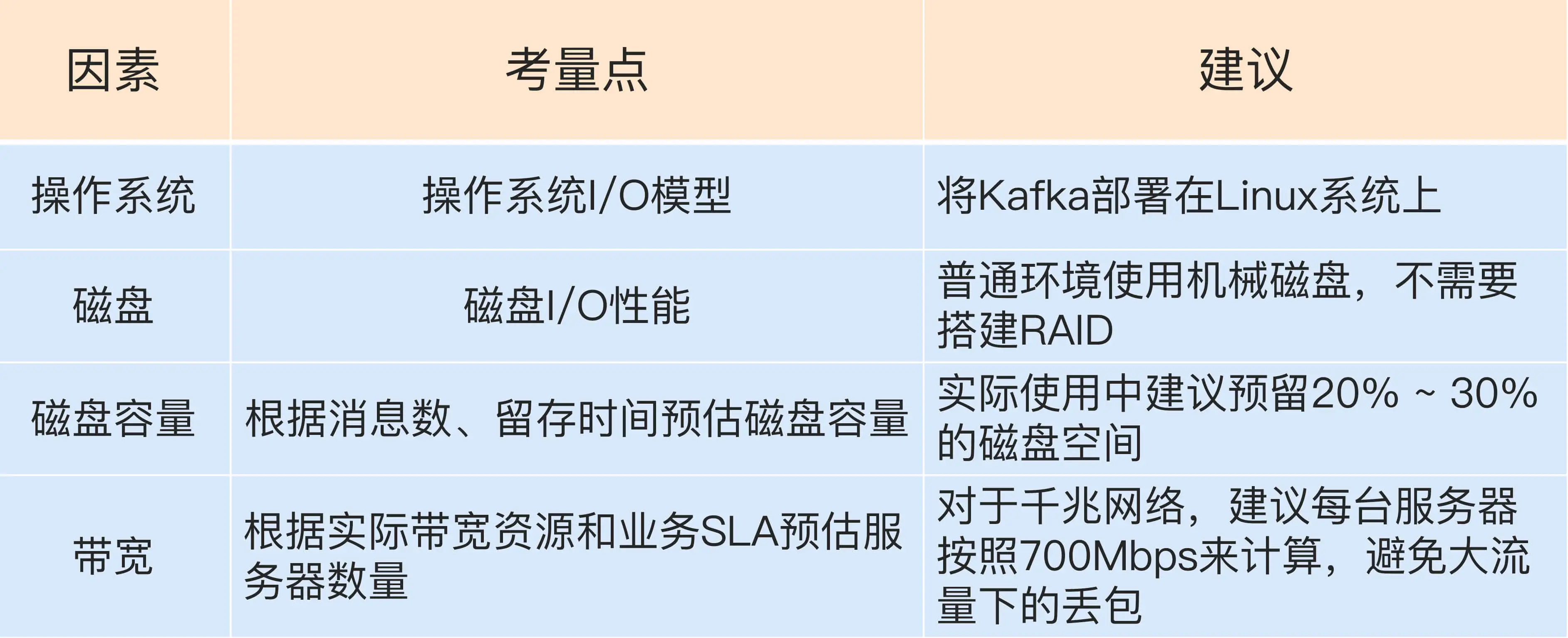
操作系统
kafka 客户端 在 Linux 上使用 epoll I/O 模型, 在 Windows 上使用 select
磁盘
kafka 大多数场景 是顺序读写,使用机械磁盘可以胜任线上坏境
磁盘容量
容量需要考虑如下因素
- 新增消息数
- 平均消息大小
- 消息留存时间
- 备份数
- 是否启用压缩
带宽
根据使用经验,超过 70% 带宽阈值就有网络丢包的可能性,
第七讲 最最最重要集群参数(上)
Broker 参数
存储相关
- log.dirs: 指定目录 如 /home/kafka1,/home/kafka2, 多个目录可以实现故障转移Failover
zookeeper 相关
- zookeeper.connect: zk1:2181,zk2:2181,zk3:2181/kafka1
topic 管理相关
- auto.create.topics.enable: 是否允许自动创建Topic
- unclean.leader.election.enable: 是否运行 Unclean Leader 选举
- auto.leader.rebalance.enable: 是否允许定期举行 Leader 选举
数据留存相关
- log.retention.{hours|minutes|ms}: 控制数据保留时长,默认hours=168
- log.retention.bytes: 消息保存总容量大小,默认不限制
- log.segment.bytes: 日志文件区块大小,默认 1GB (一个 partition 有 多个 segment 文件组成,不会删除最新的一个segment)
- segment.ms: 日志文件毫秒周期,默认 7 天
- message.max.bytes: 最大接受消息大小,默认1000012,976KB
第八讲 最最最重要集群参数(下)
Topic 级别参数
- retention.ms: 消息保存时长,优先于Broker级别设置
- retention.bytes: 消息保存大小,优先于与Broker级别设置
JVM 参数
- KAFKA_HEAP_OPTS: 堆大小, 建议设成 6G
- KAFKA_JVM_PERFORMANCE_OPTS: GC参数
操作系统参数
- 文件描述符限制: 使用 ulimit -n 1000000 改成一个较大值
- 文件系统类型:XFS 性能强于 ext4
- Flush 落盘时间: 默认是 5s,可适当增大来降低物理磁盘的写操作
第九讲 消息分区机制原理
分区作用
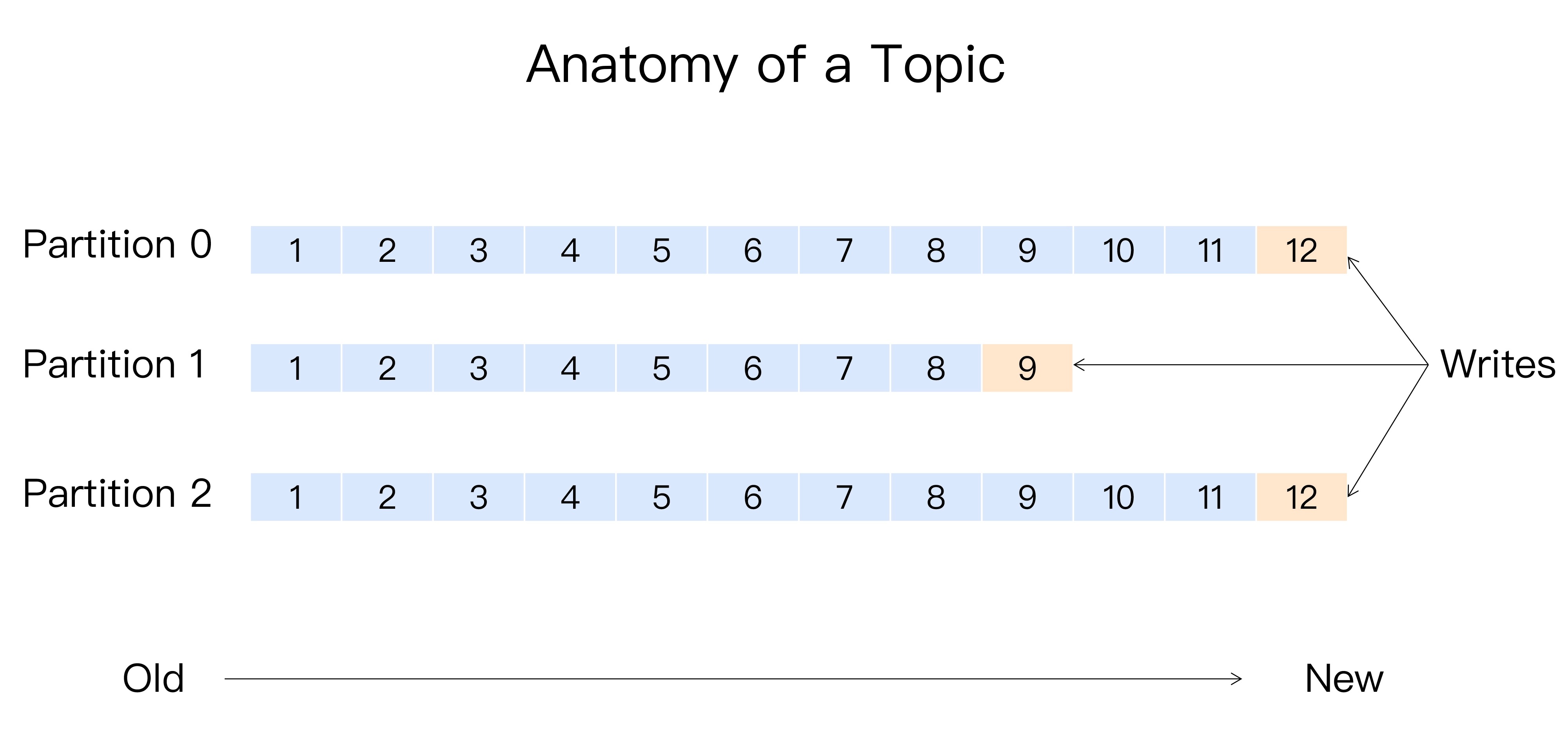 数据的读写操作是针对分区这个粒度进行的
数据的读写操作是针对分区这个粒度进行的
分区的作用就是提供负载均衡的能力,实现系统的高伸缩性
分区写入策略
轮询策略
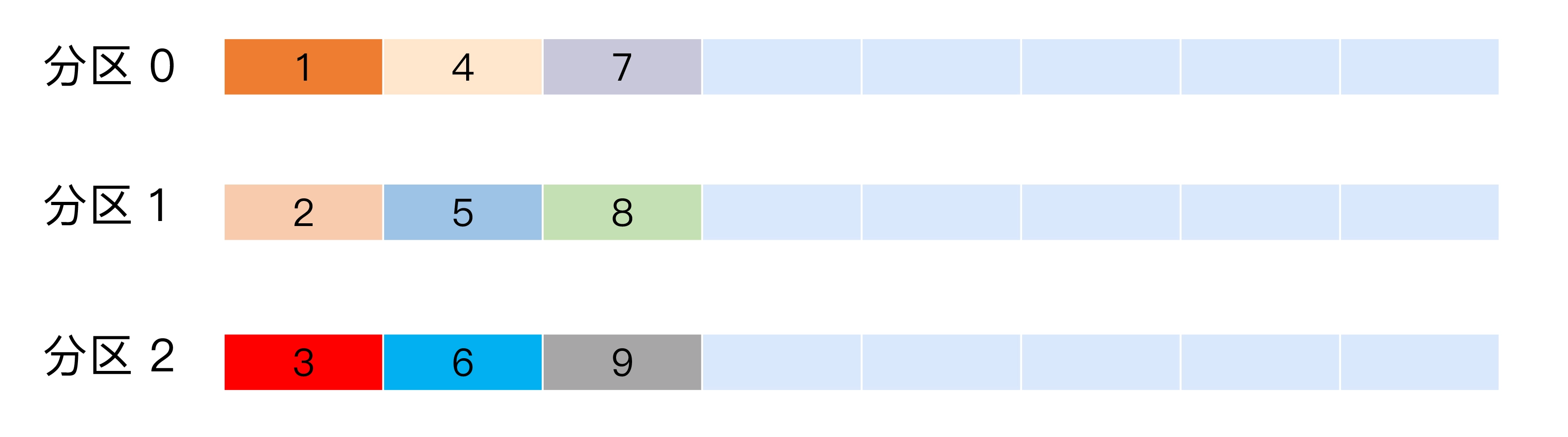
默认策略,将消息平均分配到所有分区
随机策略
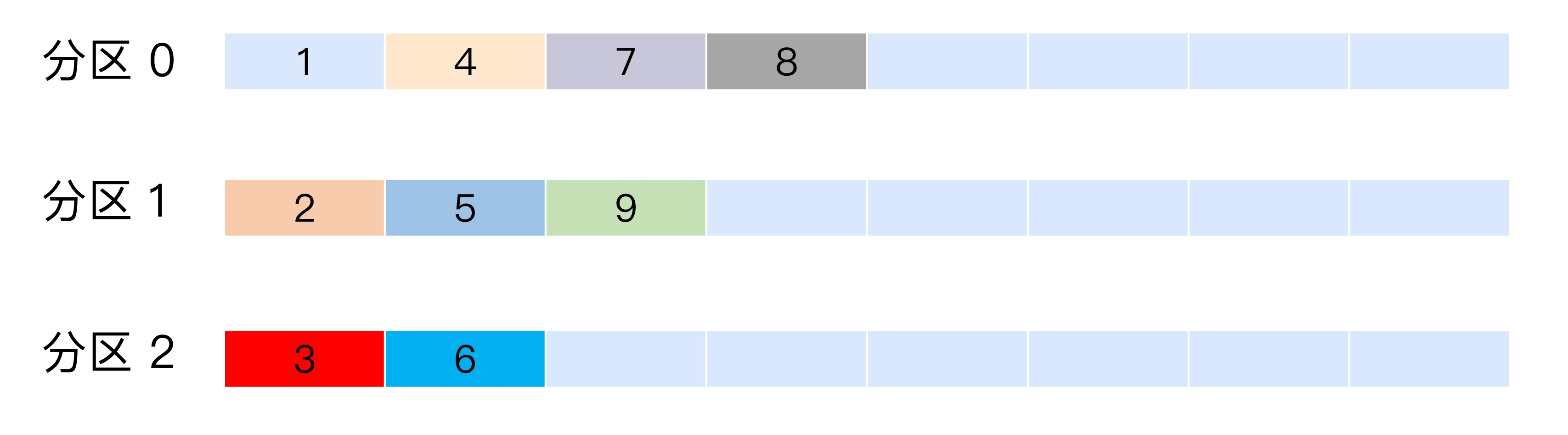
如果追求数据均匀分布, 优先使用轮询策略
按消息键分配策略
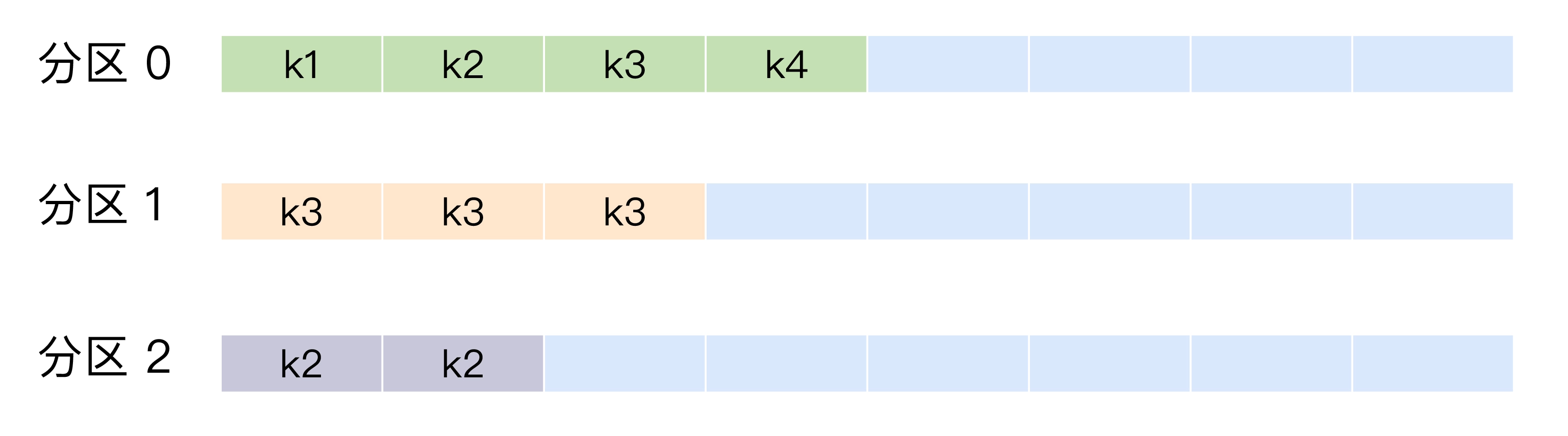
键相同的消息会写入到同一个分区
显式指定分区
kafka-python 可以支持
1
|
producer.send(topic, b'some_message_bytes', partiion=1)
|
kafka-go 需要实现对应接口达到类似效果
1
2
3
4
5
6
7
8
9
10
11
|
type CustomBalancer struct {
kfk.RoundRobin
}
//nolint
func (h *CustomBalancer) Balance(msg kfk.Message, partitions ...int) int {
if msg.Partition == -1 {
return h.RoundRobin.Balance(msg, partitions...)
}
return msg.Partition
}
|
消费者可以显式指定消费分区, 消费者组通过自平衡分配分区
第十讲 压缩算法
流程
Producer 端压缩、Broker 端 保持、Consumer 端解压缩
压缩算法对比
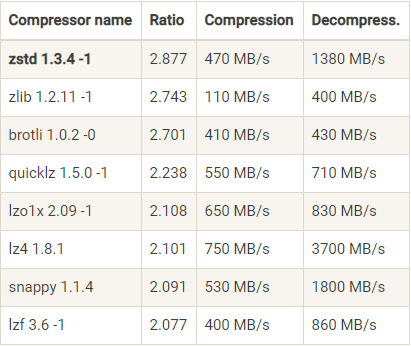
依据情况选择压缩比和吞吐率合适的算法
第十一讲 无消息丢失配置
kafka 只对已提交的消息做有限度的持久化保证
producer端
- 使用带回调的方法: send(msg, callback),
- acks=-1 所有副本收到消息才算已提交
- retries 设置一个较大值,在网络抖动失败时会重试消息发送 (重试可能导致消息乱序,max.in.flight.requests.per.connection=1可以避免)
broker 端
- unclean.leader.election.enable = false 不让落后的broker 参与Leader选举
- replication.factor >= 3 消息多保持几份
- min.insync.replicas > 1 控制消息至少写入到多少分布才算已提交 (只在 acks=-1 是生效)
consumer 端
- enable.auto.commit = false 手动提交维护
第十二讲 拦截器
生产者可以在发送消息前和提交成功后植入拦截器
消费者可以在消费消息前以及提交位移后植入拦截器
第十四讲 幂等和事务
kafka 默认提供的可交付保障是至少一次 at lease once; 通过禁止重试可以实现至多一次 at most once
幂等性 Producer
通过设置 enable.idempotence = true 可以开启
开启以后,单分区单会话能够保证不会出现重复消息
背后的实现逻辑是 Broker 多保存数据,当 Producer 发送了相同字段的消息后,Broker
能够知晓消息重复了,并将其丢弃掉
事务型 Producer
设置 enable.idempotence = true, 以及 transaction.id
1
2
3
4
5
6
7
8
9
|
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(record1);
producer.send(record2);
producer.commitTransaction();
} catch (KafkaException e) {
producer.abortTransaction();
}
|
上面的代码能保证 Record1 和 Record2 要么全部成功,要么全部失败
事务可以保证跨分区、跨会话的幂等性
消费者端设置隔离级别 isolation.level = read_committed 后会只读取成功完成的事务消息
第十五讲 消费者组
特性
- consumer group 可以有一个或多个 consumer
- group id 是 consumer group 的唯一标识
- 单个分区只会分配到一个 consumer
实例数量设置
假设 一个 group 订阅了 3 个 topic, 每个 topic 有 2 个 partition, 那么设置
6 个实例能最大限度的利用kafka的高伸缩性,每个实例消费一个分区
rebalance 触发条件
- 成员数量发生变化,增加或减少
- 订阅主题数量发生变更
- 主题分区数量变更
第十六讲 位移主题
__consumer_offsets 主要用来记录消费者的位移数据
当第一个 consumer 启动时,kafka 会自动创建位移主题,默认分区数 offsets.topic.num.partitions = 50 ,副本数 offsets.topic.replication.factor = 3
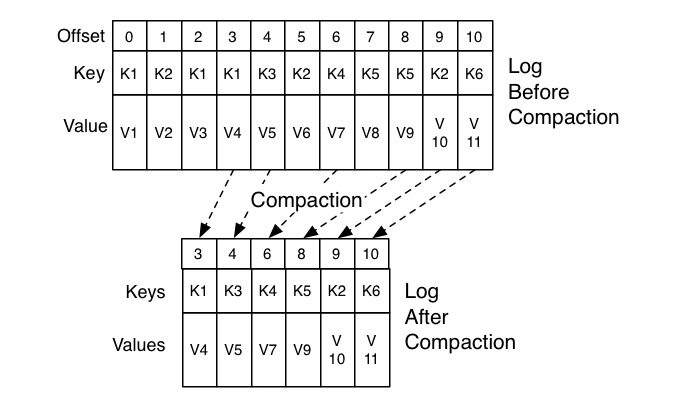
消费端位移提交分为手动和自动提交, 手动提交提供了灵活性和可控性,
而自动提交会定期地提交位移,即使没有新消息,这样会导致位移主题消息会越来越多,所以位移主题采用
log compaction 删除策略来删除重复消息
第十七讲 消费者组重平衡
重平衡就是消费者组中所有消费者就如何订阅主题分区达成共识的过程。
重平衡过程中,所有消费者不消费任何消息,在协调者 coordinator 的帮助下,完成订阅主题分区的分配。
broker 在启动时,会启动相应的 coordinator 组件,消费者组通过位移主题 __consumer_offsets
查找对应 coordinator 所在的 broker
消费者组所在 consumer_offsets 分区通过 abs(hash(group_id) % topic_partition_count) 计算可以得到
如何避免消费者被协调者错误移除?
- session.timeout.ms: 心跳超时时间, 建议设置成 6s
- heartbeat.interval.ms: 心跳间隔,建议设置成 2s (即判定超时前能发送3轮心跳)
- max.pool.interval.ms: 最大 poll 间隔, 根据业务消费时长设定,应大于消费时长
- GC 参数: 频繁 GC 可能导致消费者停顿
第 18 讲 位移提交
自动提交
consumer 后台线程定时提交位移,相关参数
- enable.auto.commit = true (默认开启)
- auto.commit.interval.ms = 5000 (最小提交间隔,默认5s)
假设消费者每 5s 提交一次位移,在第 3s 时发生重平衡,那么前3s的数据会再重复消费一次
手动提交
显式通过调用 cosummer.commitSync() 提交位移
1
2
3
4
5
6
7
8
9
10
|
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
process(records); // 处理消息
try {
consumer.commitSync();
} catch (CommitFailedException e) {
handle(e); // 处理提交失败异常
}
}
|
commitSync 是同步调用, 会阻塞线程,可以使用 commitAsync
1
2
3
4
5
6
7
8
9
|
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
process(records); // 处理消息
consumer.commitAsync((offsets, exception) -> {
if (exception != null)
handle(exception);
});
}
|
可以将两者结合,利用 commitSync 的重试规避瞬时错误,利用 commitAsync 来减少阻塞
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
try {
while(true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
process(records); // 处理消息
commitAysnc(); // 使用异步提交规避阻塞
}
} catch(Exception e) {
handle(e); // 处理异常
} finally {
try {
consumer.commitSync(); // 最后一次提交使用同步阻塞式提交
} finally {
consumer.close();
}
}
|
第二十一讲 Java 版消费者 TCP 连接管理
TCP 连接是在调用 KafkaConsumer.poll 方法被创建的。
poll 内部有三个时机可以创建 TCP 连接
创建连接时机
- 发起 FindCoordinator 请求时
消费者启动时会向负载最小的 Broker 建立连接,请求告知主题对应的 coordinator Leader 在哪个 broker
- 连接协调者
步骤 1 之后会和 coordinator 建立连接
- 消费数据时
消费者会向每个分区 Leader 所在的 Broker 建立连接。
假设消费的 5 个分区在 4 个 Broker 上,那会建立 4 个连接。
案例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# 建立第一个连接,连接的Broker的 ID 是 -1, 表明还不知道其任何信息
[2019-05-27 10:00:54,142] DEBUG [Consumer clientId=consumer-1, groupId=test] Initiating connection to node localhost:9092 (id: -1 rack: null) using address localhost/127.0.0.1 (org.apache.kafka.clients.NetworkClient:944)
# 向第一个连接请求集群元数据信息
[2019-05-27 10:00:54,188] DEBUG [Consumer clientId=consumer-1, groupId=test] Sending metadata request MetadataRequestData(topics=[MetadataRequestTopic(name='t4')], allowAutoTopicCreation=true, includeClusterAuthorizedOperations=false, includeTopicAuthorizedOperations=false) to node localhost:9092 (id: -1 rack: null) (org.apache.kafka.clients.NetworkClient:1097)
# 向第一个连接发送 FindCoordinator 请求
[2019-05-27 10:00:54,188] TRACE [Consumer clientId=consumer-1, groupId=test] Sending FIND_COORDINATOR {key=test,key_type=0} with correlation id 0 to node -1 (org.apache.kafka.clients.NetworkClient:496)
# 收到 Coordinator 所在 Broker 信息
[2019-05-27 10:00:54,203] TRACE [Consumer clientId=consumer-1, groupId=test] Completed receive from node -1 for FIND_COORDINATOR with correlation id 0, received {throttle_time_ms=0,error_code=0,error_message=null, node_id=2,host=localhost,port=9094} (org.apache.kafka.clients.NetworkClient:837)
# 和 Coordinator 建立第二个连接
[2019-05-27 10:00:54,204] DEBUG [Consumer clientId=consumer-1, groupId=test] Initiating connection to node localhost:9094 (id: 2147483645 rack: null) using address localhost/127.0.0.1 (org.apache.kafka.clients.NetworkClient:944)
# 建立第三到五个连接,用于实际消息的获取,说明这三个 Broker 都有要消费的分区
[2019-05-27 10:00:54,237] DEBUG [Consumer clientId=consumer-1, groupId=test] Initiating connection to node localhost:9094 (id: 2 rack: null) using address localhost/127.0.0.1 (org.apache.kafka.clients.NetworkClient:944)
[2019-05-27 10:00:54,237] DEBUG [Consumer clientId=consumer-1, groupId=test] Initiating connection to node localhost:9092 (id: 0 rack: null) using address localhost/127.0.0.1 (org.apache.kafka.clients.NetworkClient:944)
[2019-05-27 10:00:54,238] DEBUG [Consumer clientId=consumer-1, groupId=test] Initiating connection to node localhost:9093 (id: 1 rack: null) using address localhost/127.0.0.1 (org.apache.kafka.clients.NetworkClient:944)
|
总结上面的日志信息,可以看出消费者通常会创建三类连接:
- 确认协调者和获取集群元数据
- 连接协调者,令其执行组成员管理操作
- 执行实际消息的获取
当第三类连接建立后,第一类连接会被关闭,定期请求元数据的需求切换到第三类连接上。
问: 第三类连接是主题级别还是 Broker 级别 ?
第二十二讲 消费者组消费进度监控
消息滞后使用 Consumer Lag 衡量,假设当前生成了 20 万条消息,消费了 15 万条,那么
Consumer Lag 就等于 5 万。
使用命令行工具
1
|
$ bin/kafka-consumer-groups.sh --bootstrap-server <Kafka broker连接信息> --describe --group <group名称>
|

使用 Java Consumer API
使用 AdminClient 查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
public static Map<TopicPartition, Long> lagOf(String groupID, String bootstrapServers) throws TimeoutException {
Properties props = new Properties();
props.put(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
try (AdminClient client = AdminClient.create(props)) {
ListConsumerGroupOffsetsResult result = client.listConsumerGroupOffsets(groupID);
try {
Map<TopicPartition, OffsetAndMetadata> consumedOffsets = result.partitionsToOffsetAndMetadata().get(10, TimeUnit.SECONDS);
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); // 禁止自动提交位移
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupID);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
try (final KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {
Map<TopicPartition, Long> endOffsets = consumer.endOffsets(consumedOffsets.keySet());
return endOffsets.entrySet().stream().collect(Collectors.toMap(entry -> entry.getKey(),
entry -> entry.getValue() - consumedOffsets.get(entry.getKey()).offset()));
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
// 处理中断异常
// ...
return Collections.emptyMap();
} catch (ExecutionException e) {
// 处理ExecutionException
// ...
return Collections.emptyMap();
} catch (TimeoutException e) {
throw new TimeoutException("Timed out when getting lag for consumer group " + groupID);
}
}
}
|
使用JMX 监控指标
使用 JMX 指标集成到 Grafana 等监控框架中
kafka 消费者 提供了名为 kafka.consumer:type=consumer-fetch-manager-metrics,client-id=“{client-id}” 指标
其中有两个指标和消费进度有关:
- records-lag-max
- records-lead-min: 消费者位移和分区最旧消息的最小差值
第二十三讲 副本机制
副本定义
副本本质上是一个只能追加写消息的提交日志。
这些副本分散保存在不同的 Broker 上, 从而能够对抗 Broker 宕机带来的数据不可用。
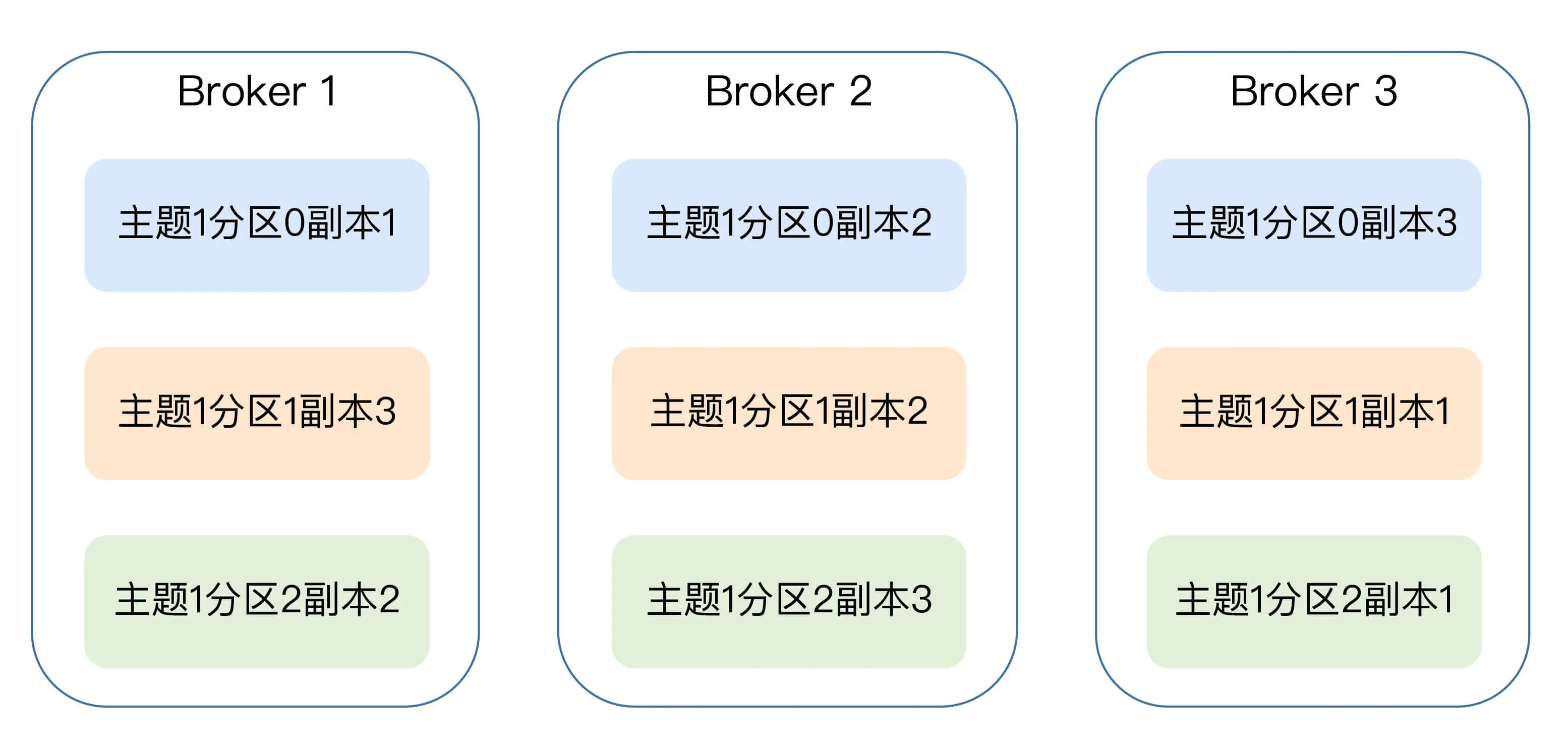
副本角色
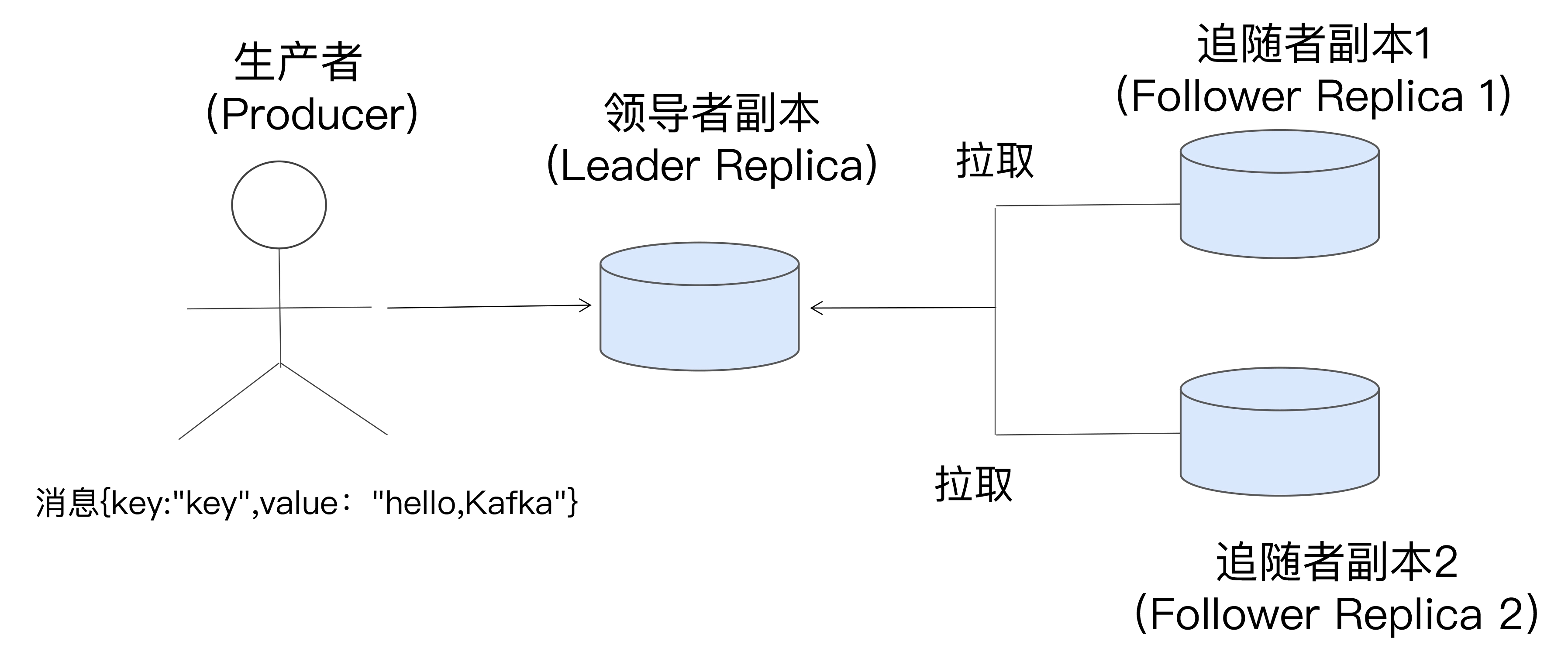
副本分为两类,Leader 和 Follower, 分区在创建时会选出一个 Leader 副本, 其余副本成为 Follower。
所有的读写请求都由 Leader 处理,Follower 只是从 Leader 异步拉取消息从而实现同步
当 Leader 挂掉后,ZooKeeper 能够监控到并开启新一轮的选举
Follower 不对外提供服务的好处:
- 方便实现 Read-your-writes 。如果从 Follower 读取消息,由于是异步的,可能看不到最新的消息
- 方便实现单调读 Monotonic Reads 。如果从多个副本读消息,可能出现某条消息一会存在一会不存在
In-sync Replicas (ISR)
ISR 指与 Leader 同步的副本集合, Leader 本身也包括在 ISR 中
通过 replica.lag.time.max.ms 参数指定 Follower 能够落后 Leader 的最长时间,
在此范围内的 Follower 都在 ISR 中。
Unclean 领导者选举
当 ISR 为空时,只存在非同步副本。
unclean.leader.election.enable 参数控制是否允许 Unclean 领导者选举
开启的好处是使得 Leader 副本一直存在,提高可用性,但是可能会造成数据丢失,不建议开启。
第二十四讲 请求处理过程
kafka 定义了一组请求协议,用于实现各种交互操作,PRODUCE
请求用于生产消息,FETCH请求用于消费消息,METADATA请求用于获取集群元数据
数据类请求
kafka 使用 Reactor 模式处理请求
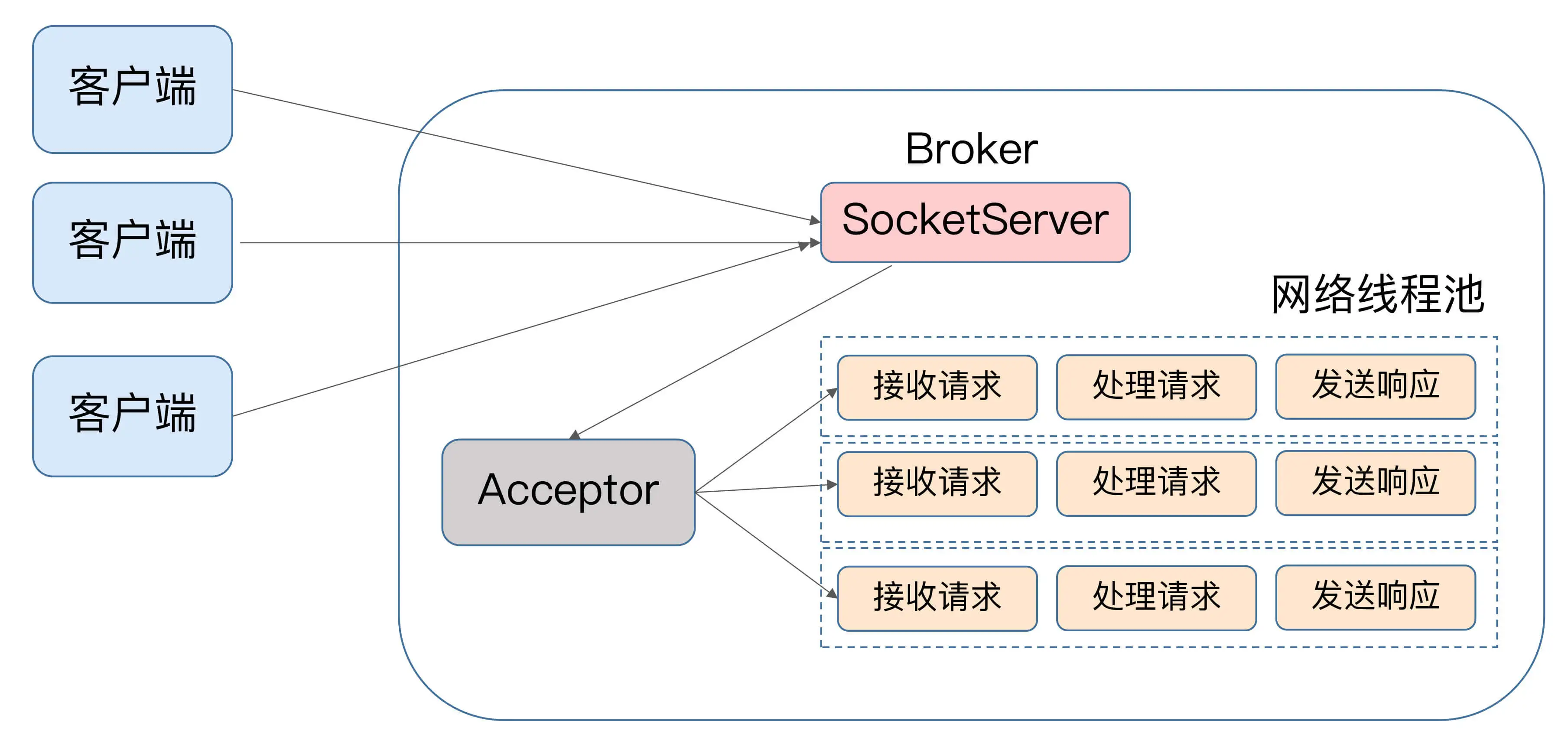
Acceptor 线程用于分发请求,分发使用轮询模式
网络线程池来处理具体的请求,num.network.threads 参数控制线程数量,默认为3。
网络线程拿到请求后,将请求放入一个共享队列中,IO 线程池负责从队列中
取出请求,执行真正的处理。如果是 PRODUCE 请求,则将消息写入磁盘日志;
如果是 FETCH 请求,则从磁盘或页缓存中读取消息。
IO 线程处理完请求后, 会将响应发送到网络线程池的响应队列中,然后由
对应的网络线程将响应返回给客户端。
num.io.threads 参数控制 IO 线程数量,默认为8。
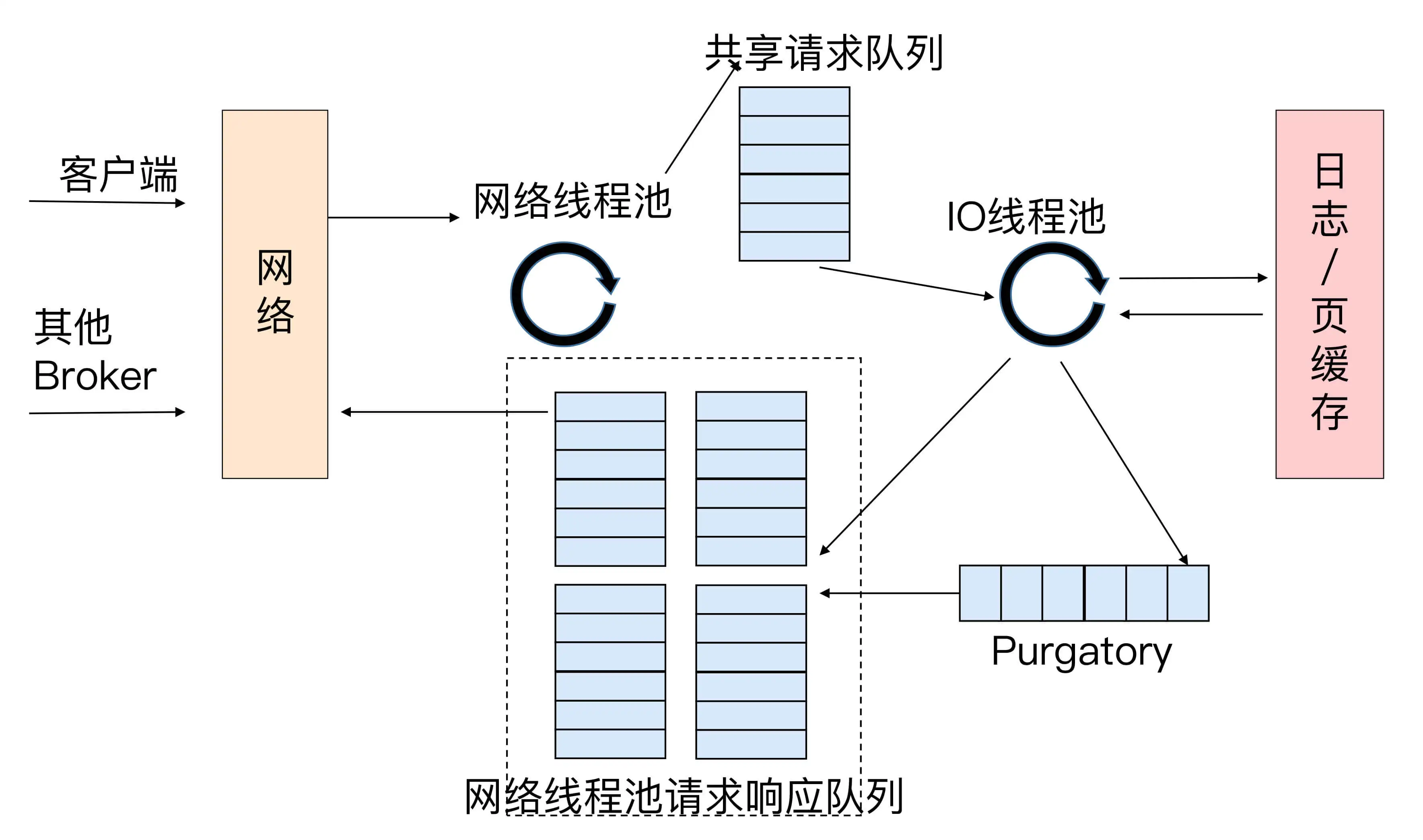
Purgatory 组件用来缓存延时请求。比如设置了 ack=all 的 PRODUCE 请求,
需要等待所有 ISR 副本接收后才能返回。
控制类请求
控制类请求用来执行特定的 kafka 内部动作,比如负责更新 Leader/Follower/ISR 的
LeaderAndIsr 请求、负责勒令副本下线的 StopReplica 请求。
kafka 将 控制类请求和数据类请求分类,分别创建了两套网络线程池和 IO 线程池
第二十五讲 重平衡过程
通知触发
重平衡通知是通过心跳来通知的, 协调者会将REBALANCE_IN_PROCESS包含在心跳响应中。
消费者组状态机
kafka 为消费者组定义了五种状态
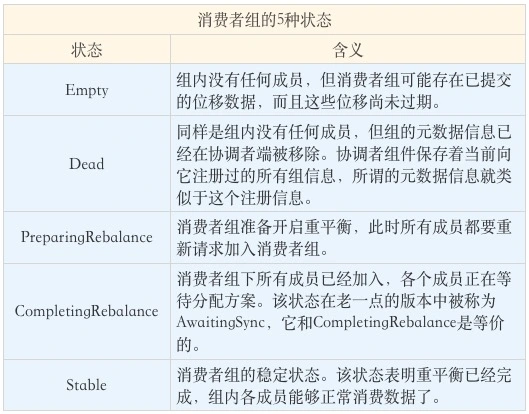
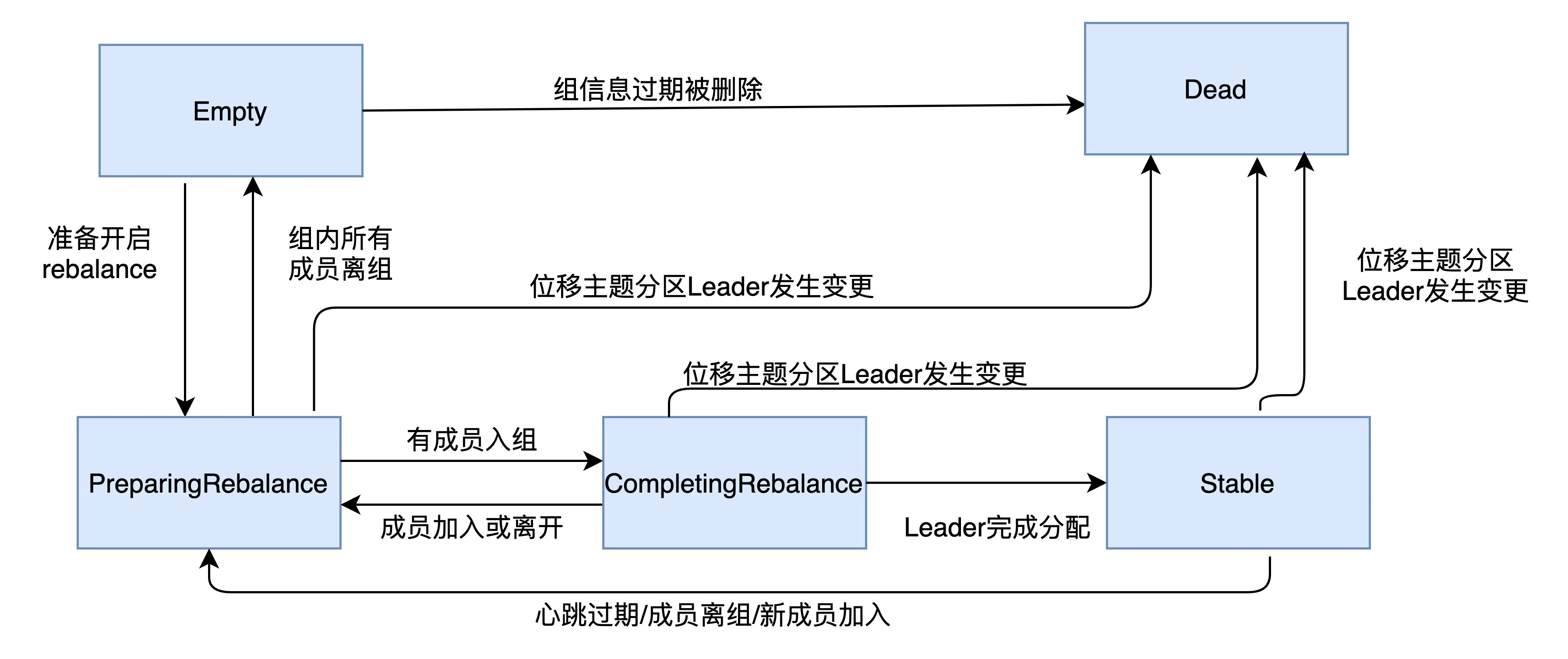
状态机状态流转如下
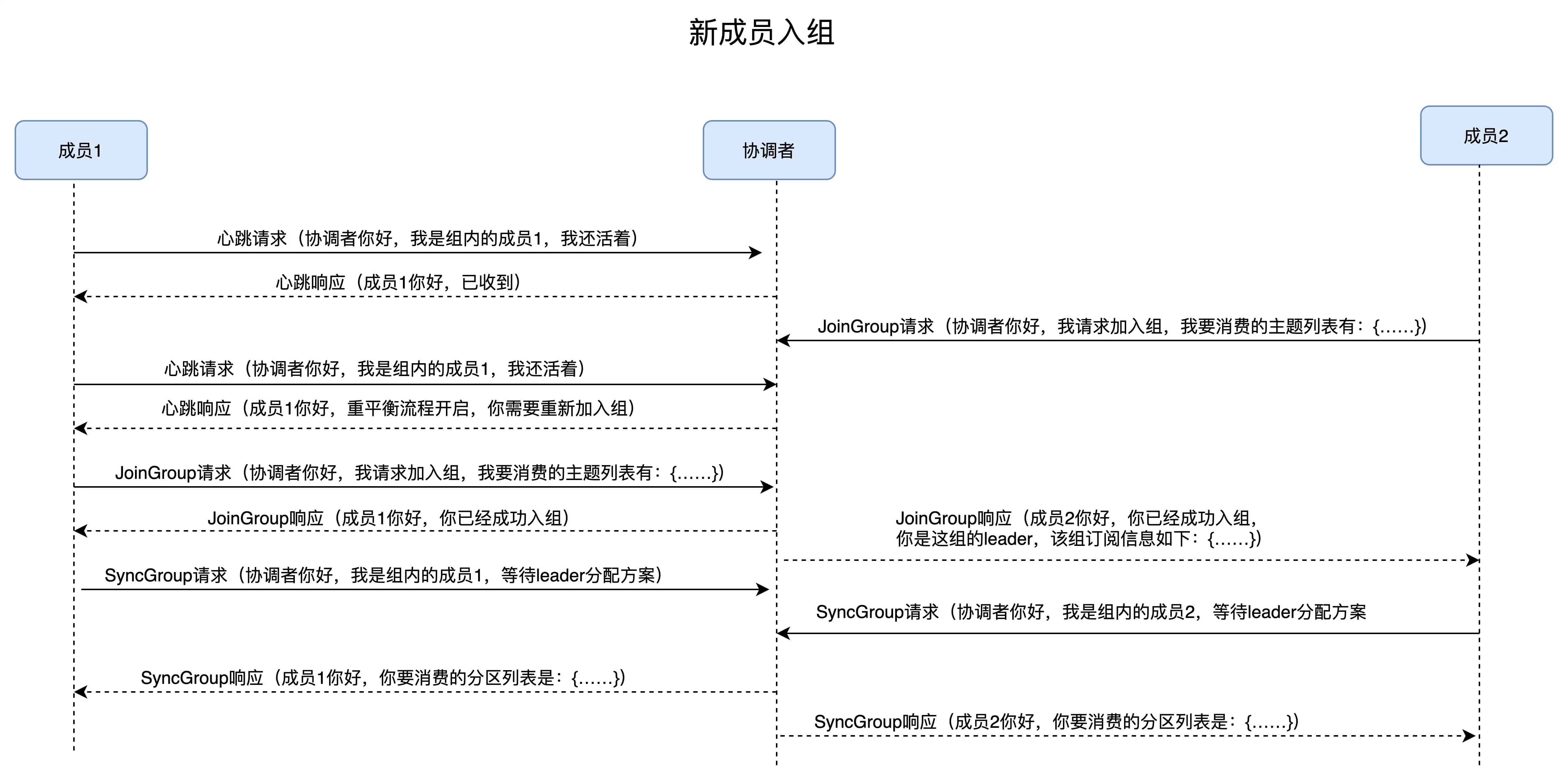
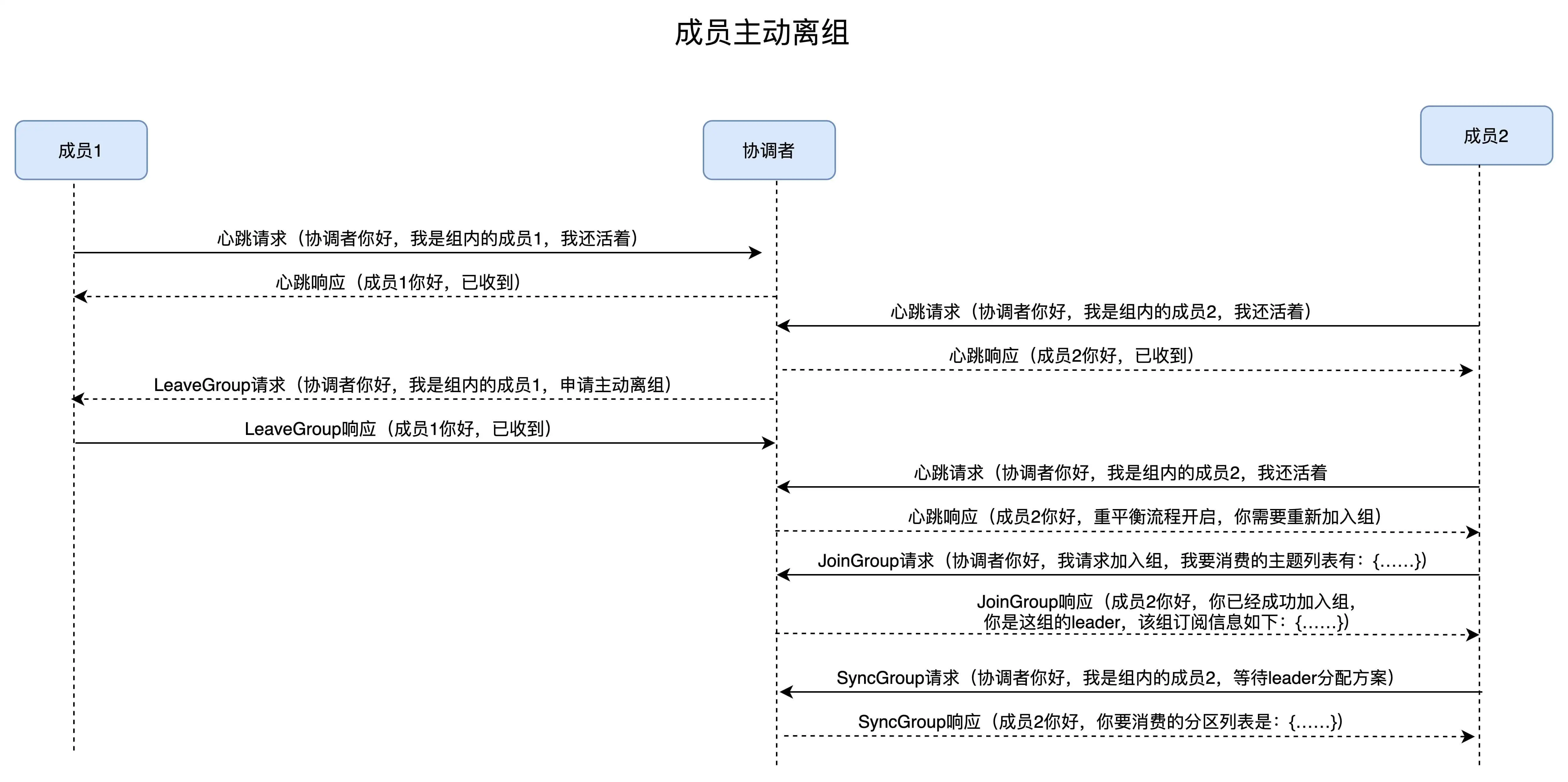
消费者端流程
在消费者端,重平衡分为两个步骤:加入组和等待领导者消费者分配方案。这两个步骤
分别对应两类特定的请求:JoinGroup 和 SyncGroup。
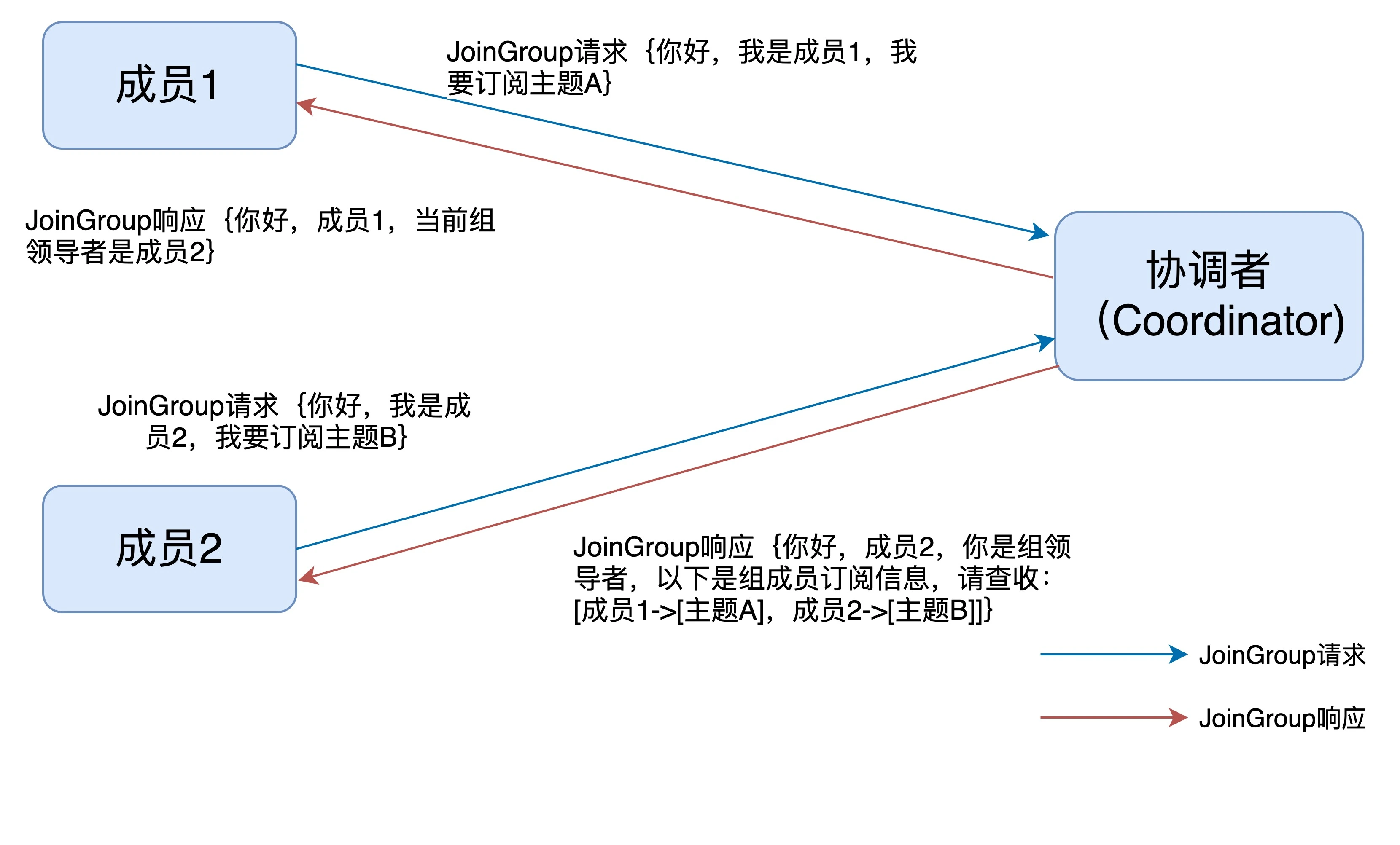
在收到所有消费者的订阅消息后,消费者通常将第一个发送 JoinGroup 消息的成员
当做领导者,并将所有订阅信息发给领导者。领导者做出方案后,会发送 SyncGroup
请求,将方案发给协调者。其他成员也会发送空的 SyncGroup 请求。
协调者会将分配方案在 SyncAGroup 响应中发送。
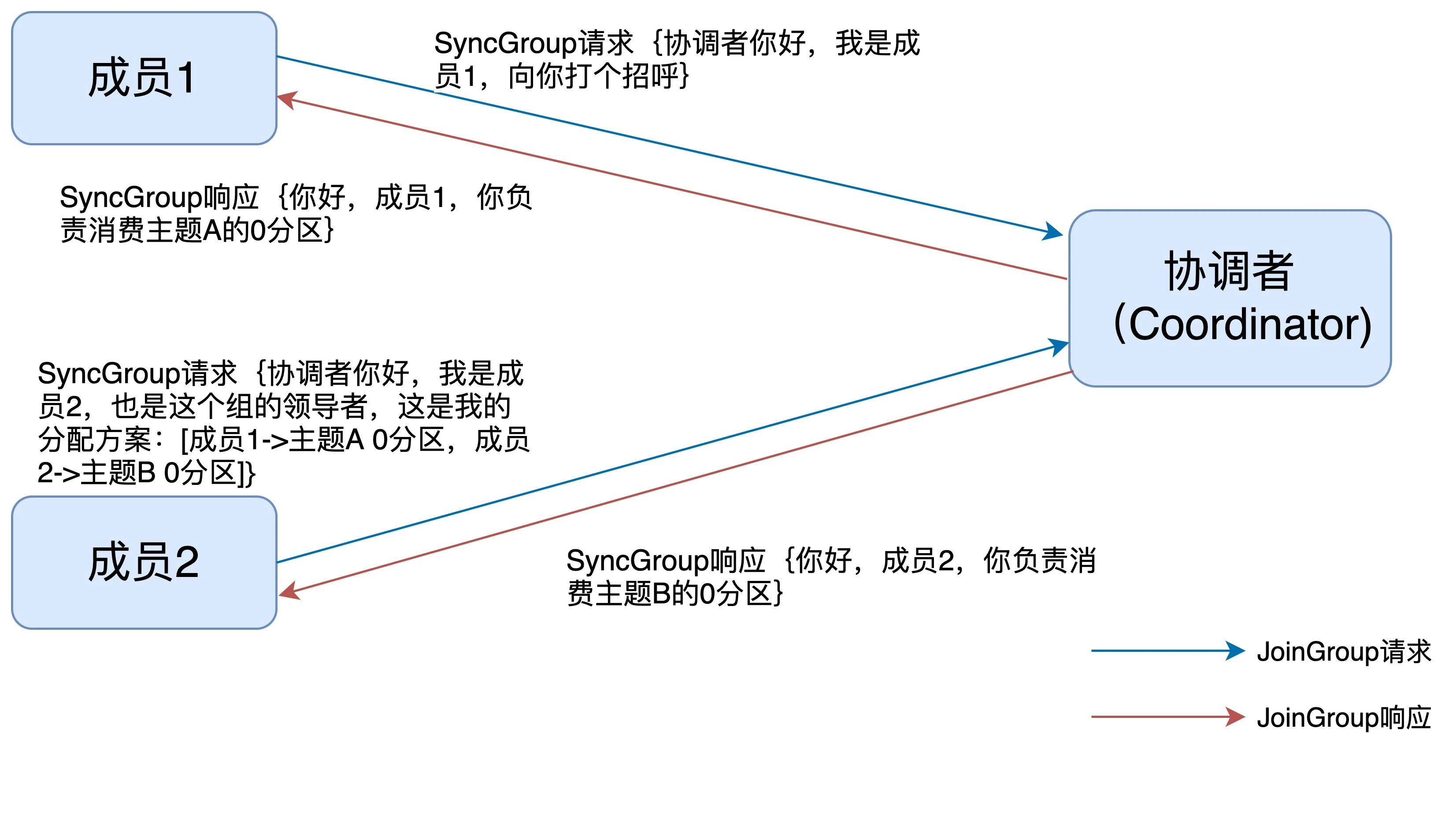
协调者端流程
新成员入组
成员主动离组
主动离组会发起 LeaveGroup
成员崩溃
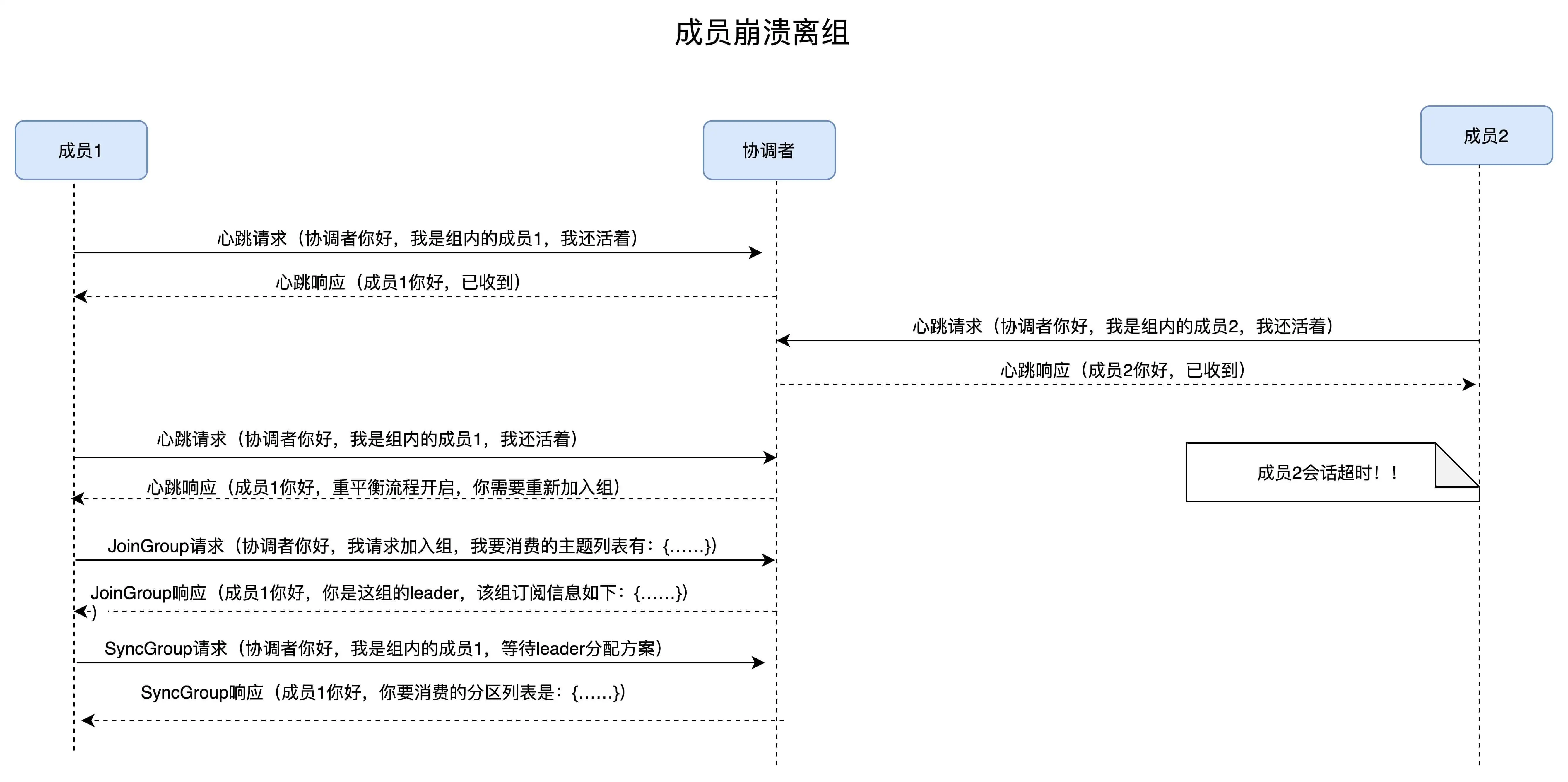
重平衡开始后,协调者会给予成员一段缓冲时间 rebalance.timeout,要求成员必须在 这段时间快速上报自己的位移消息。
第二十七讲 高水位 和 Leader Epoch
什么是高水位
《Streaming System》 表述: 水位是一个单调增加且表征最早未完成工作(
oldest work not yet completed)的时间戳
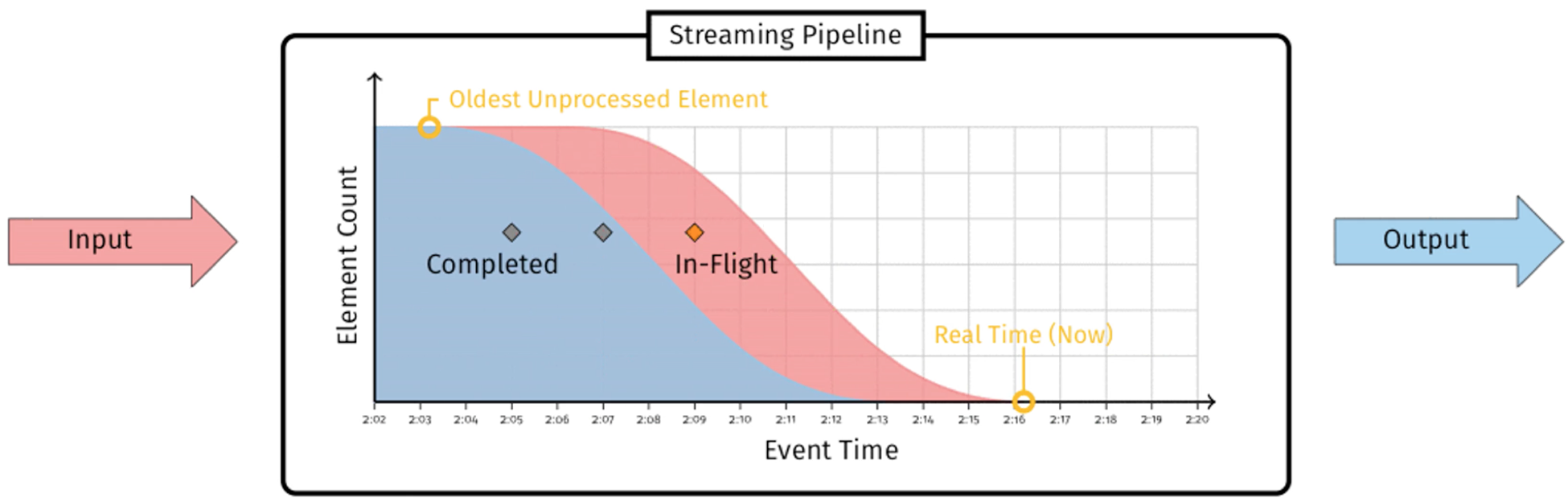
高水位的作用
- 定义消息可见性,即标识哪些消息可以被消费者消费
- 帮助kafka 完成副本同步。
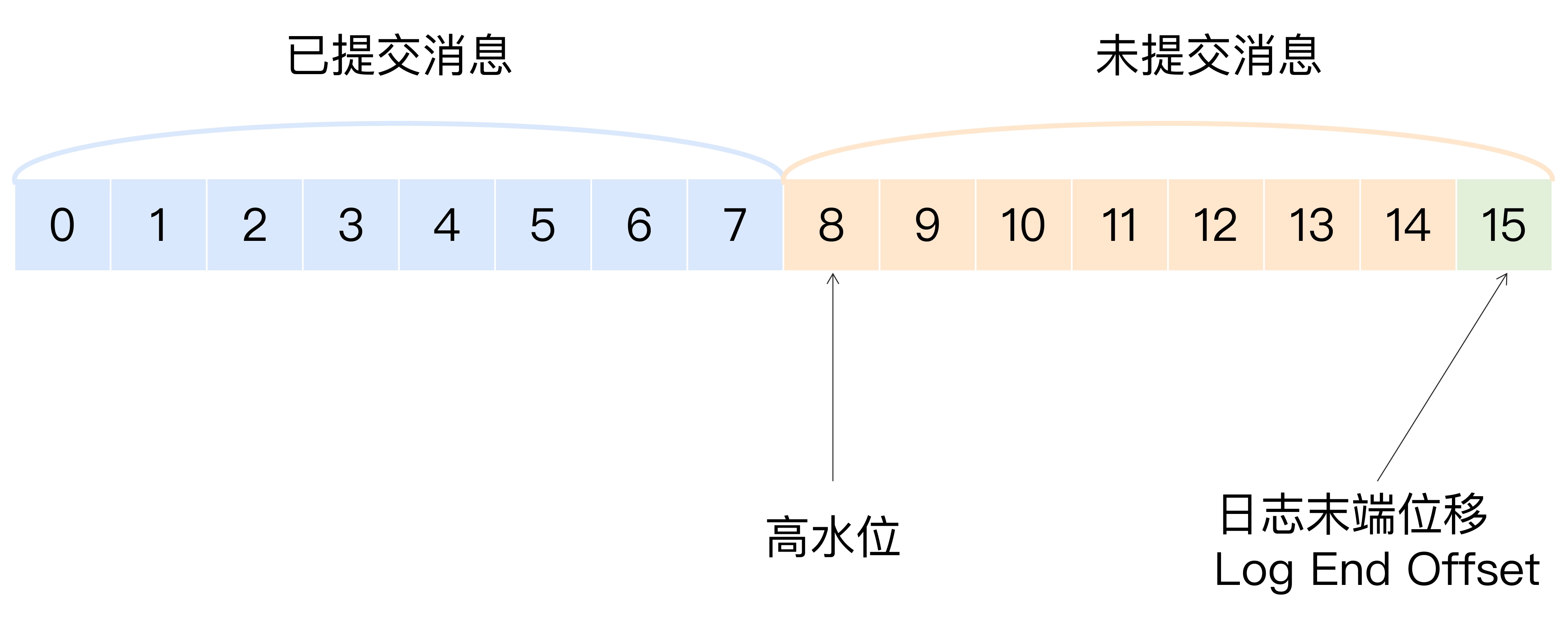
位移值等于高水位的消息也属于未提交的消息。
同一个副本对象,其高水位值小于等于 LEO 值
高水位更新机制
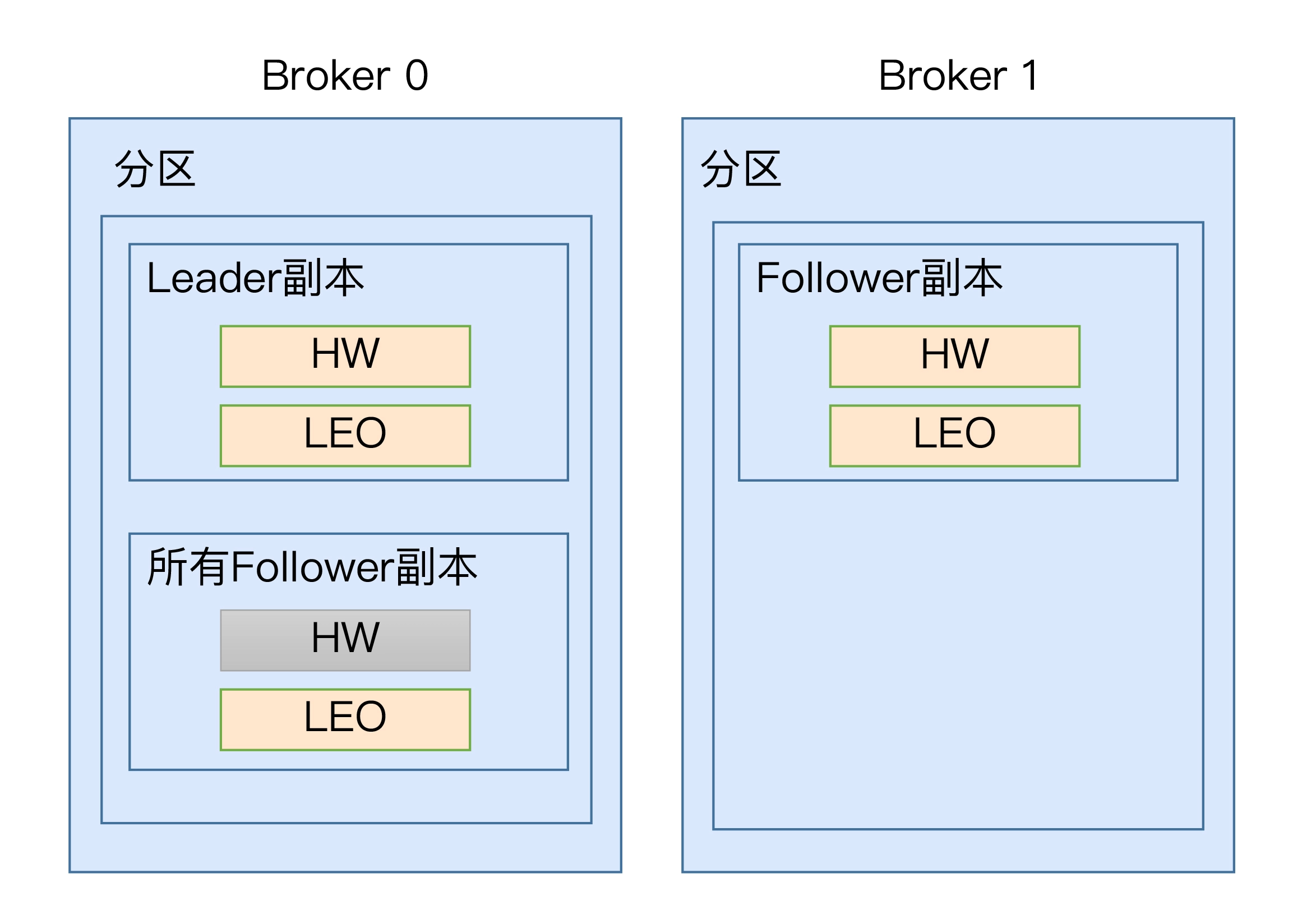
leader 副本 会保存 所有 follower 副本的 LEO 值,其作用是帮助 leader
副本确认其高水位,即整个分区高水位。
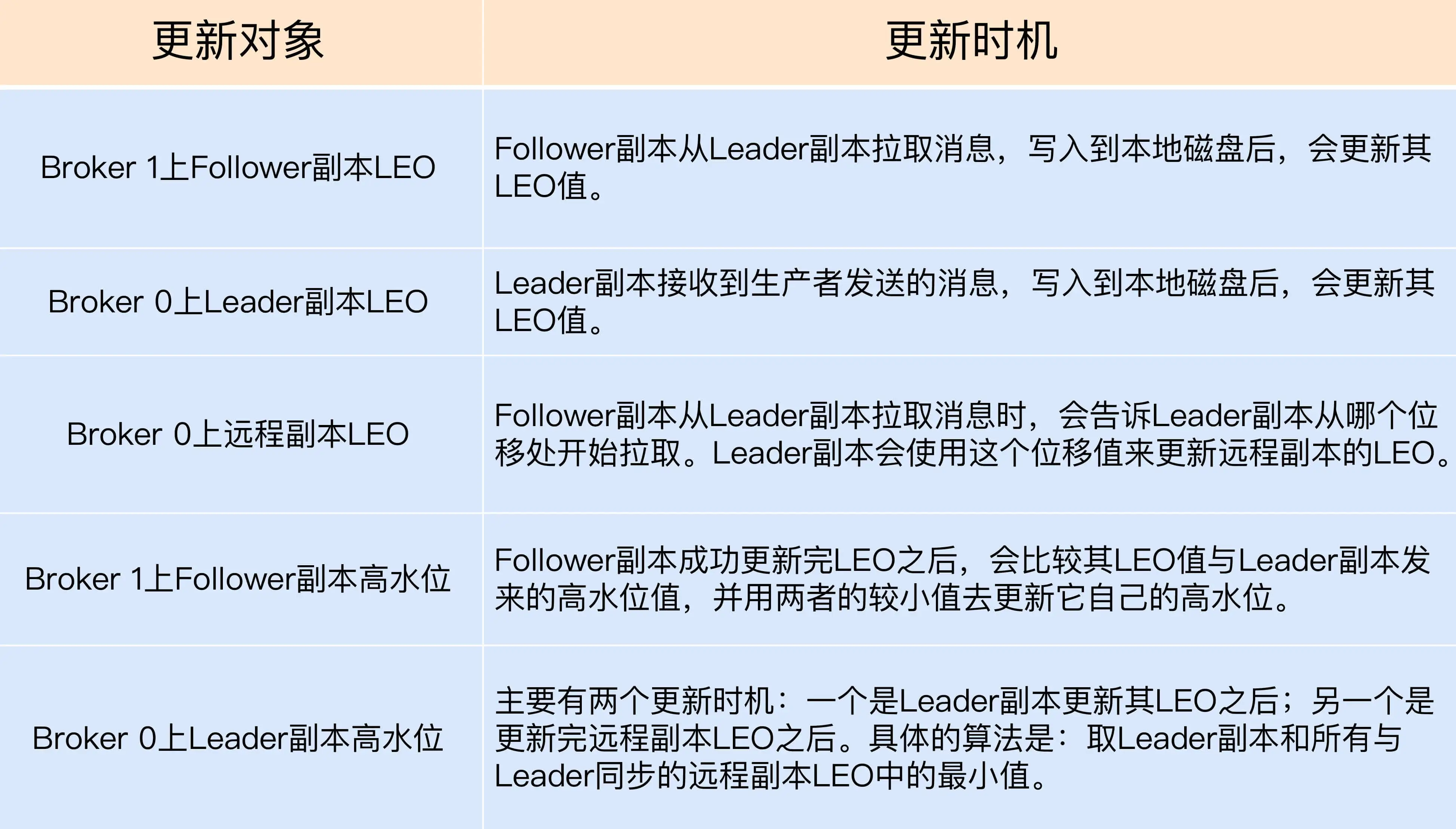
leader副本
处理生产者请求:
- 写入消息到本地磁盘
- 更新分区高水位值: 获取保存的所有 远程副本 LEO 值,
currentHW = max(crrentHW, min(LEO-1, …, LEO-n))
处理 follower 副本拉取消息逻辑
- 读取磁盘中的消息数据
- 使用 follower 副本发送请求中 的位移值更新远程 副本的 LEO 值
- 更新分区高水位值
follower副本
- 写入消息到本地磁盘
- 更新 LEO 值 currentLEO
- 更新高水位值: 获取leader 发送的高水位值 currentHW, 更新高水位为
min(currentHW, currentLEO)
第二十八讲 主题管理
创建主题
1
|
bin/kafka-topics.sh --bootstrap-server broker_host:port --create --topic my_topic_name --partitions 1 --replication-factor 1
|
查询主题列表
1
|
bin/kafka-topics.sh --bootstrap-server broker_host:port --list
|
查询单个主题详情
1
|
bin/kafka-topics.sh --bootstrap-server broker_host:port --describe --topic <topic_name>
|
修改(增加)主题分区
1
|
bin/kafka-topics.sh --bootstrap-server broker_host:port --alter --topic <topic_name> --partitions <新分区数>
|
修改主题单条消息最大字节数
1
|
bin/kafka-configs.sh --zookeeper zookeeper_host:port --entity-type topics --entity-name <topic_name> --alter --add-config max.message.bytes=10485760
|
修改主题带宽限速
1
2
3
|
bin/kafka-configs.sh --zookeeper zookeeper_host:port --alter --add-config 'leader.replication.throttled.rate=104857600,follower.replication.throttled.rate=104857600' --entity-type brokers --entity-name 0
bin/kafka-configs.sh --zookeeper zookeeper_host:port --alter --add-config 'leader.replication.throttled.replicas=*,follower.replication.throttled.replicas=*' --entity-type topics --entity-name test
|
删除主题
1
|
bin/kafka-topics.sh --bootstrap-server broker_host:port --delete --topic <topic_name>
|
第二十九讲 动态配置
broker config 有三类参数
- read-only: 重启 broker 才会生效
- per-broker: 对应 broker 生效
- cluster-wide: 整个集群生效
常用动态参数
- log.retention.ms
修改日志留存时间
- num.io.threads 和 num.network.threads
修改 IO 和网络线程数量
- num.replica.fetchers
修改 follower 拉取数据的线程数量
第三十讲 重设消费者组位移
策略类型
kafka 支持 7 种策略
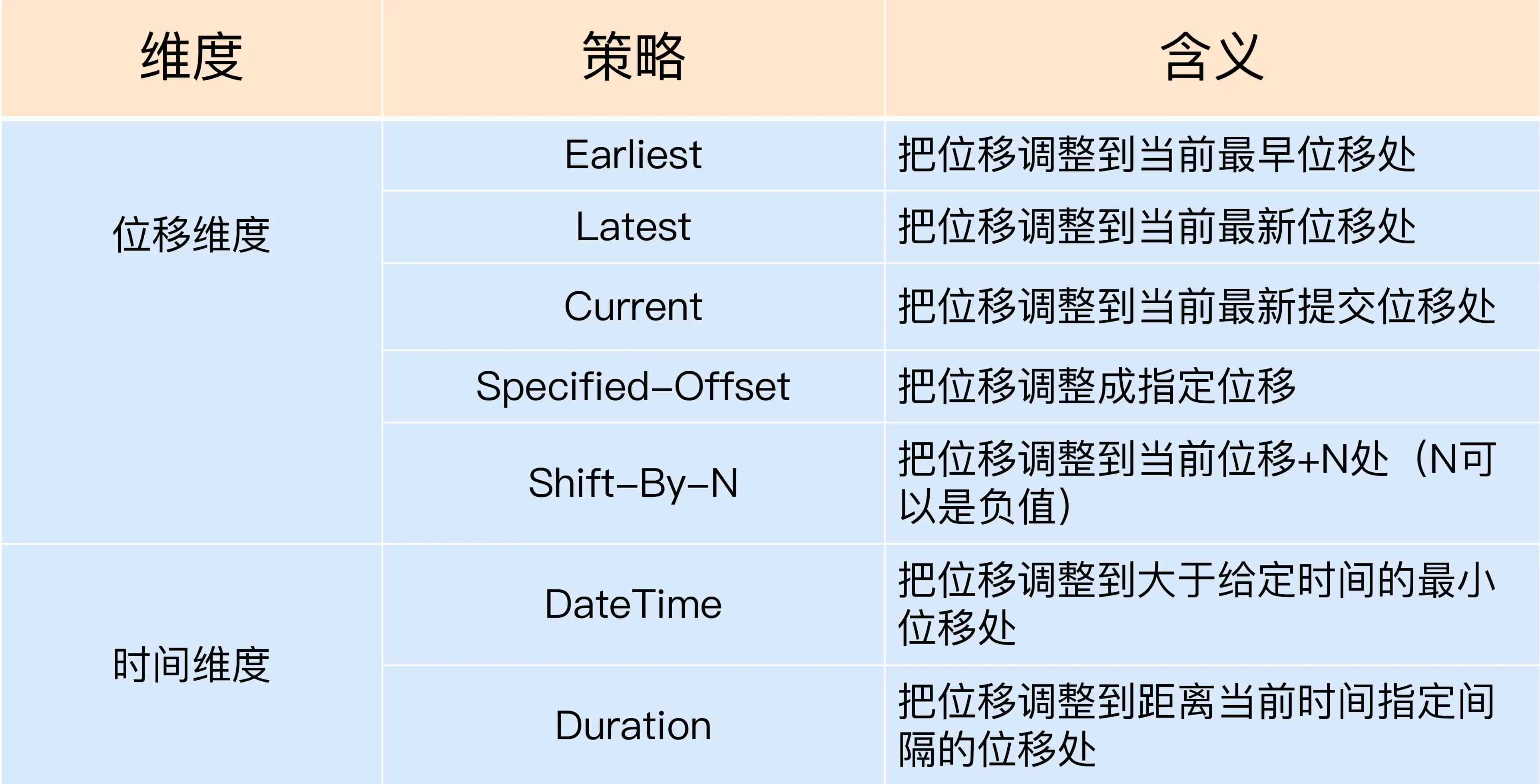
命令行设置
Earliest
1
|
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --all-topics --to-earliest –execute
|
Latest
1
|
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --all-topics --to-latest --execute
|
Current
1
|
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --all-topics --to-current --execute
|
Specified-Offset
1
|
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --all-topics --to-offset <offset> --execute
|
Shift-By-N
1
|
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --shift-by <offset_N> --execute
|
Datetime
1
|
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --to-datetime 2019-06-20T20:00:00.000 --execute
|
Duration
1
|
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --by-duration PT0H30M0S --execute
|
第三十一讲 常见脚本汇总
kafka-dump-log 查看 kafka 消息文件的内容,包括消息的各种元数据信息和消息本身
kafka-log-dirs 查看各个 Broker 磁盘占用情况
重点操作
生成消息
1
2
|
$ bin/kafka-console-producer.sh --broker-list kafka-host:port --topic test-topic --request-required-acks -1 --producer-property compression.type=lz4
>
|
消费消息
1
|
$ bin/kafka-console-consumer.sh --bootstrap-server kafka-host:port --topic test-topic --group test-group --from-beginning --consumer-property enable.auto.commit=false
|
查看文件
1
2
3
4
5
6
7
|
$ bin/kafka-dump-log.sh --files ../data_dir/kafka_1/test-topic-1/00000000000000000000.log
Dumping ../data_dir/kafka_1/test-topic-1/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 14 count: 15 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1561597044933 size: 1237 magic: 2 compresscodec: LZ4 crc: 646766737 isvalid: true
baseOffset: 15 lastOffset: 29 count: 15 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 1237 CreateTime: 1561597044934 size: 1237 magic: 2 compresscodec: LZ4 crc: 3751986433 isvalid: true
......
|
相关链接
kafka管理和监控平台