第一讲: 程序的运行过程
程序的编译过程
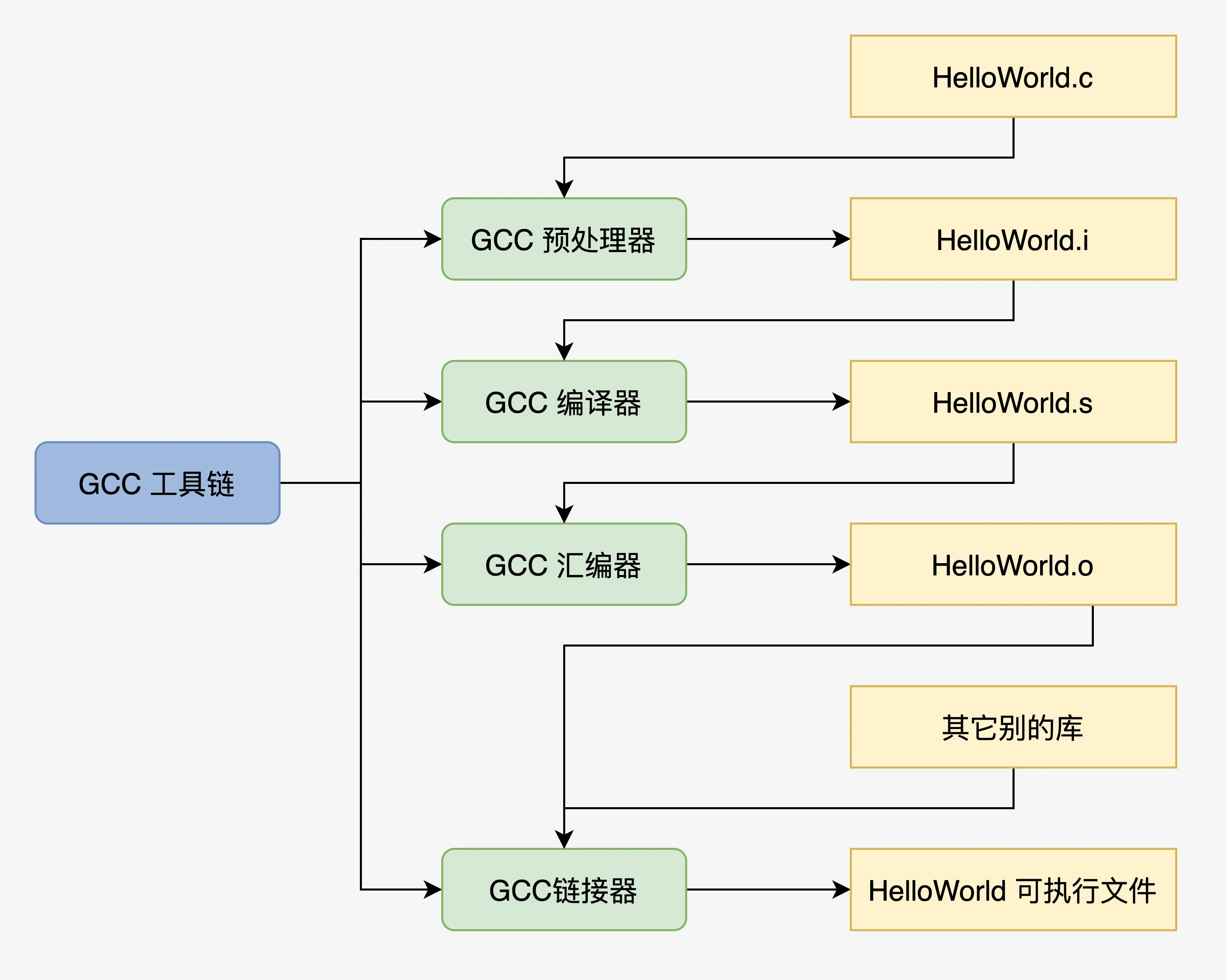
- 预处理:加入头文件,替换宏
gcc HelloWorld.c -o HelloWorld.i
- 编译:包含预处理,将C程序转成成汇编程序
gcc HelloWorld.c -S -c Helloworld.s
- 汇编:包含预处理和汇编,将汇编程序转换成可链接的二进制程序
gcc HelloWorld.c -c HelloWorld.o
- 链接:将可链接的二进制程序和其他的库链接在一起,形成可执行的程序文件
gcc HelloWorld.c -o HelloWorld
程序装载执行
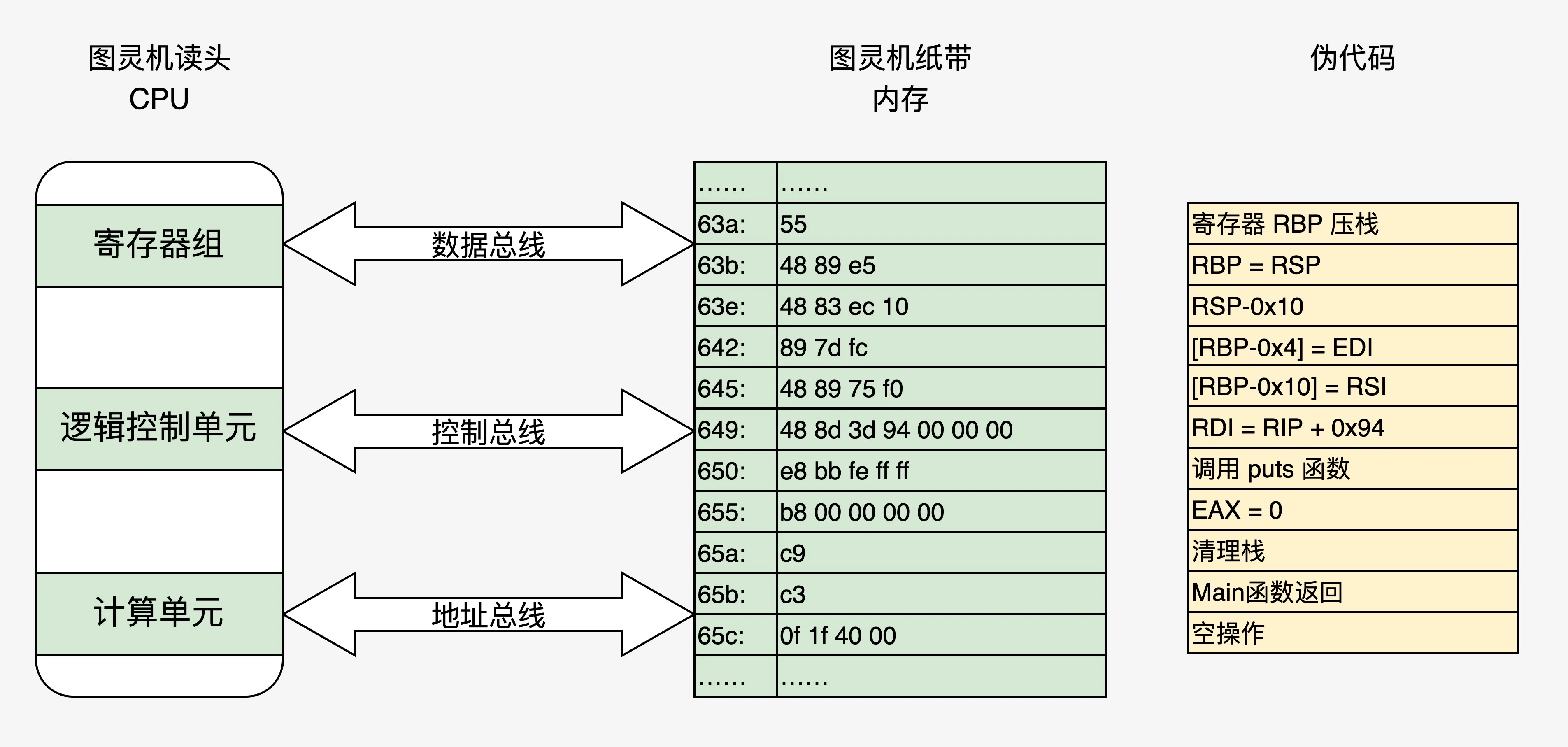
冯诺依曼体系结构五大组件
- 装载数据和程序的输入设备
- 记住程序和数据的存储器
- 完成数据加工的运算器
- 控制程序执行的控制器
- 显示处理结果的输出设备
HelloWorld汇编代码解释
objdump -d hello_world.o
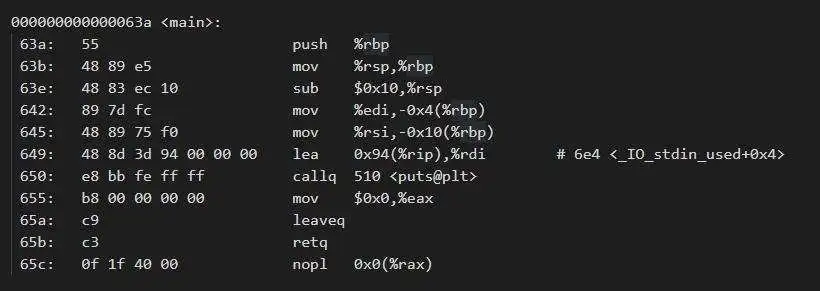
上图分为四列:
- 第一列为地址
- 第二列为数据
- 第三列为汇编命令
- 第四列为注释
将上图中代码装入计算机中,状态如下图:
第二讲:实现一个最小内核
OS引导流程
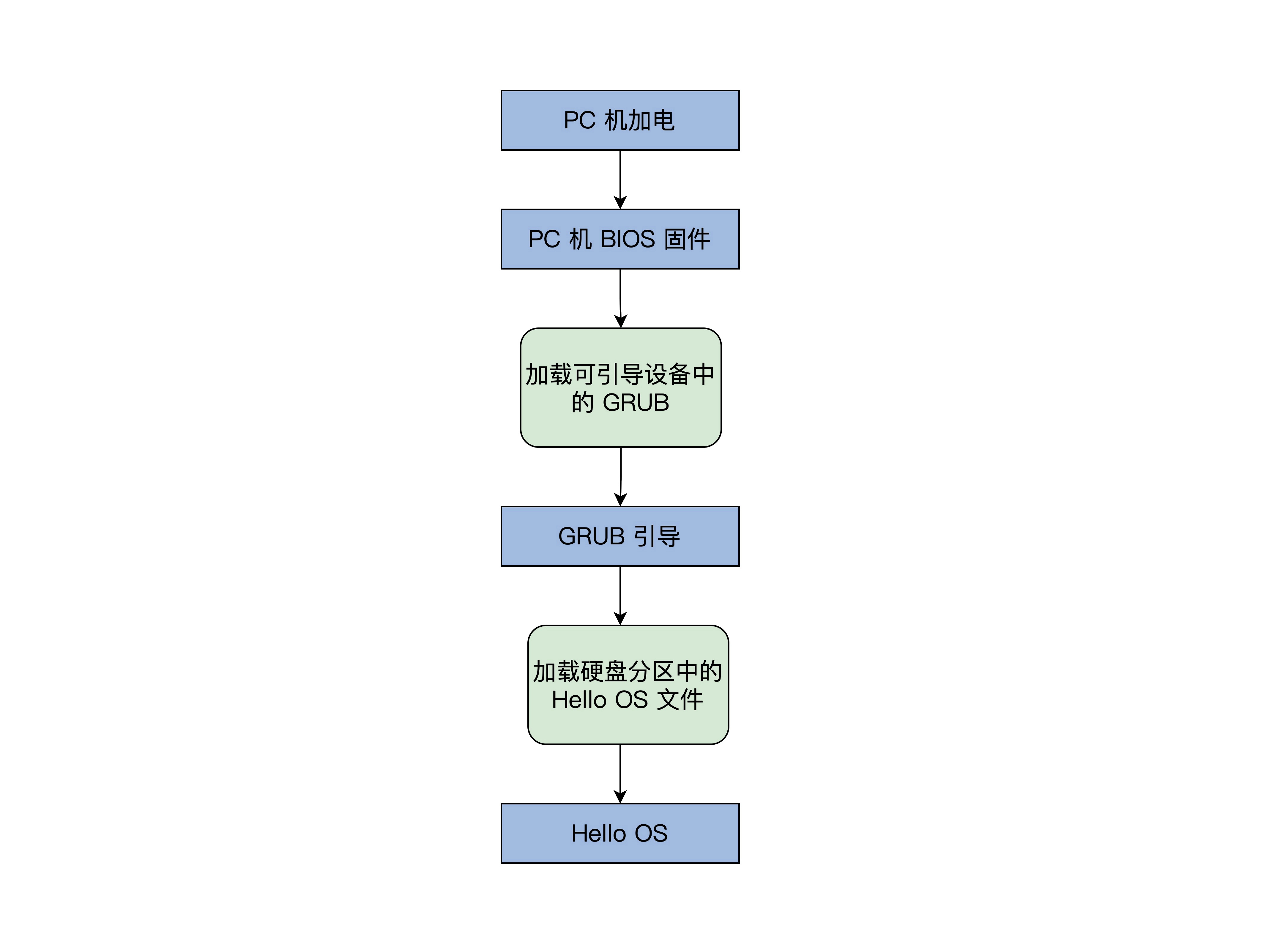
BIOS固件负责检测和初始化CPU、内存及主办平台,然后加载引导设备(如磁盘)的第一个扇区地址的数据
到0x7c00地址开始的内存空间,街道跳转到0x7c00处执行指令,即GRUB指导程序
引导汇编代码
C作为通用的高级语言不能直接操作特定的硬件,而且C语言的函数调用、传参都 需要栈
所以需要汇编代码来出席这些C语言的工作环境
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
;彭东 @ 2021.01.09
MBT_HDR_FLAGS EQU 0x00010003
MBT_HDR_MAGIC EQU 0x1BADB002 ;多引导协议头魔数
MBT_HDR2_MAGIC EQU 0xe85250d6 ;第二版多引导协议头魔数
global _start ;导出_start符号
extern main ;导入外部的main函数符号
[section .start.text] ;定义.start.text代码节
[bits 32] ;汇编成32位代码
_start:
jmp _entry
ALIGN 8
mbt_hdr:
dd MBT_HDR_MAGIC
dd MBT_HDR_FLAGS
dd -(MBT_HDR_MAGIC+MBT_HDR_FLAGS)
dd mbt_hdr
dd _start
dd 0
dd 0
dd _entry
;以上是GRUB所需要的头
ALIGN 8
mbt2_hdr:
DD MBT_HDR2_MAGIC
DD 0
DD mbt2_hdr_end - mbt2_hdr
DD -(MBT_HDR2_MAGIC + 0 + (mbt2_hdr_end - mbt2_hdr))
DW 2, 0
DD 24
DD mbt2_hdr
DD _start
DD 0
DD 0
DW 3, 0
DD 12
DD _entry
DD 0
DW 0, 0
DD 8
mbt2_hdr_end:
;以上是GRUB2所需要的头
;包含两个头是为了同时兼容GRUB、GRUB2
ALIGN 8
_entry:
;关中断
cli
;关不可屏蔽中断
in al, 0x70
or al, 0x80
out 0x70,al
;重新加载GDT
lgdt [GDT_PTR]
jmp dword 0x8 :_32bits_mode
_32bits_mode:
;下面初始化C语言可能会用到的寄存器
mov ax, 0x10
mov ds, ax
mov ss, ax
mov es, ax
mov fs, ax
mov gs, ax
xor eax,eax
xor ebx,ebx
xor ecx,ecx
xor edx,edx
xor edi,edi
xor esi,esi
xor ebp,ebp
xor esp,esp
;初始化栈,C语言需要栈才能工作
mov esp,0x9000
;调用C语言函数main
call main
;让CPU停止执行指令
halt_step:
halt
jmp halt_step
GDT_START:
knull_dsc: dq 0
kcode_dsc: dq 0x00cf9e000000ffff
kdata_dsc: dq 0x00cf92000000ffff
k16cd_dsc: dq 0x00009e000000ffff
k16da_dsc: dq 0x000092000000ffff
GDT_END:
GDT_PTR:
GDTLEN dw GDT_END-GDT_START-1
GDTBASE dd GDT_START
|
- 1~40行:GRUB多引导协议头
- 44~52行:关掉中断,设定CPU的工作模式
- 54~73行:初始化CPU的寄存器和C语言的运行环境
- 78~87行:设置CPU工作模式所需要的数据
主函数
1
2
3
4
5
6
7
|
//main.c
#include "vgastr.h"
void main()
{
printf("Hello OS!");
return;
}
|
控制计算机屏幕
显卡有多种形式
- 集显:集成在主办
- 核显:CPU芯片内
- 独显:独立存在,同时PCIE接口连接
显卡的字符模式将屏幕分成24行,每行80个字符,把字符映射到以0xb8000开始的内存中
一个字符对应两个字节,一个字节是字符的ASCII码,另外一个字节为字符的颜色值
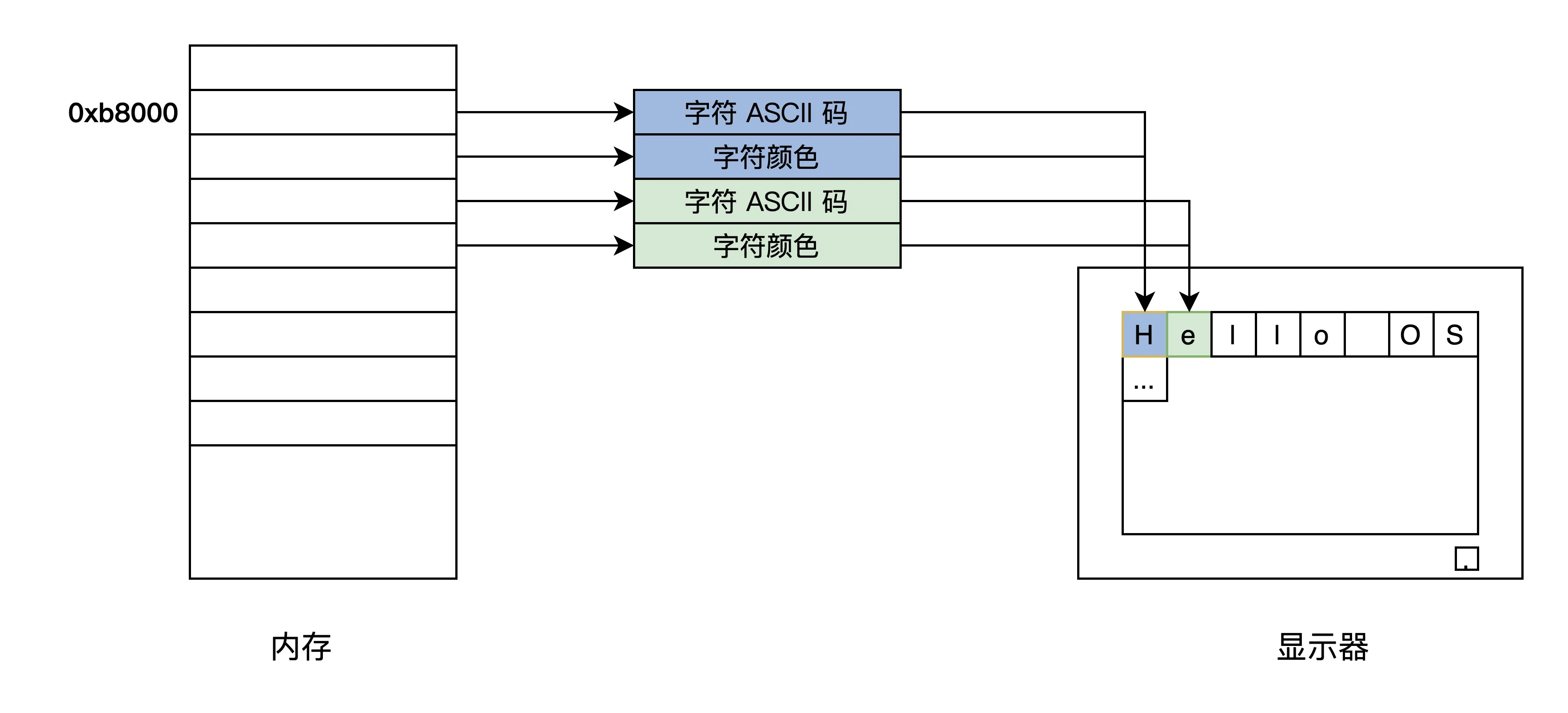
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// vgsstr.c
void _strwrite(char* string)
{
char* p_string = (char*)(oxb8000); //显存开始的地址
while (*string)
{
*p_string = *string++;
p_string += 2;
}
return;
}
void printf(char* fmt, ...)
{
_strwrite(fmt);
return;
}
|
编译和安装
编译
安装
上述编译流程会得到HelloOS.bin文件,但序言GRUB能够找到它
具体配置在grub.cfg的文件中
1
2
3
4
5
6
7
|
menuentry 'HelloOS' {
insmod part_msdos #GRUB加载分区模块识别分区
insmod ext2 #GRUB加载ext文件系统模块识别ext文件系统
set root='hd0,msdos4' #注意boot目录挂载的分区(df /boot 查看)
multiboot2 /boot/HelloOS.bin #GRUB以multiboot2协议加载HelloOS.bin
boot #GRUB启动HelloOS.bin
}
|
重启系统长按shit键然后选择HelloOS即可
第三讲:内核结构设计
内核功能
- 管理CPU:CPU是执行程序的,而内核吧运行时的程序抽象成 进程,所以称之为进程管理
- 管理内存
- 管理硬盘
- 管理显卡
- 管理各种I/O设备
宏内核结构
宏内核就是所有诸如管理进程等功能的代码进过编译链接形成一个大的可执行程序
这个大程序里有实现这个功能的所有代码,向应用软件提供一些接口(即系统API)

宏内核的优点是组件都在内核中合一相互调用性能极高;但缺点也很明显,高度耦合,没有模块化
微内核结构
微内核仅仅只有进程调度、处理中断、内存空间映射和进程间通信等功能
实际功能如进程管理、内存管理、文件管理等做成一个个服务进程
微内核与应用进程和服务进程通过消息通信
应用程序要请求相关服务,就向微内核发送一条与此服务对应的消息,微内核再把这条消息转发给相关的服务进程,接着服务进程会完成相关的服务。
我们的选择
大致将内核分为三个大层
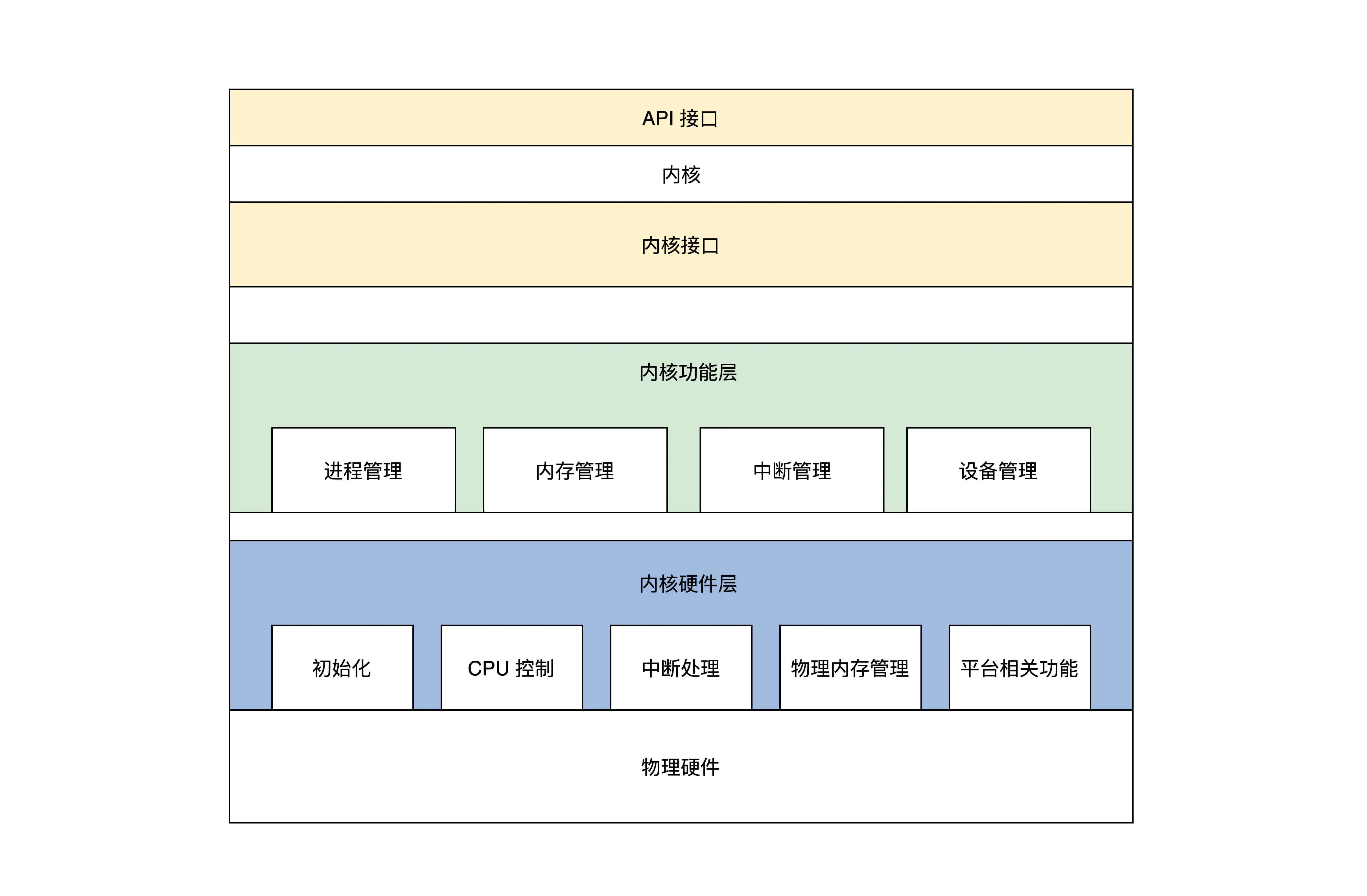
内核接口层
- 定义了一套UNIX接口的子集
- 检查参数的合法性
内核功能层
主要完成各种事件功能
- 进程管理:实现进程的创建、销毁、调度
- 内存管理:内存池分为页面内存池和任意大小的内存池
- 中断管理:把中断回调函数安插在相关的数据结构中,发生相关的中断就会调用回调函数
- 设备管理:把驱动程序模块、驱动程序本身和驱动程序创建的设备组织在一起
内核硬件层
- 初始化:初始化少量的设备、CPU、内存、中断的控制,内核用户管理的数据结构
- CPU控制:提供CPU模式设定、开关中断、读写CPU特定寄存器等功能
- 中断处理:保存上下文、调用中断回调函数、操作中断控制器
- 物理内存管理:分配和释放大块内存、内存空间映射、操作MMU和Cache
- 平台其他相关功能
第四讲:业界成熟内核架构
Linux
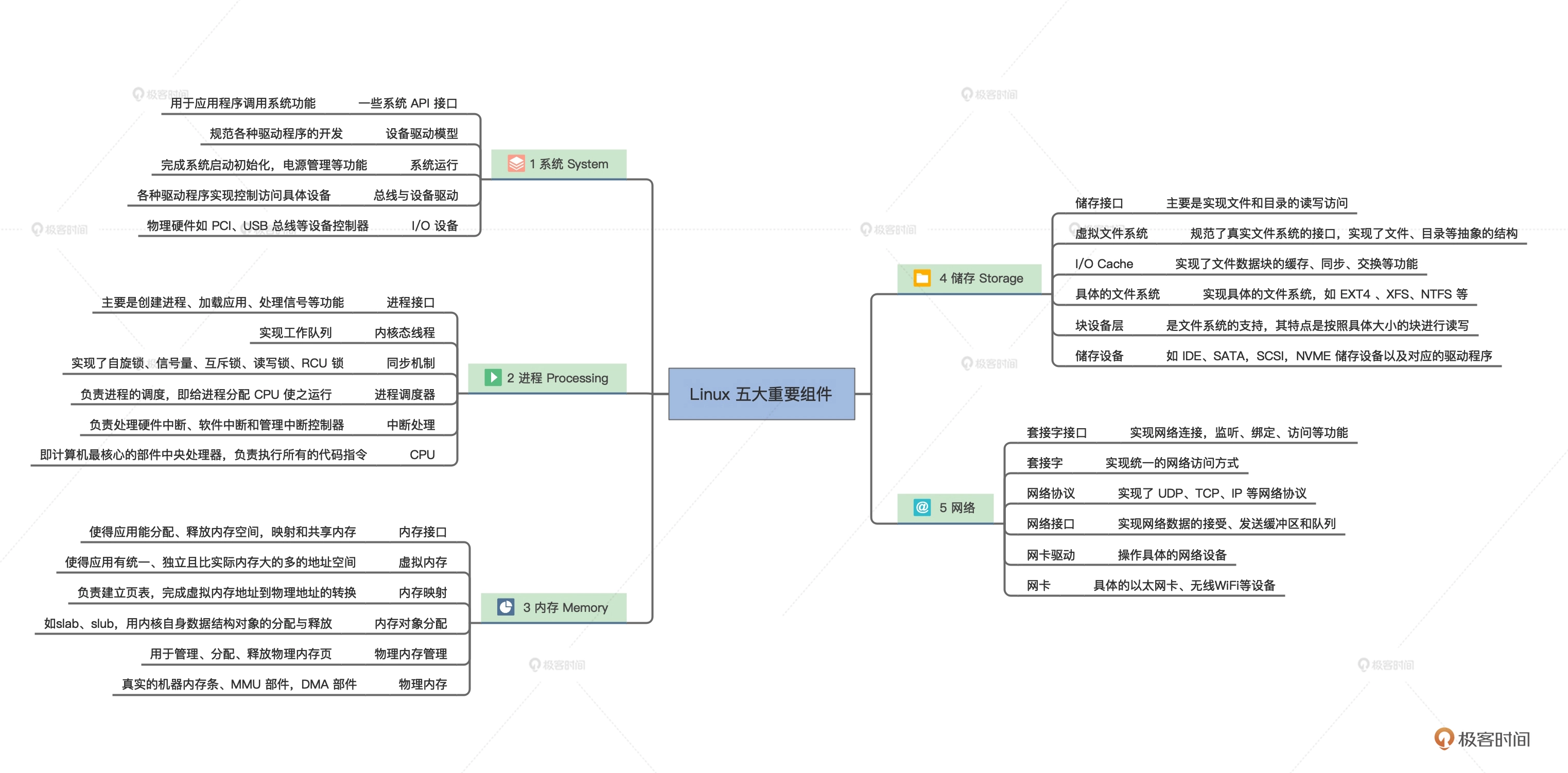
Linux使用的宏内核架构,模块之间的通信主要是函数调用
Darwin
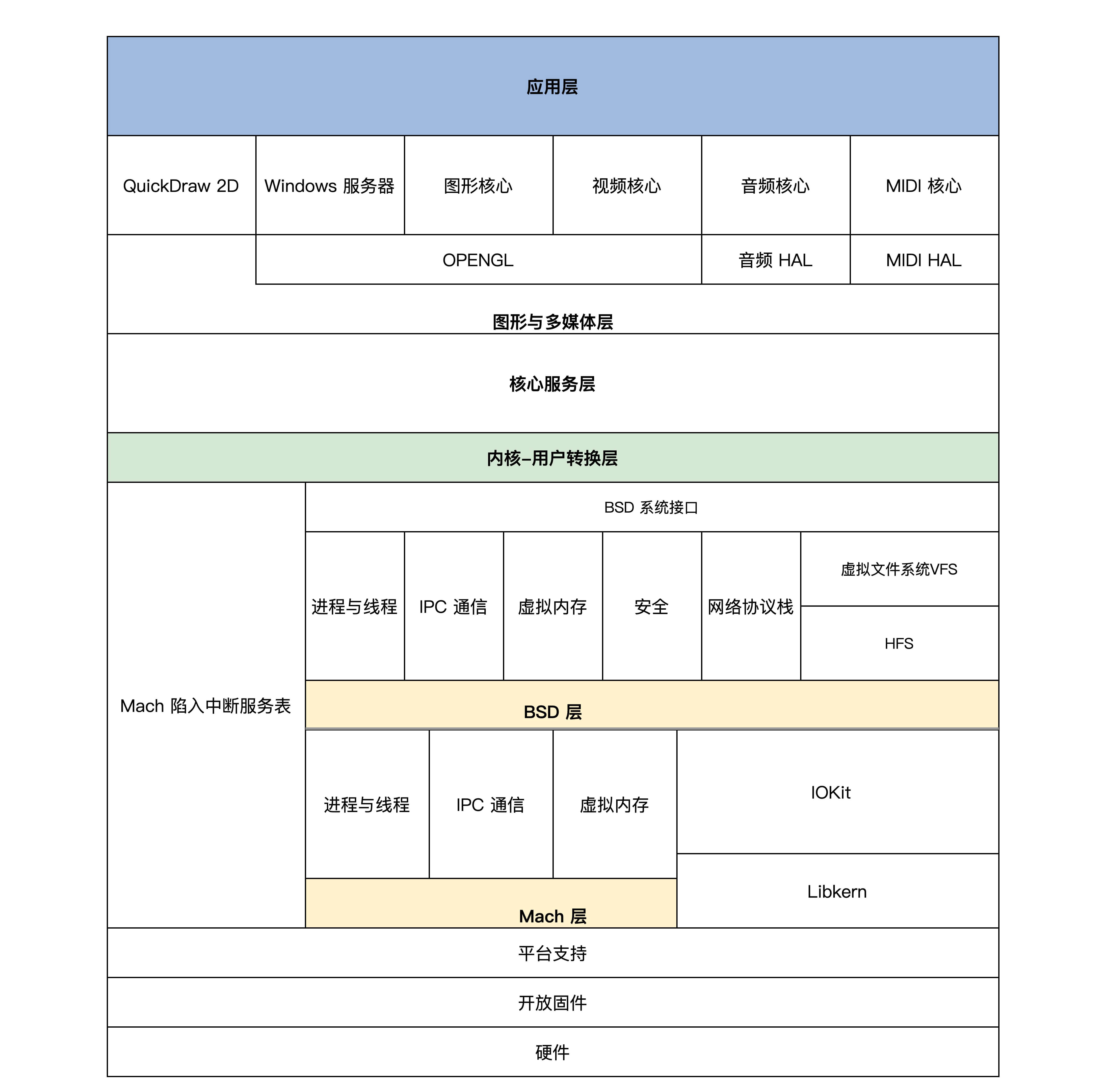
Darwin有两个内核层
- Mach层:微内核,然提供十分简单的进程、线程、IPC 通信、虚拟内存设备驱动相关的功能服务
- BSD层:提供强大的安全特性,完善的网络服务,各种文件系统的支持,同时对 Mach 的进程、线程、IPC、虚拟内核组件进行细化、扩展延伸
Windows NT
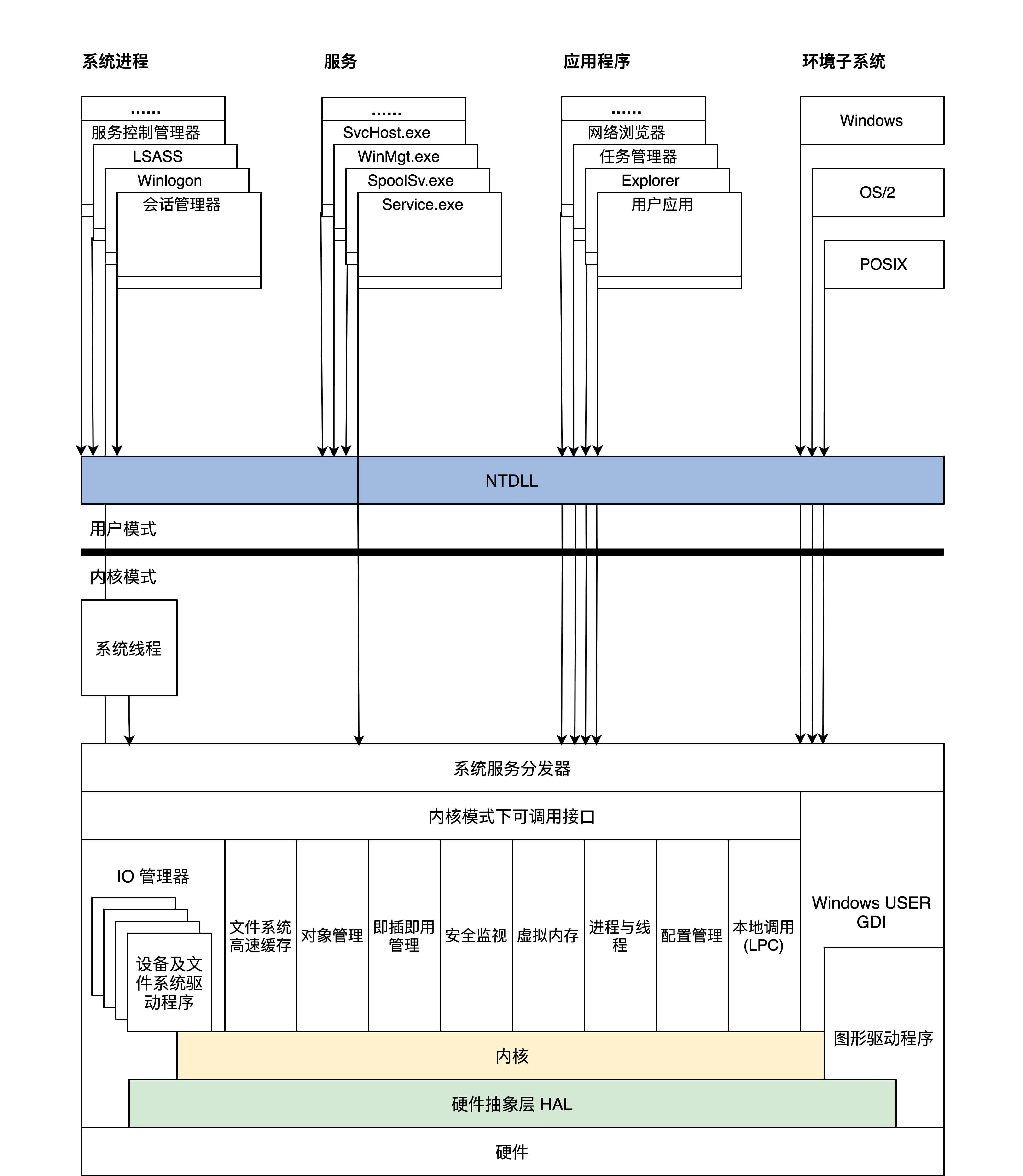
每个执行体互相独立,只对外提供相应的接口,其它执行体要通过内核模式可调用接口和其它执行体通信或者请求其完成相应的功能服务
评论区拾遗
内核相当于所有的功能都耦合在一起,放在内核内
微内核是把大多数功能解耦出来,放在用户态,使用IPC在用户态调用服务进程
混合结构其实与微内核相似,只不过解耦出来的这些功能依然放在内核里,动态加载和卸载
第五讲:执行程序的三种模式
CPU的工作模式有三种
实模式
实模式又称实地址模式,一方面是运行真实的指令,另一方面内存地址是真实的
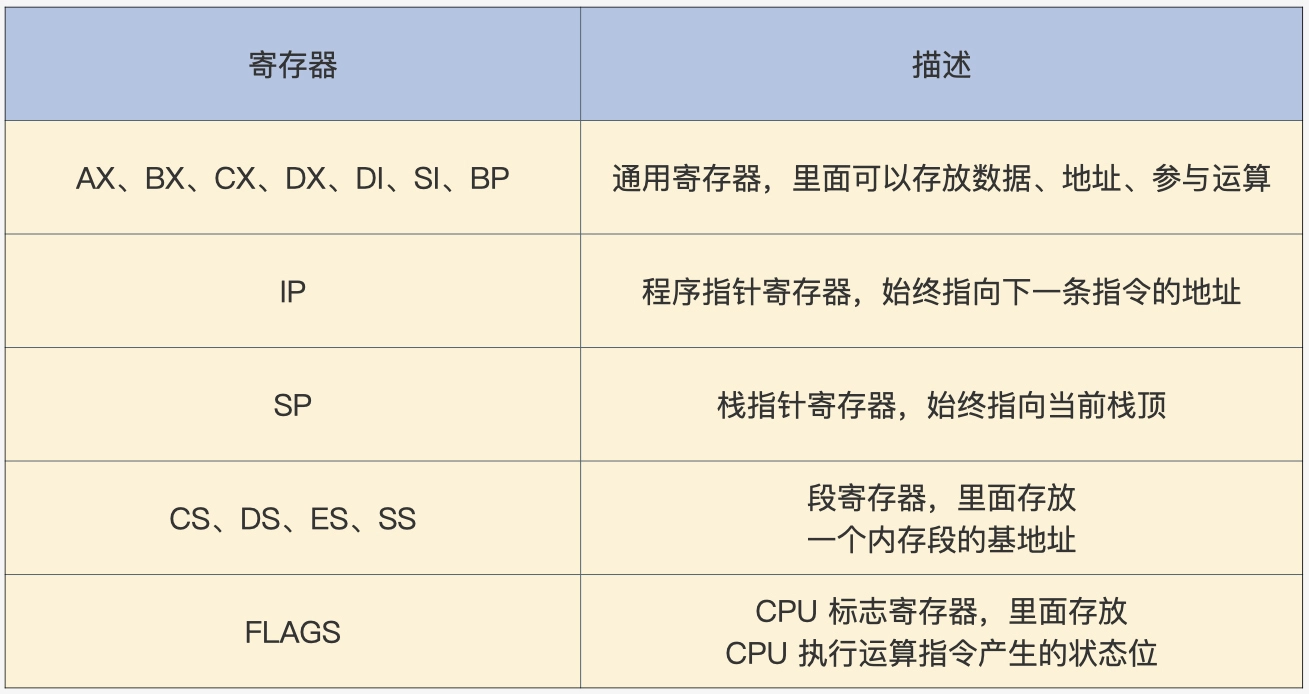
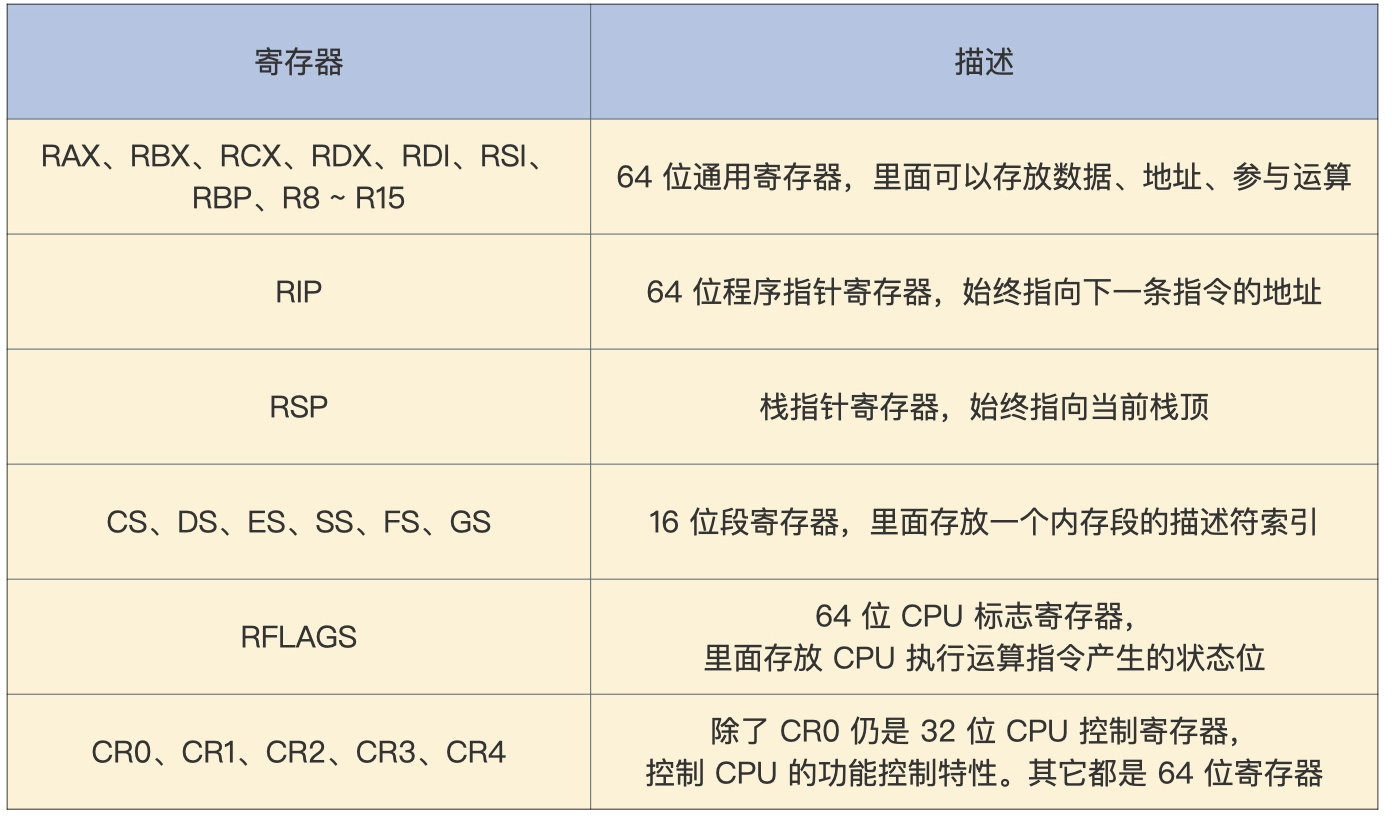
寄存器
通常情况下指令的操作数就是寄存器,下图为x86 实模式下的寄存器
内存
指令和数据都放在内存中,内存的地址值计算过程如下图
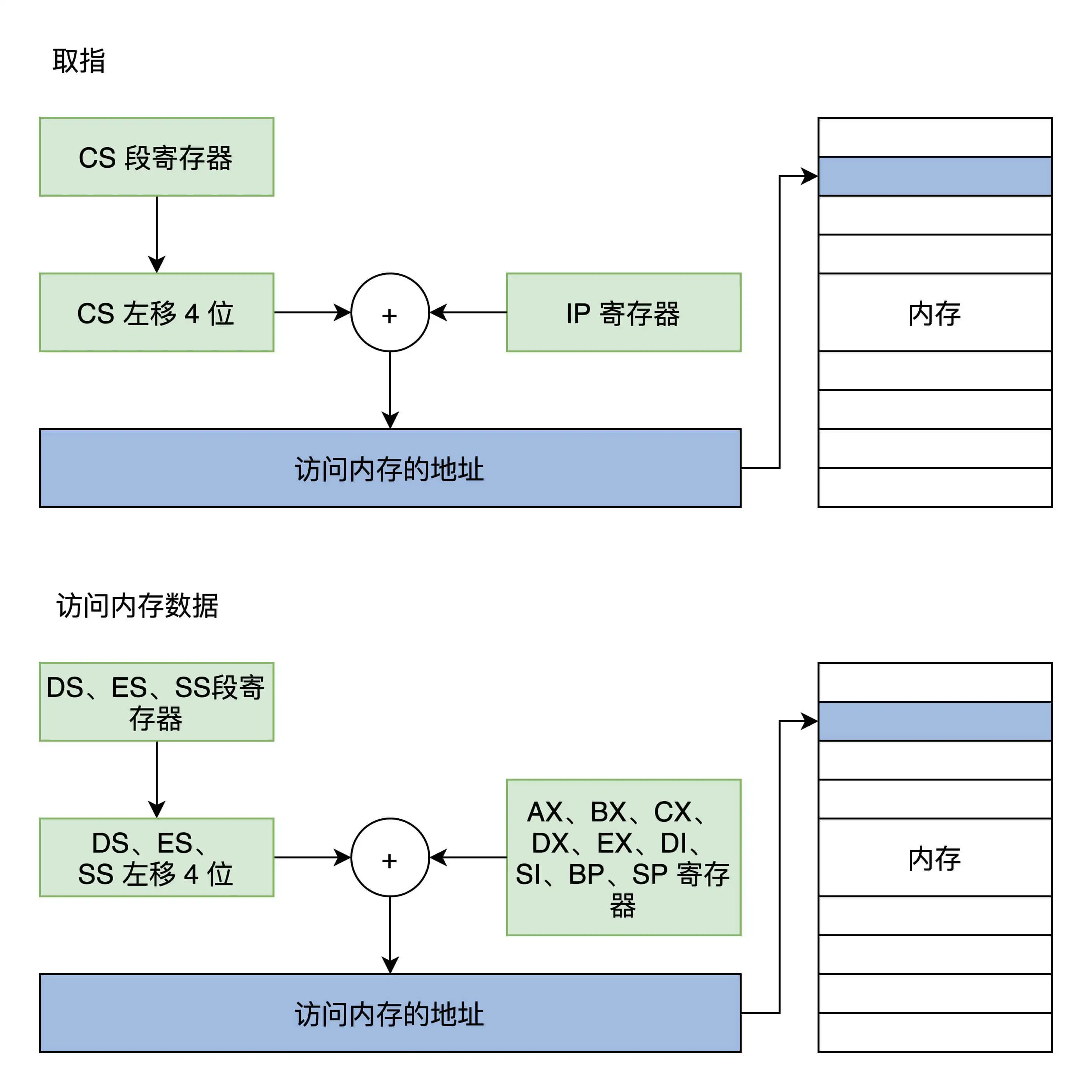
内存地址是由段寄存器左移4位,再加上一个统统寄存器的值形成地址,然后由这个地址去访问内存
(这个即是分段内存管理模式)
代码段是CS和IP确定的,栈段是由SS和SP确定的
DOS实模式汇编代码程序实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
data SEGMENT ;定义一个数据段存放Hello World!
hello DB 'Hello World!$' ;注意要以$结束
data ENDS
code SEGMENT ;定义一个代码段存放程序指令
ASSUME CS:CODE,DS:DATA ;告诉汇编程序,DS指向数据段,CS指向代码段
start:
MOV AX,data ;将data段首地址赋值给AX
MOV DS,AX ;将AX赋值给DS,使DS指向data段
LEA DX,hello ;使DX指向hello首地址
MOV AH,09h ;给AH设置参数09H,AH是AX高8位,AL是AX低8位,其它类似
INT 21h ;执行DOS中断输出DS指向的DX指向的字符串hello
MOV AX,4C00h ;给AH设置参数4C00h
INT 21h ;调用4C00h号功能,结束程序
code ENDS
END start
|
中断
中断即终止当前程序,转而跳转到另一个特定的地址上,去运行特定的代码。
在实模式中即:先保存CS和IP寄存器,然后装载新的CS和IP寄存器
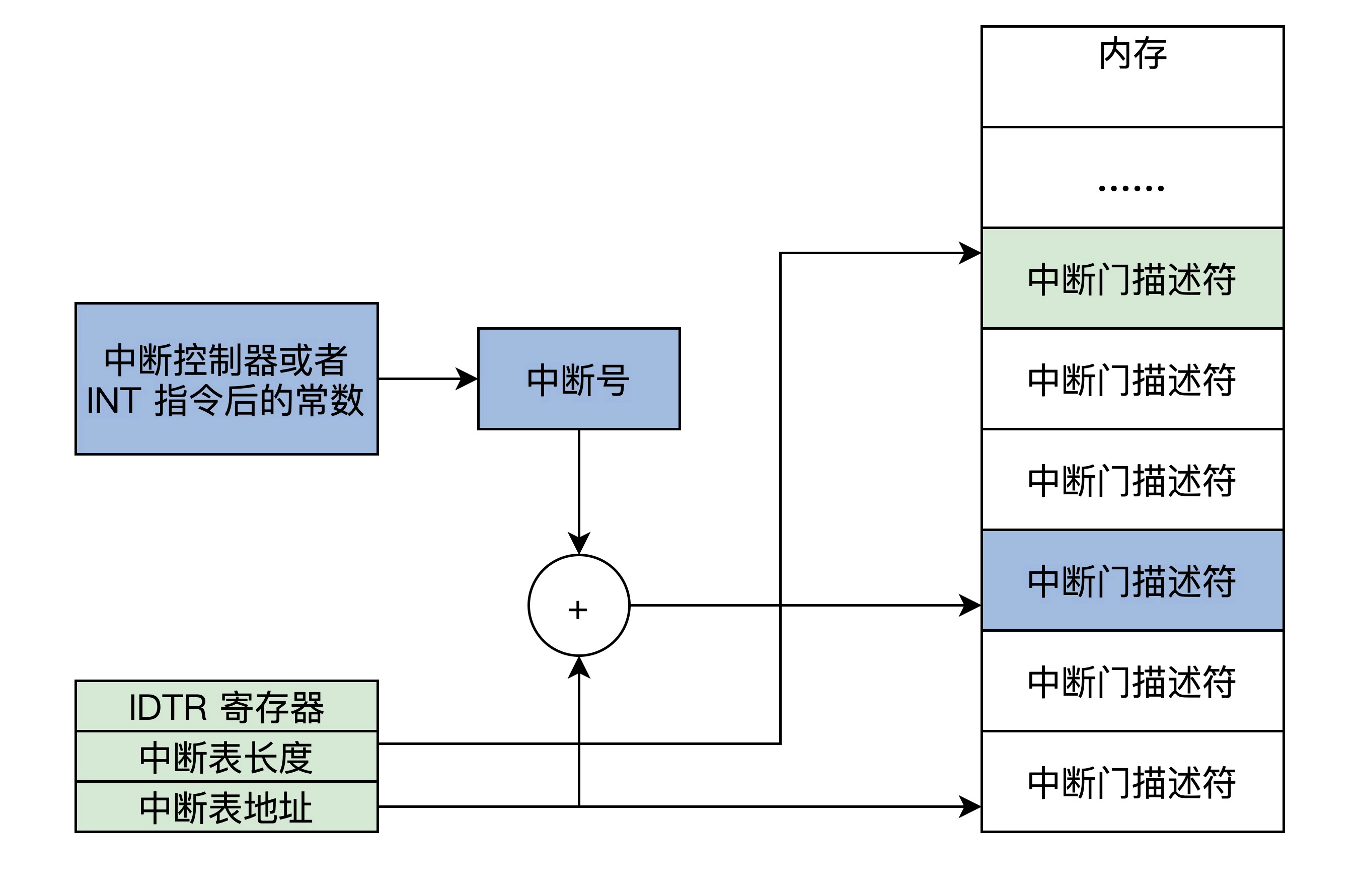
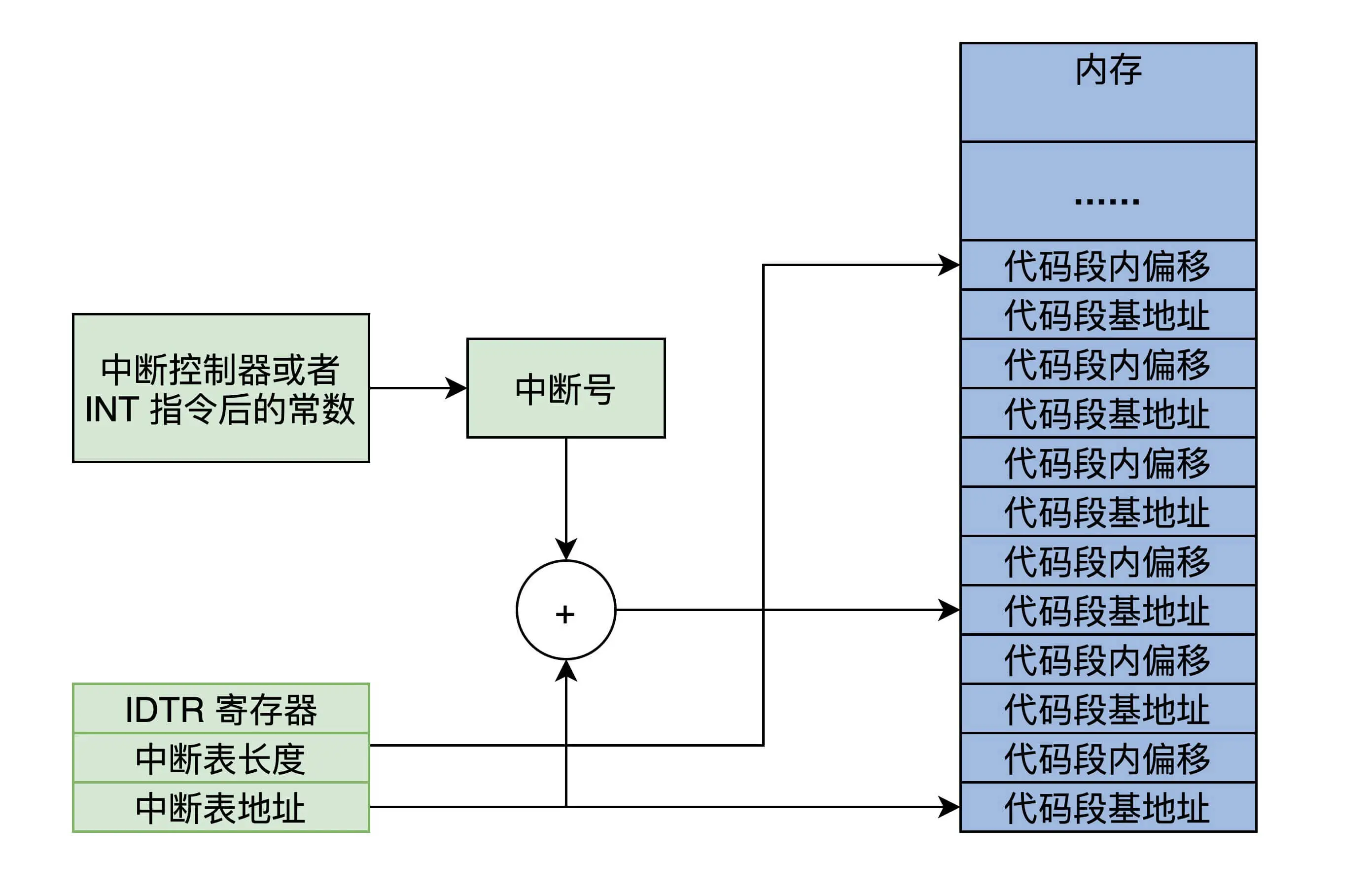 为了实现中断,就需要在内存中放一个中断向量表(中断信号和对应响应程序的首地址)
为了实现中断,就需要在内存中放一个中断向量表(中断信号和对应响应程序的首地址)
这个表的地址和长度由IDTR寄存器指向,在实模式中,一个条目由代码段地址和端内偏移组成
根据中断信合和IDTR寄存器的信息,CPU能够计算出中断向量的条目,进而装载CS(段基地址)、IP寄存器(段内偏移),最终响应中断
保护模式
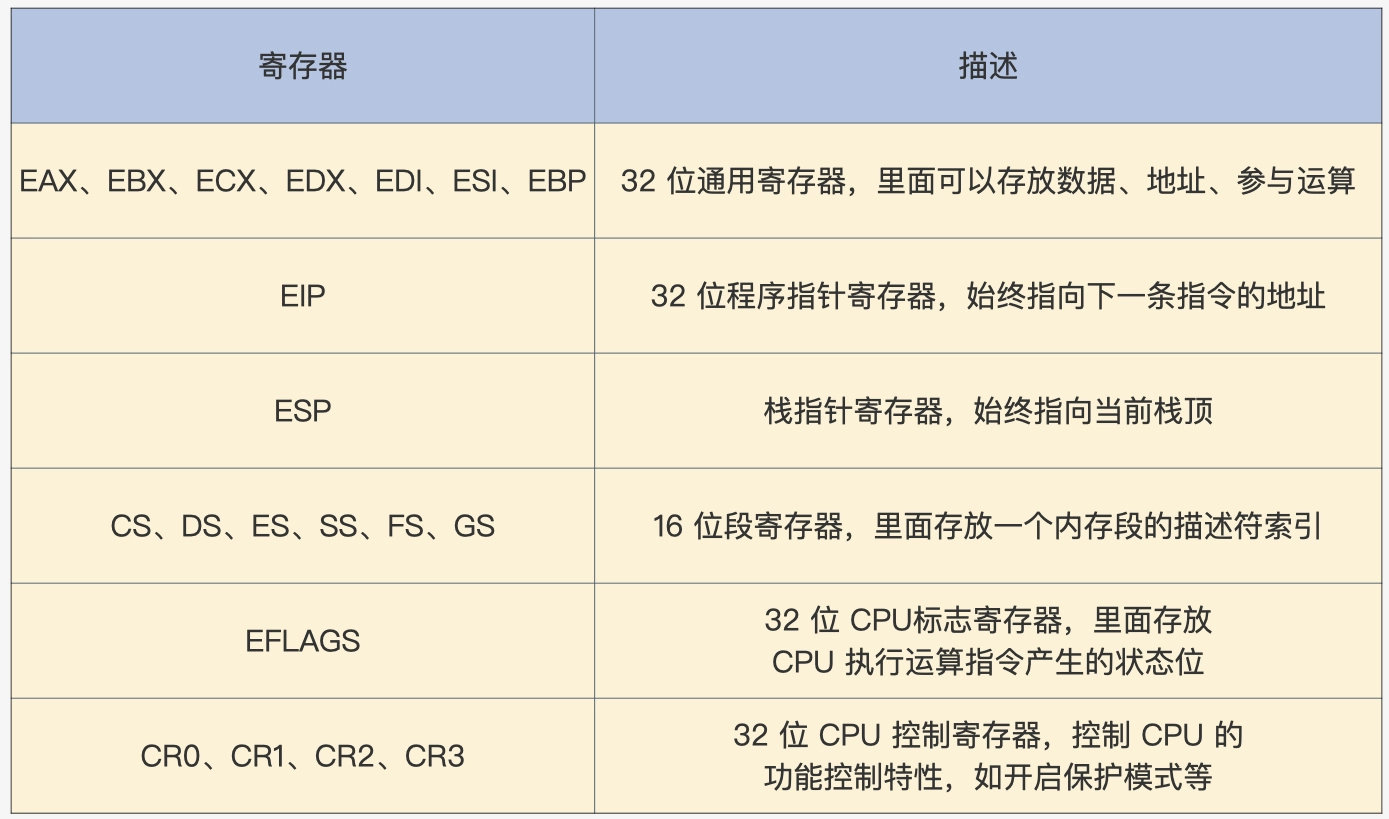
相比实模式,保护模式增加了一些控制寄存器和段寄存器,扩展通用寄存器的位宽
特权级
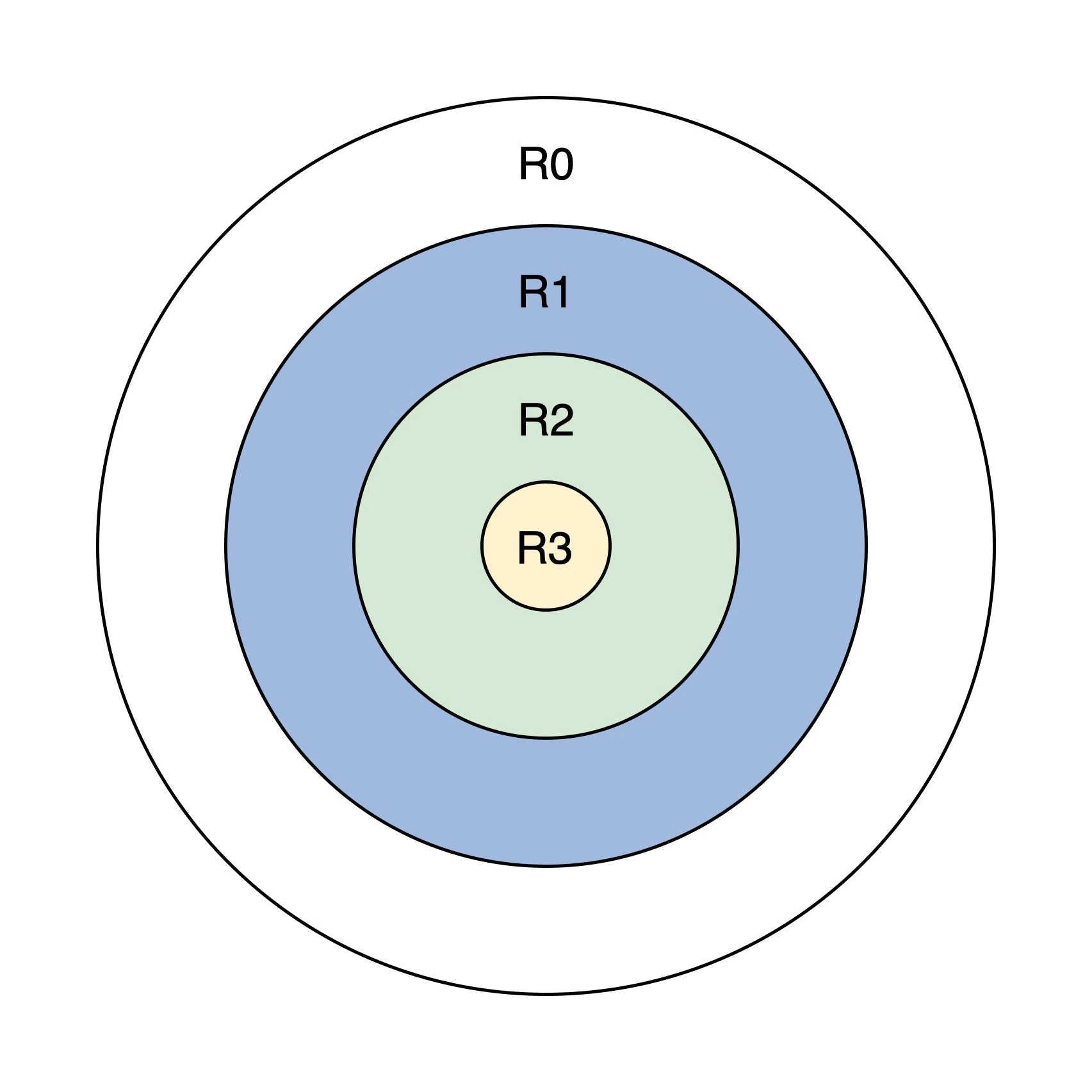
从内到外,权力逐步提升
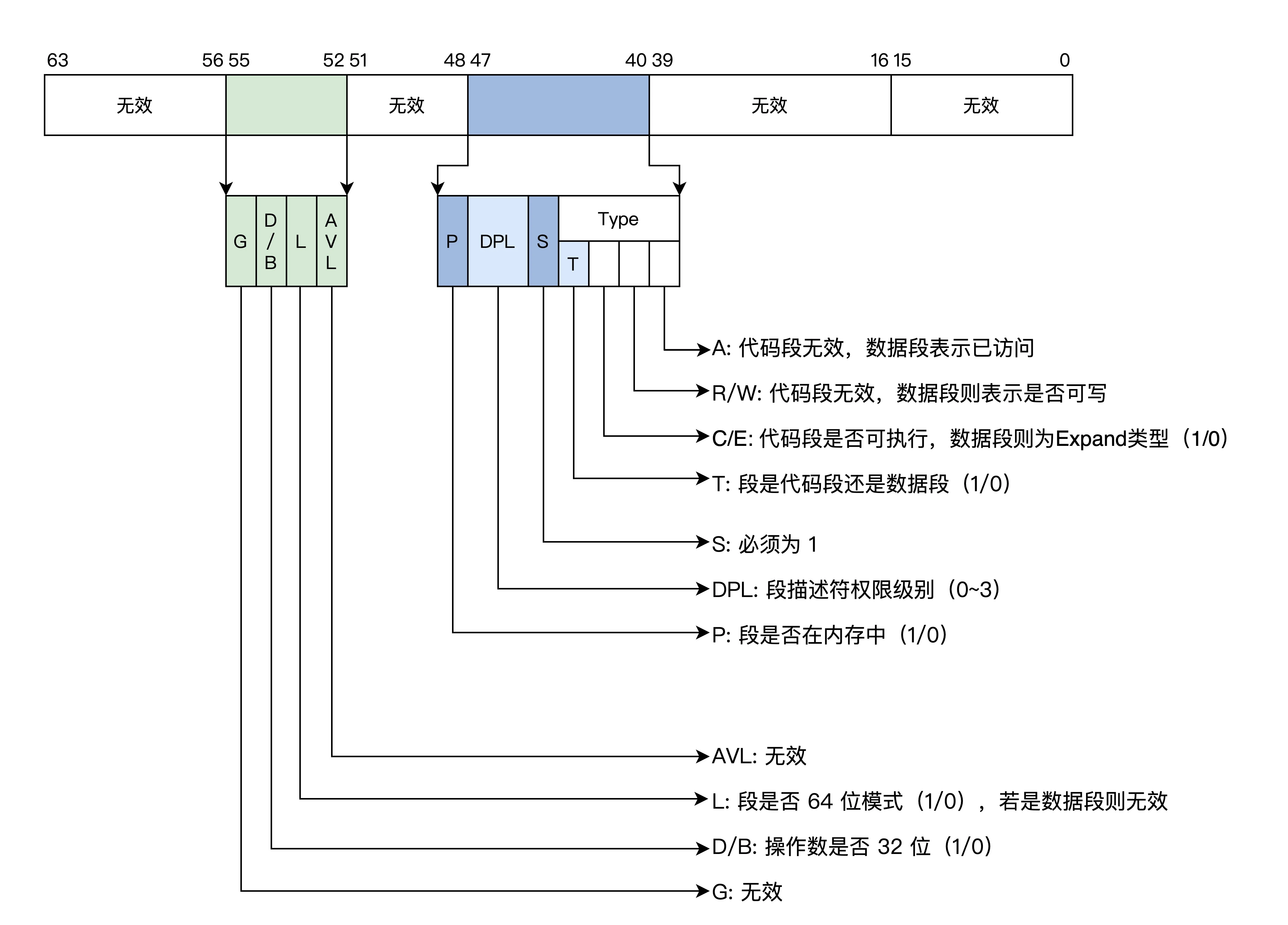
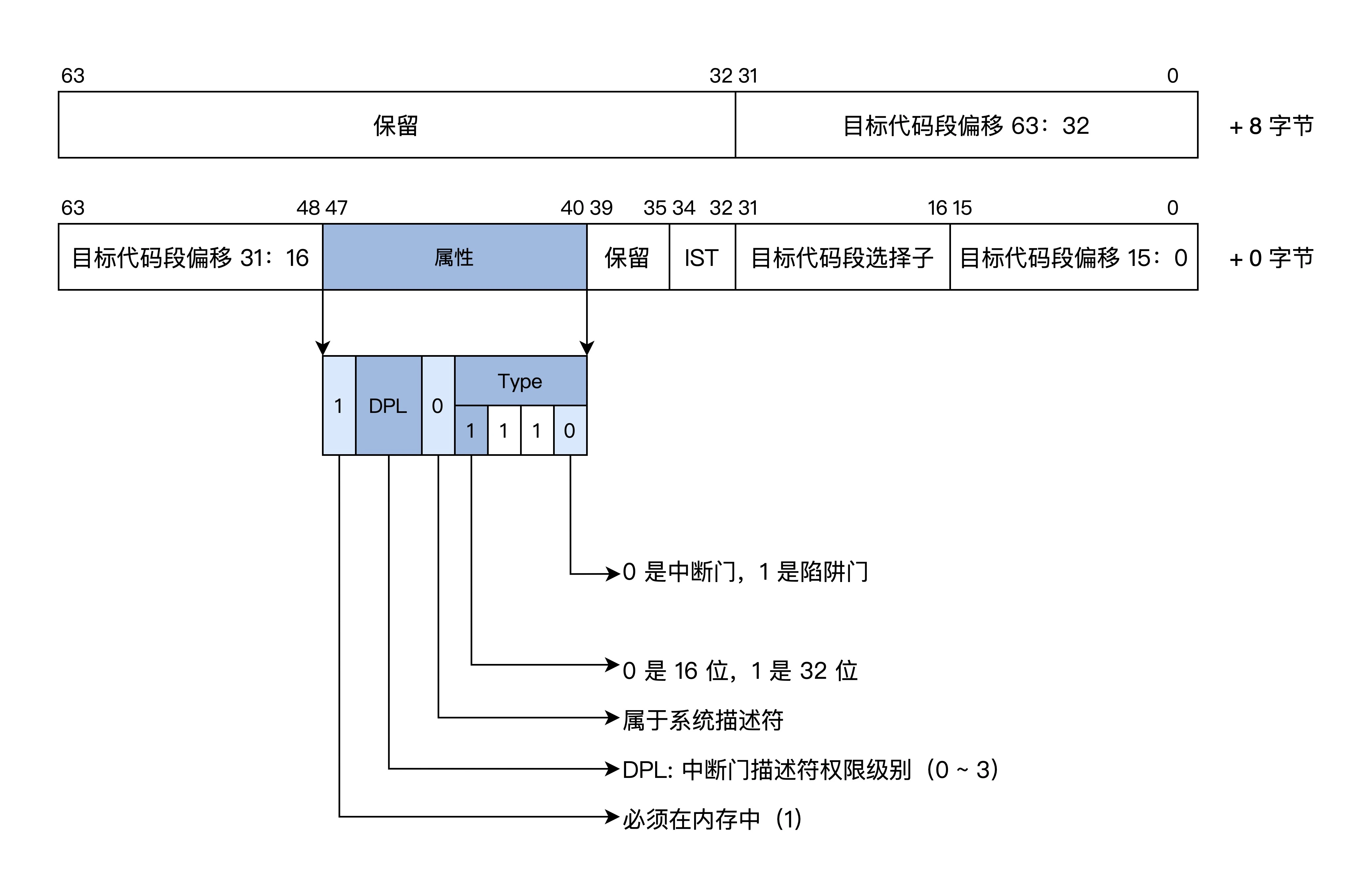
段描述符
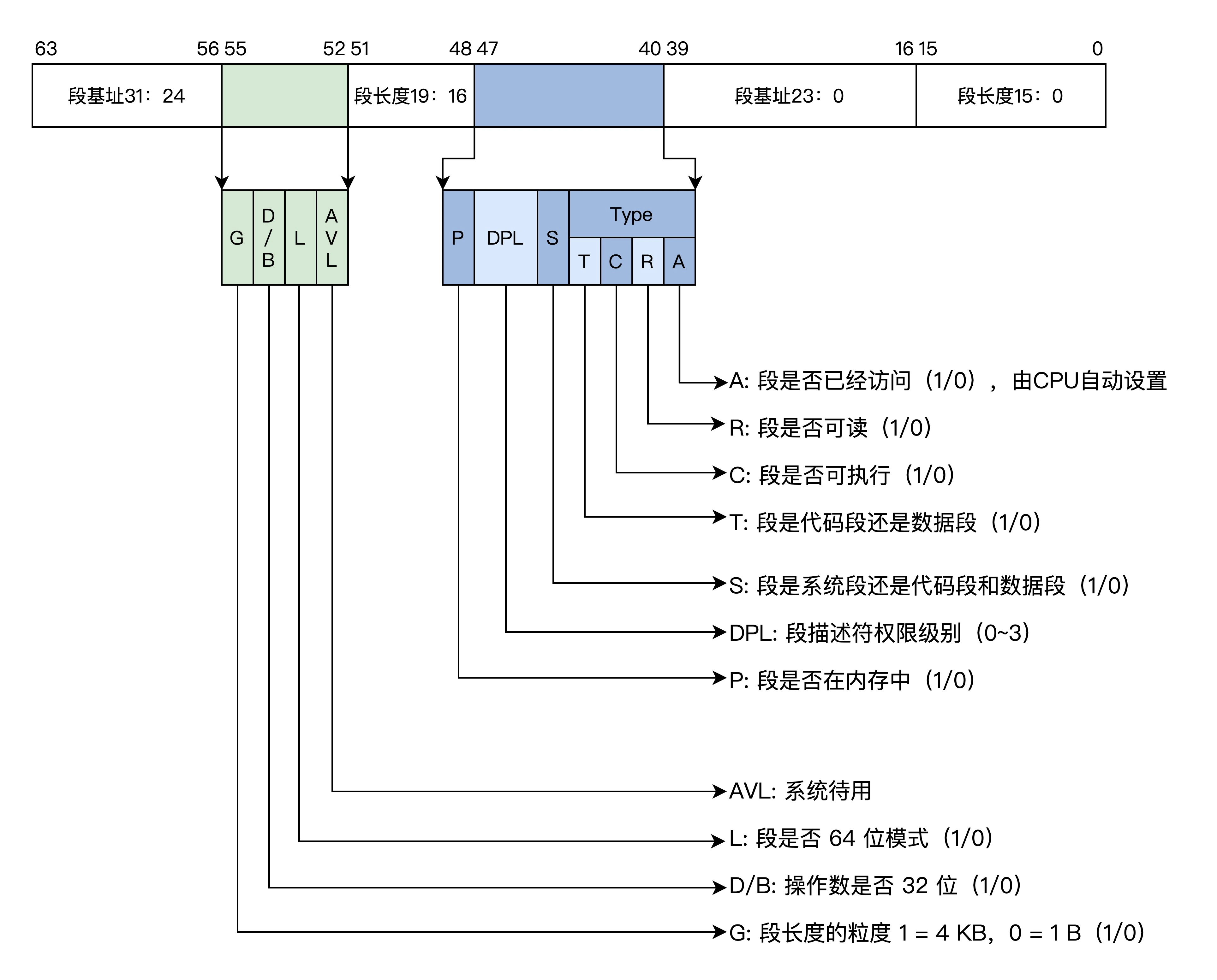
内存是分段模型,对内存的保护可以转化成对段的保护
段描述符是一个64位的数据,包含了段基地址、段长度、段权限、段类型和读写状态等
由于信息的扩展,16位的寄存器放不下,段描述符放在内存中
多个段描述符在内存中形成全局段描述符表,该表的基地址和长度由GDTR寄存器指示
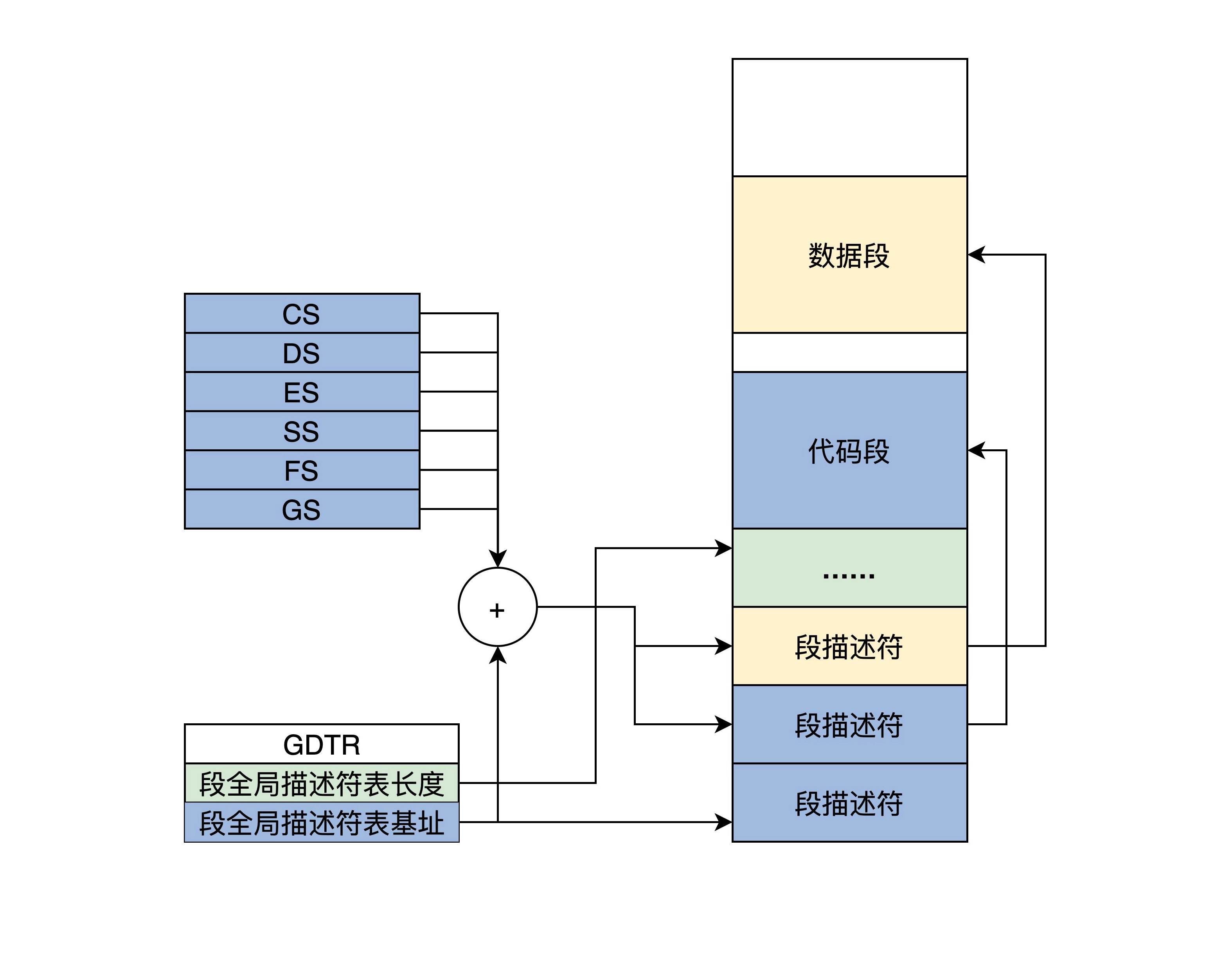
段寄存器不再放段基地址,而是段在段描述符表的索引
平坦模型
x86 CPU不能直接使用分页模型,通过简化设计,来时分段称为一个"虚设",这个称之为保护模式的平坦模型
将段的基地址设为0,段长度设为0xFFFFF(2 ** 20 = 1M),段的粒度为4KB
在此模式下不同的段可以重叠、交叉和包含
中断
保护模式需要检查权限,所以需要扩展中断向量表的信息
每个中断用一个中断门描述符来表示,格式如下
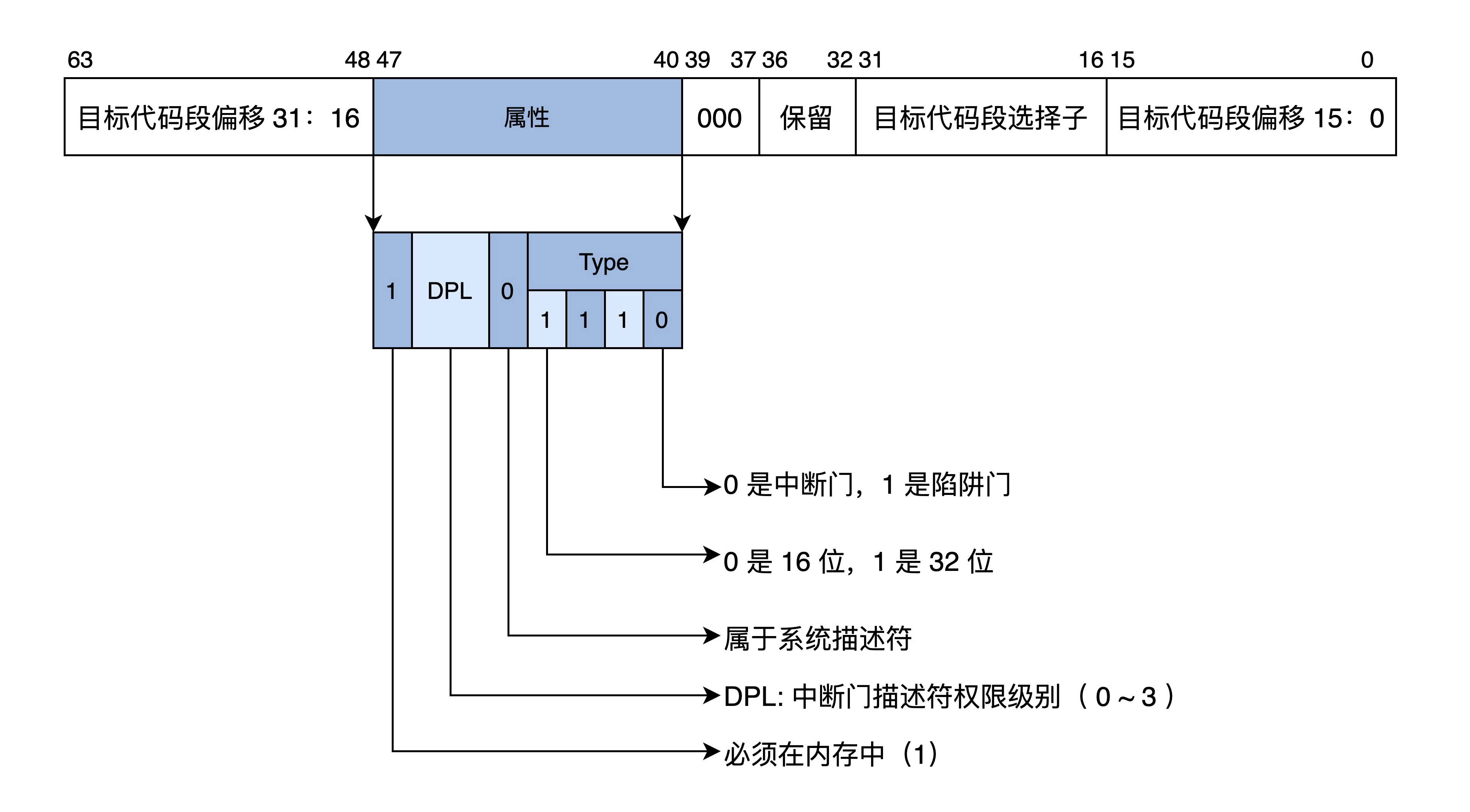
中断向量表的条目也变成了中断门描述符
产生中断后
- 检查中断号是否在有效区间(0~255)
- 检查描述符类型
- 权限检查(如果权限等级不同会进行栈切换)
- 加载目标代码偏移段到EIP寄存器
切换
由实模式切换到保护模式步骤如下:
- 准备全局段描述符表
1
2
3
4
5
6
7
8
|
GDT_START:
knull_dsc: dq 0
kcode_dsc: dq 0x00cf9e000000ffff
kdata_dsc: dq 0x00cf92000000ffff
GDT_END:
GDT_PTR:
GDTLEN dw GDT_END-GDT_START-1
GDTBASE dd GDT_START
|
- 设置GDTR寄存器,使之指向全局段描述符表
- 设置CR0寄存器,开启保护模式
1
2
3
4
|
;开启 PE
mov eax, cr0
bts eax, 0 ; CR0.PE =1
mov cr0, eax
|
- 进行长跳转,加载CS段寄存器
1
|
jmp dword 0x8 :_32bits_mode ;_32bits_mode为32位代码标号即段偏移
|
长模式
长模式又称AMD64,它是CPU在现有基础上有了64位的处理能力
寄存器
所有通用寄存器都是64位,可以单独使用低32位,低32位可以查封成一个低16位,低16位可以拆分成两个8位寄存器
段描述符
中断
切换
- 准备长模式全局段描述符表
1
2
3
4
5
6
7
8
|
ex64_GDT:
null_dsc: dq 0
;第一个段描述符CPU硬件规定必须为0
c64_dsc:dq 0x0020980000000000 ;64位代码段
d64_dsc:dq 0x0000920000000000 ;64位数据段
eGdtLen equ $ - null_dsc ;GDT长度
eGdtPtr:dw eGdtLen - 1 ;GDT界限
dq ex64_GDT
|
- 准备长模式下的MMU页表
长模式下内存地址空间的保护交给了 MMU,MMU 依赖页表对地址进行转换,页表有特定的格式存放在内存中,其地址由 CPU 的 CR3 寄存器指向
1
2
3
4
5
|
mov eax, cr4
bts eax, 5 ;CR4.PAE = 1
mov cr4, eax ;开启 PAE
mov eax, PAGE_TLB_BADR ;页表物理地址
mov cr3, eax
|
- 加载GDTR寄存器,是指指向全局段描述符
- 开启长模式
1
2
3
4
5
6
7
8
9
10
|
;开启 64位长模式
mov ecx, IA32_EFER
rdmsr
bts eax, 8 ;IA32_EFER.LME =1
wrmsr
;开启 保护模式和分页模式
mov eax, cr0
bts eax, 0 ;CR0.PE =1
bts eax, 31
mov cr0, eax
|
- 进行跳转,加载CS段寄存器
1
|
jmp 08:entry64 ;entry64为程序标号即64位偏移地址
|
第六讲:地址转换
虚拟地址
虚拟地址由链接器产生,链接器的主要工作是吧多个代码模块组装在一起,并解决模块之间的引用
,即处理程序代码间的地址引用,形成程序运行的静态内存空间视图
物理地址
物理地址会被地址译码器变成电信号,放在地址总线上,地址总线电子信号的各种组合就可以选择到内存的存储单元
虚实转换
虚实地址转换是通过MMU(内存管理单元)实现的
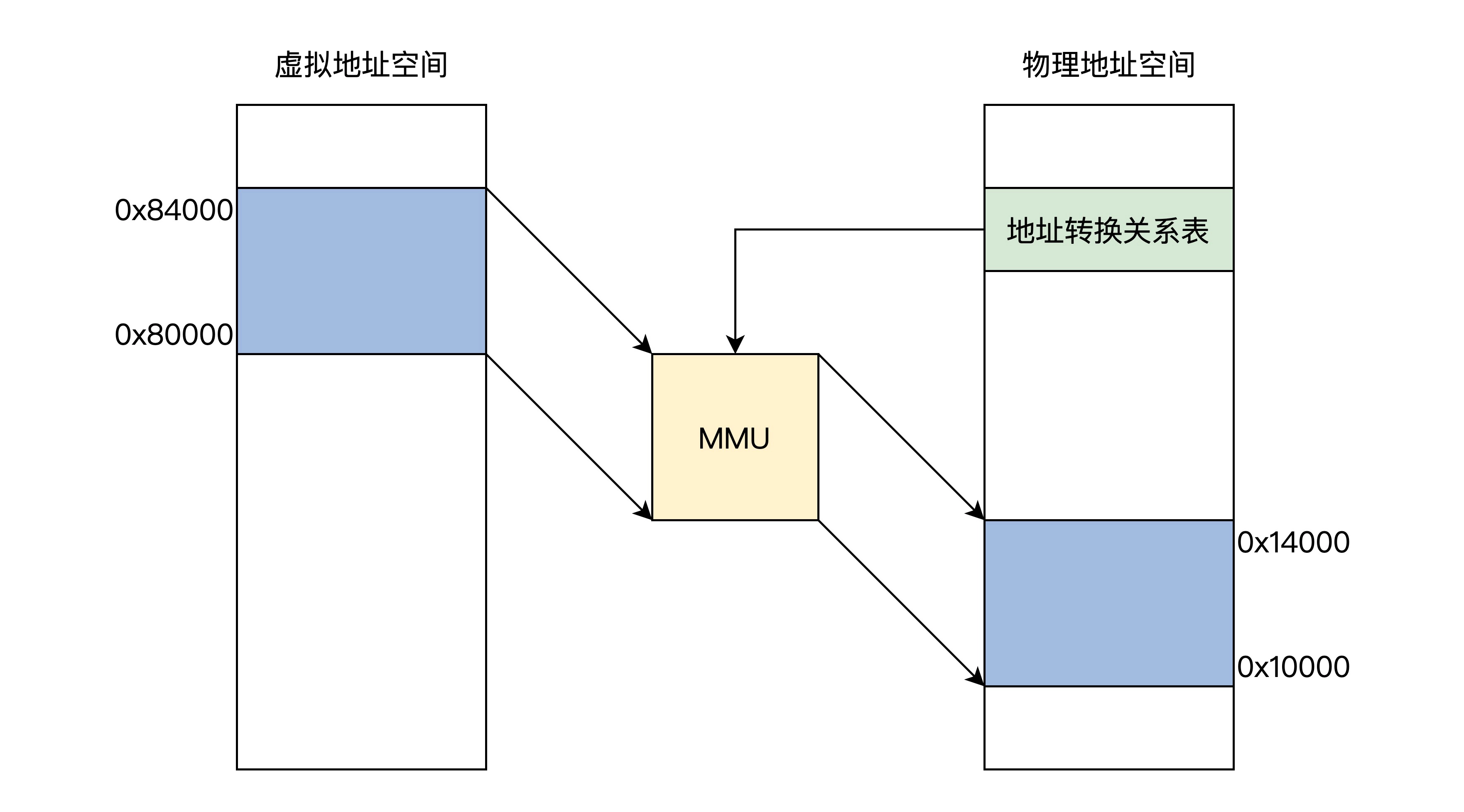
地址转换关系表本身存放在内存中,如果一个虚拟对称对应一个物理地址,转换表就会把内存耗尽
于是引出了分页模型,虚拟地址空间和物理地址空间都分成了同等大小的页
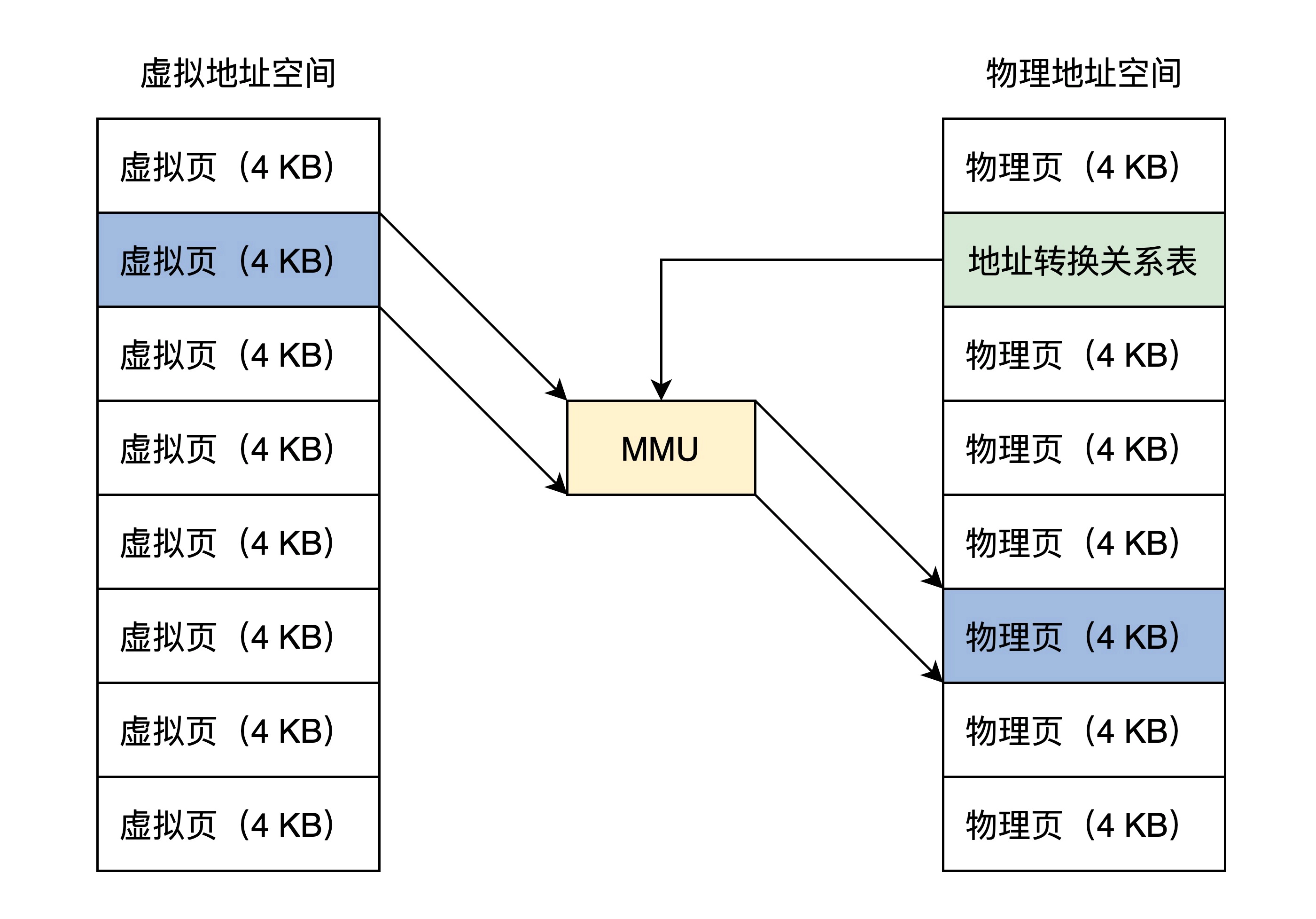
MMU
MMU负责接受虚拟地址值和地址关系转换表,然后输出物理地址
页表
页表即虚拟页到物理页的映射关系
为了洁身空间,页表值存放物理页面的地址,MMU以虚拟地址为索引去查表返回物理页地址
页表是分级的,分为三部分
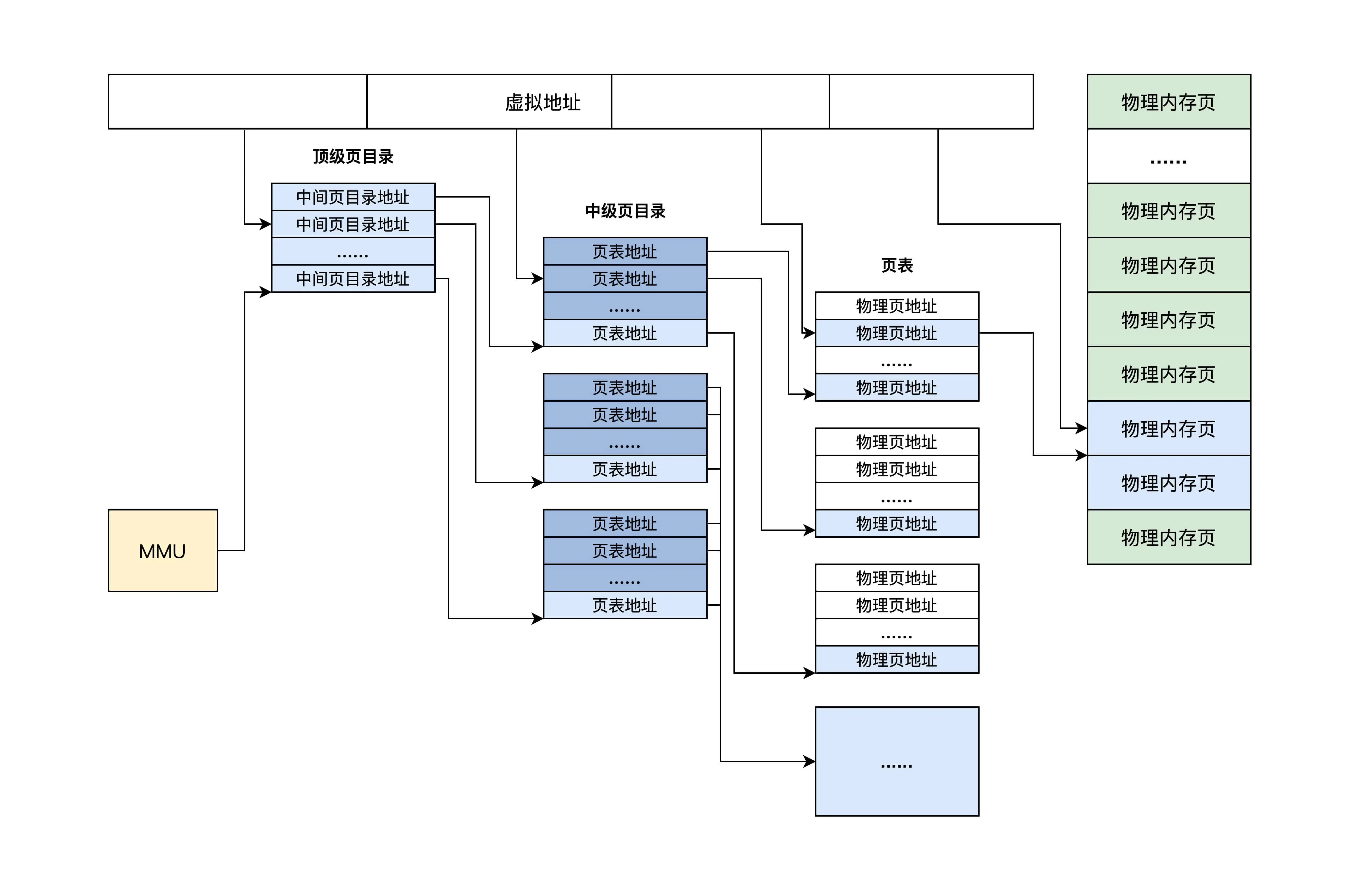
一个虚拟地址从左到右分为四个位段
- 第一个位段索引顶级页目录,得到中继页目录
- 第二个位段索引中级页目录,得到页目录
- 第三个位段索引也目录,得到物理页地址
- 第四个位段用作该物理页的偏移去访问物理内存
保护模式下的分页
保护模式下只有32位地址空间,32位虚拟地址经过分段机制后得到线性地址,
通常使用平坦模式,所以线性地址和虚拟地址是相同的
4KB页
该分页方式下32位虚拟地址被分为三个位段: 页目录索引、页表索引、页内偏移
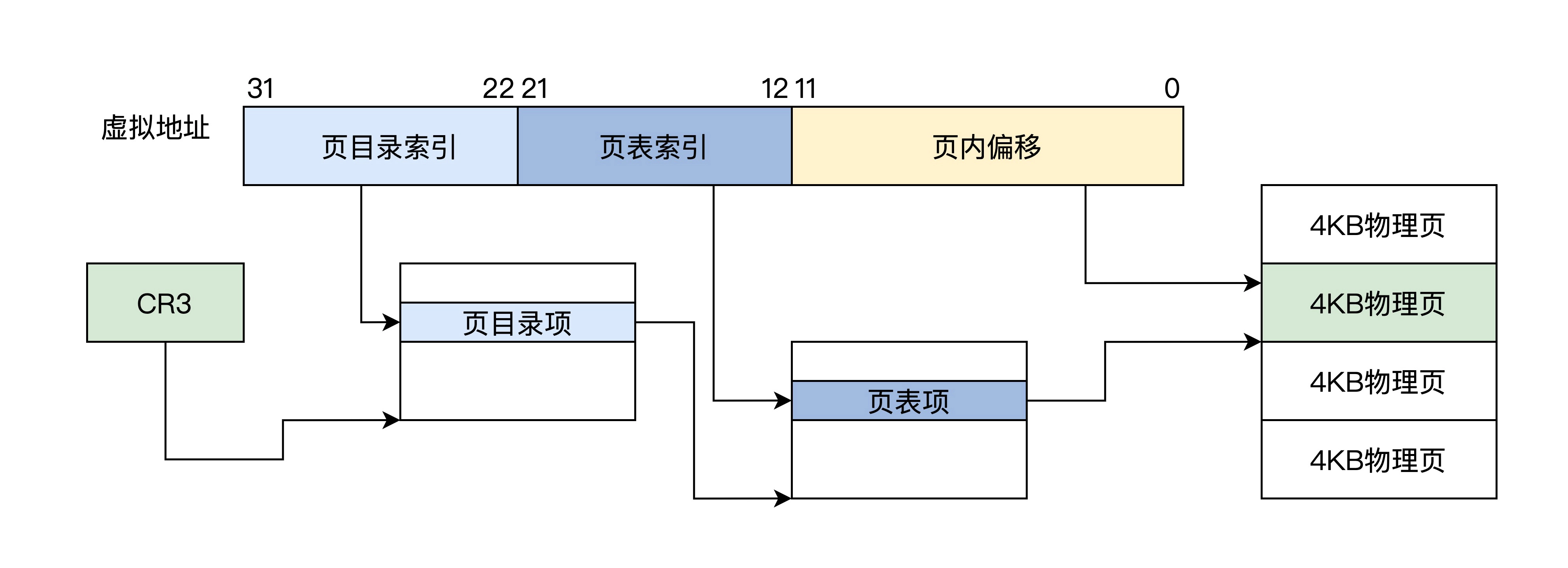
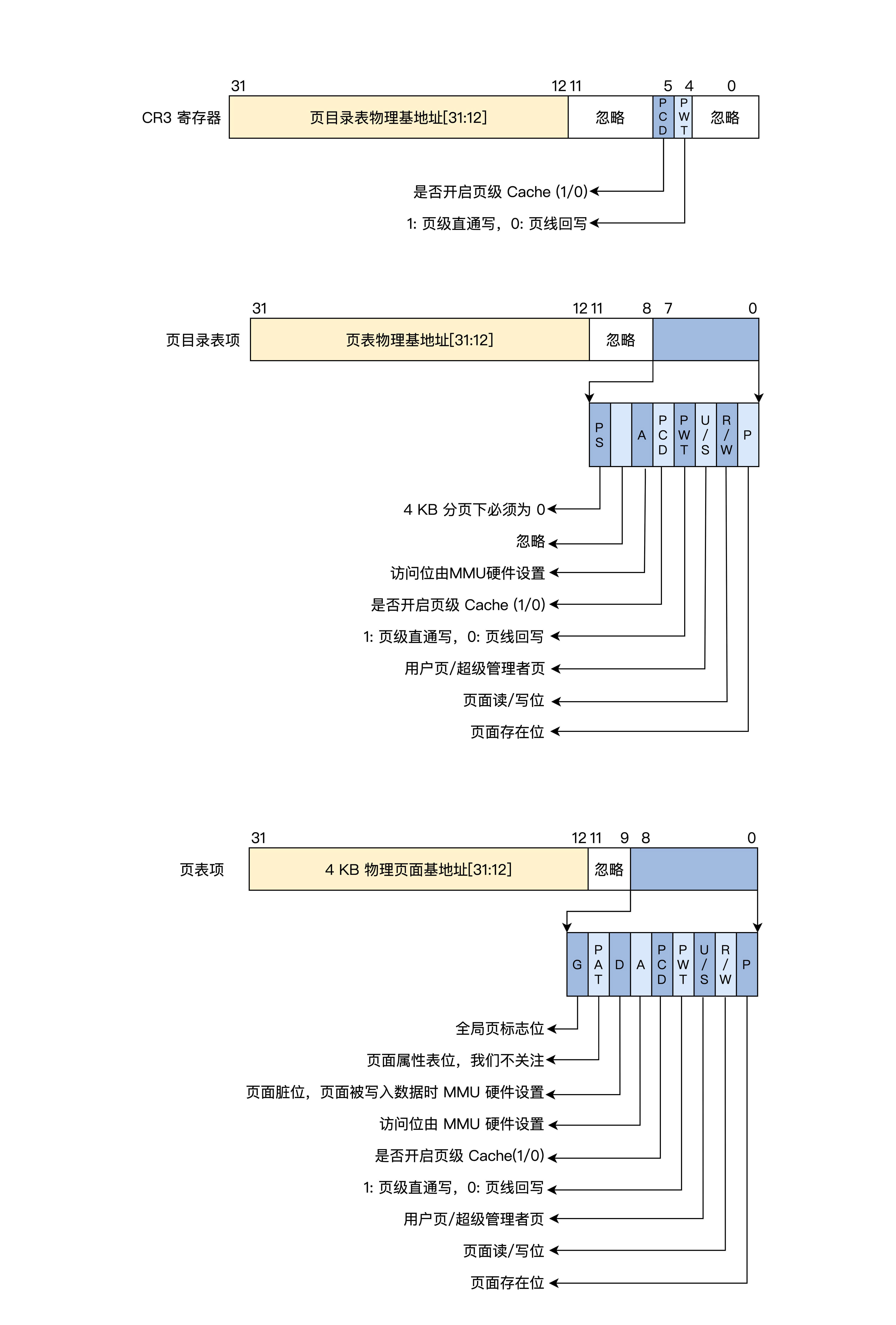
CR3寄存器、页目录项和页表项都是32位,所以低12位可以另做它用,形成了页面相关属性,如
是否存在,是否可读写、是否已访问等待
4MB页
该分页方式下,32位虚拟地址被分为2段:页表索引、页内偏移
共1024个条目,每个条目指向一个物理页4MB,正好为4GB地址空间
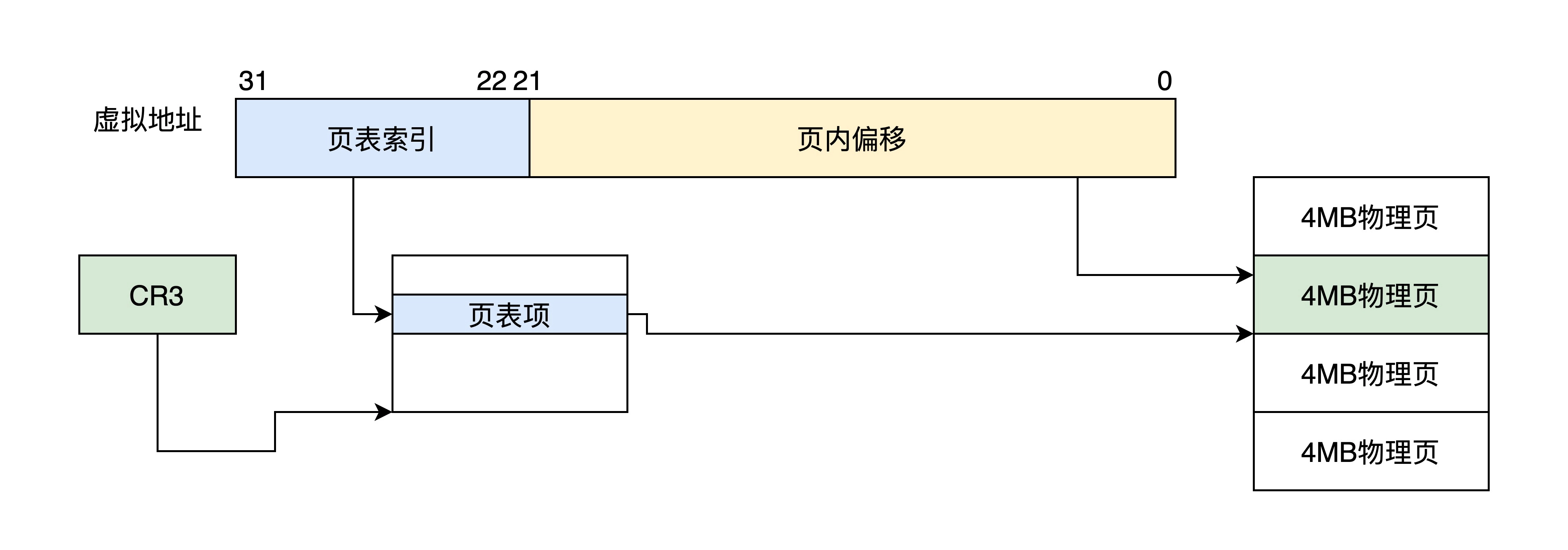
CR3还是32位寄存器,指向一个4KB大小的页表,仍然要4KB地址对齐,其中包含1024个页表项
长模式下的分页
长模式下扩展为64位
4KB页
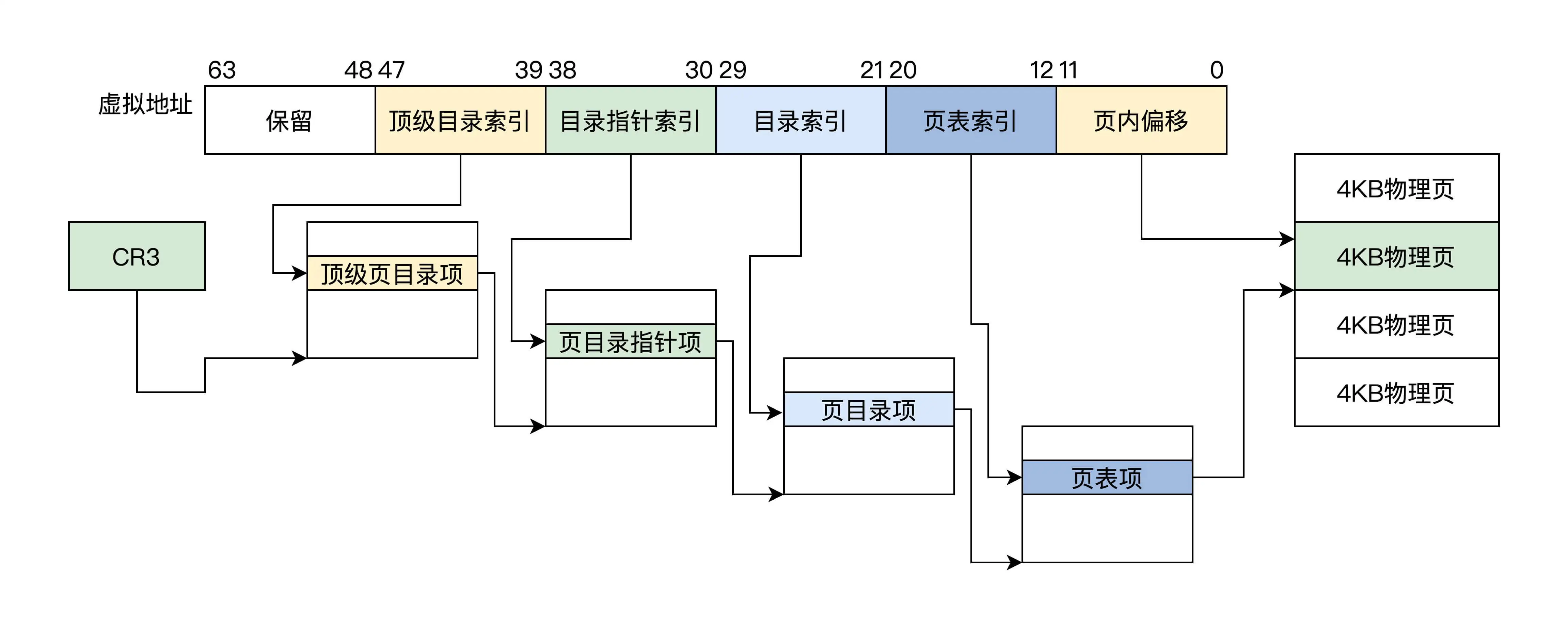
64位虚拟地址被分为6段
- 保留位段: 24位
- 顶级页目录索引段:9位
- 页目录指针段: 9位
- 页目录段:9位
- 页表段: 9位
- 页内偏移:12位
顶级页目录、页目录指针、页目录、页表都各占4KB, 各512个条目,每个条目8B即64位
因为x86 CPU并没有实现全64位的地址总线,而是只实现了48位,但寄存器却是64位的,
当第47位是1的时候48~63为1,反之为0
2MB页
该方式下分为5个分段
- 保留位段: 16位
- 顶级页目录索引:9位
- 页目录指针索引:9位
- 页目录索引:9位
- 页内偏移:21位
顶级页目录、页目录指针、页目录都各占4KB, 各512个条目,每个条目8B即64位
页表项被放弃,页目录项直接指定了2MB大小的物理页面
开启MMU
- 使CPU进入保护模式或长模式
- 准备页表数据
- 将顶级页目录的物理地址赋值给CR3寄存器
1
2
|
mov eax, PGAE_TLB_BADR ;页表物理地址
mov cr3, eax
|
- 将CPU的CR0的PE为设置为0,这样就开启了 MMU
1
2
3
4
5
|
;开启保护模式和分页模式
mov eax, cr0
bts eax, 0 ;CR0.PE = 1
bts eax, 31 ;CR0.P = 1
mov cr0, eax
|
第七讲:Cache与内存
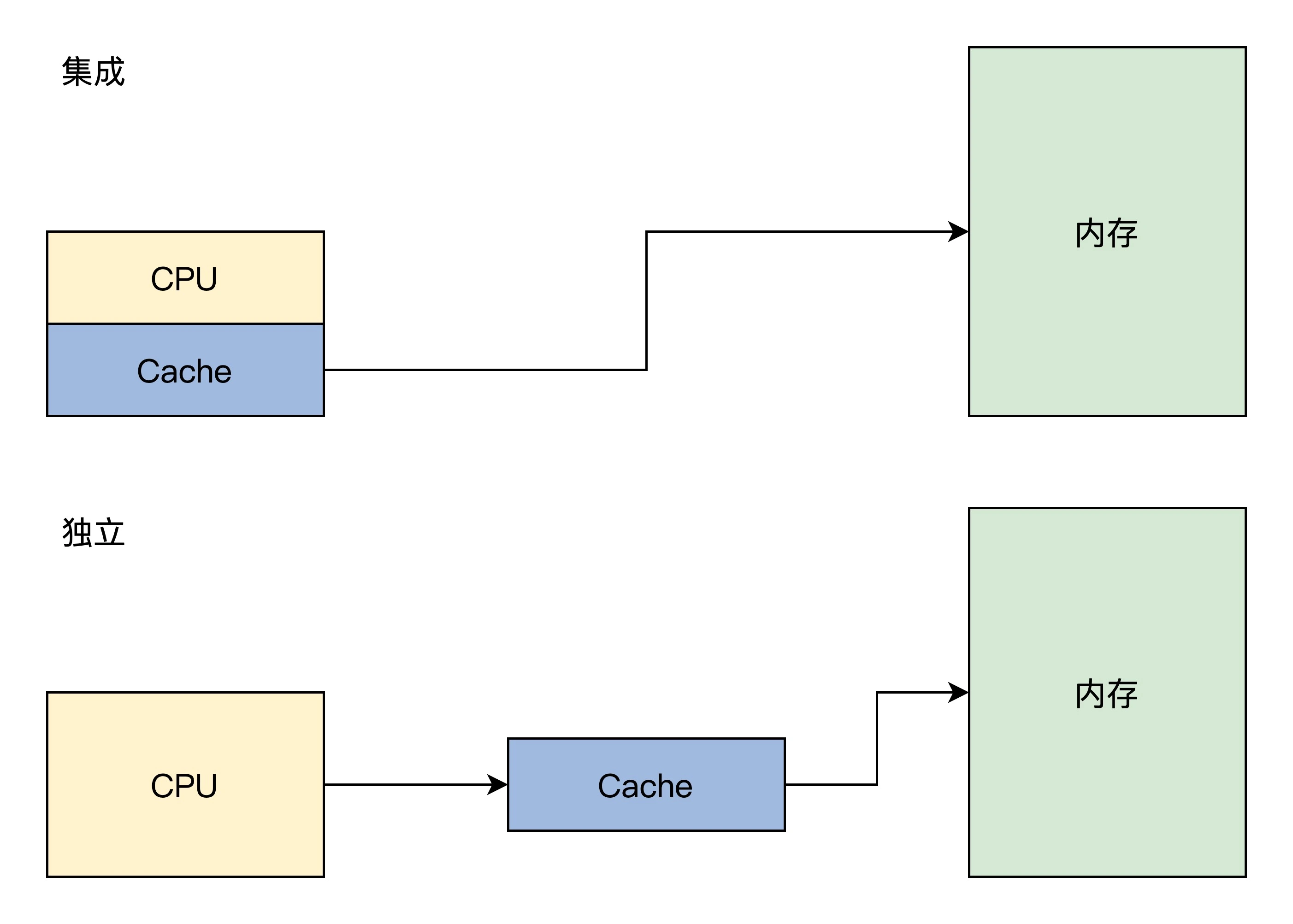
内存
控制内存读写和刷新的是内存控制器,内存控制器集成在北桥芯片中
由于制造工艺升级,现在北桥芯片被集成到了CPU芯片,这样大大提升了CPU访问内存的性能
Cache
通过程序的局部性原理可以知道CPU大多数时间在访问相同或者相近的地址
那么可以用一块小而快的存储器放在CPU和内存之间,来缓解CPU和内存的之间的性能差距
这个就称之为Cache
Cache中存放了部分内存数据,CPU在访问内存时要先访问Cache
现在的x86 CPU是将Cache集成在CPU内
Cache主要由高速的静态存储器、地址转换模块和行替换模块组成
Cache会把存储器分成若干行,每行32字节或64字节,和内存交换数据最小单位为一行
为了方便管理,多个行又会组成一组
除了正常数据外,行中还有一些标志位,如脏位、回写位等
Cache的大致工作流程如下:
- CPU发出的地址由Cache的地址转换模块分成3段:组号、行号和行内偏移
- Cache会根据组号、行号查找高速静态存储器中对应的行。如果找到即命中,用行内偏移读取并返回数据给CPU;
否则就分配一个新行并访问内存,把内存中对应的数据加载到Cache行并返回给CPU。
写入操作分为回写和直写,回写就是写入对应的Cache行即可,直写写入Cache行的同时会写入内存
- 如果容量不足,就要进入行替换逻辑,即找出一个Cache行写回内存,腾出空间。
Cache引入的问题
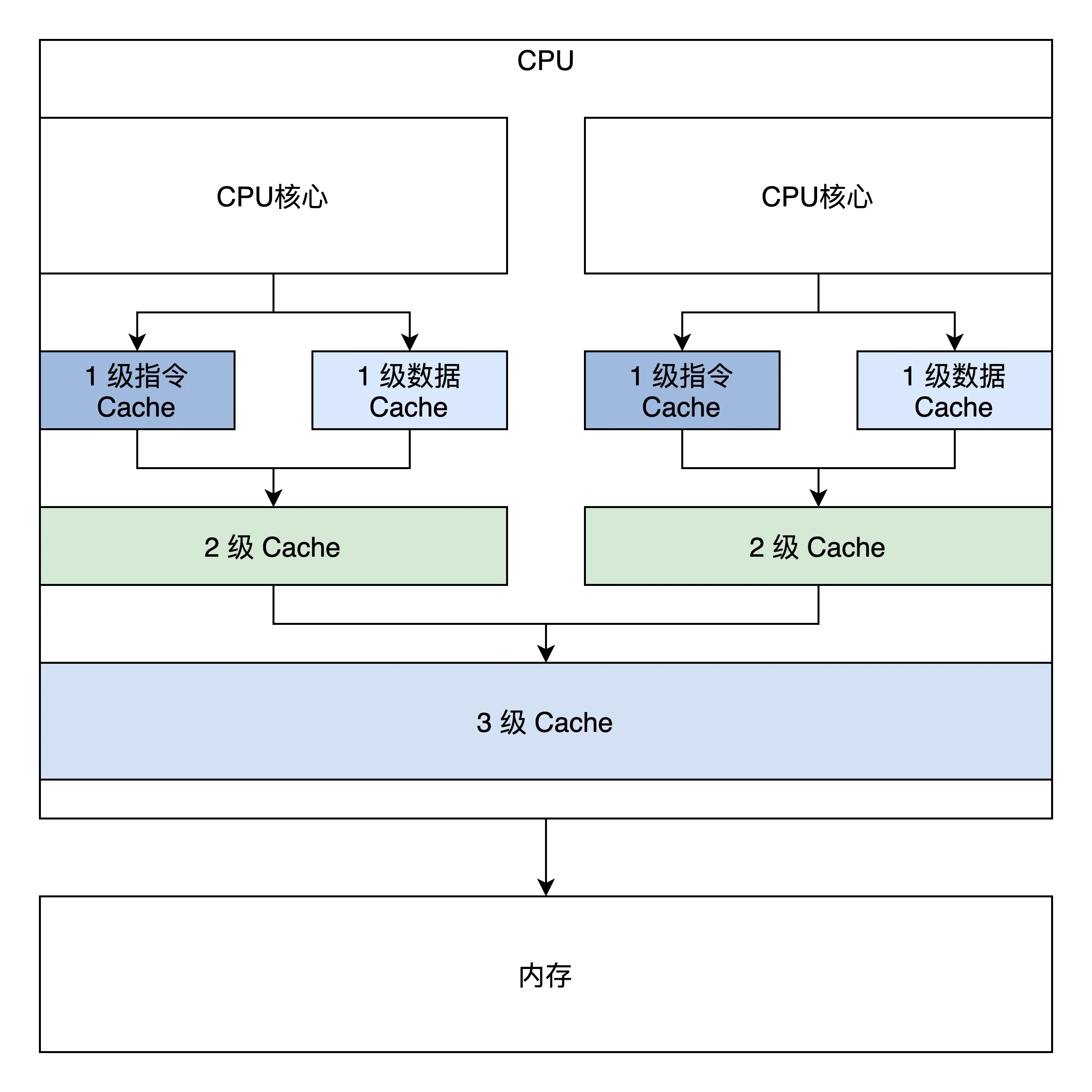
上图是简单的双核心CPU,有三级Cache,第一级Cache是指令和数据分开的,
第二级是独立于CPU核心的,第三级是所有CPU核心共享的。
Cache一致性问题主要包括以下三个:
- 一个CPU中指令Cache和数据Cache一致性的问题
- 多个CPU各自的2级Cache一致性问题
- 3级Cache与网卡、显存等设备存储之间的一致性问题
Cache的MESI协议
MESI协议定义了四种基本状态
-
Modified
当前Cache内容有效,但已和内存不一致,且不存在其他核心的Cache中
-
Exclusive
当前Cache内容有效,和内存一致,但不存在其他核心的Cache中
-
Shared
当前Cache内容有效,和内存一致,且在其他核心的Cache中也一至
- Invalid
其他情况,当前Cache无效
第八讲:锁-并发操作中如何让数据同步
方法一: 原子操作, 拿下单体变量
C语言可以嵌入汇编代码实现原子操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
//定义一个原子类型
typedef struct s_ATOMIC{
volatile s32_t a_count; //在变量前加上volatile,是为了禁止编译器优化,使其每次都从内存中加载变量
}atomic_t;
//原子读
static inline s32_t atomic_read(const atomic_t *v)
{
//x86平台取地址处是原子
return (*(volatile u32_t*)&(v)->a_count);
}
//原子写
static inline void atomic_write(atomic_t *v, int i)
{
//x86平台把一个值写入一个地址处也是原子的
v->a_count = i;
}
//原子加上一个整数
static inline void atomic_add(int i, atomic_t *v)
{
__asm__ __volatile__("lock;" "addl %1,%0"
: "+m" (v->a_count)
: "ir" (i));
}
//原子减去一个整数
static inline void atomic_sub(int i, atomic_t *v)
{
__asm__ __volatile__("lock;" "subl %1,%0"
: "+m" (v->a_count)
: "ir" (i));
}
//原子加1
static inline void atomic_inc(atomic_t *v)
{
__asm__ __volatile__("lock;" "incl %0"
: "+m" (v->a_count));
}
//原子减1
static inline void atomic_dec(atomic_t *v)
{
__asm__ __volatile__("lock;" "decl %0"
: "+m" (v->a_count));
}
|
加上lock前缀的addl、subl、incl、decl指令都是原子操作,lock前缀表示锁定总线,CPU能互斥使用特定的内存地址
代码模板以__asm__ __volatile开始,后面括号内容分为四个部分,以:分割
以atomic_add举例:
- 汇编代码,
"lock"; "add %1, %0"
- 输出列表,
"+m" (v->a_count),"+m"表示输出和内存地址关联
- 输入列表,
"ir", “r"表示输入i和寄存器关联
- 损坏部分,告诉编译器使用了哪些寄存器,以便保存和恢复寄存器的值
方法二: 中断控制,搞定复杂变量
x86 使用cli、sti 指令关闭和开启中断,它们主要是对CPU的eflags寄存器的IF位(第9位)进行
清除和设置,CPU通过此位来决定是否响应中断信号
1
2
3
4
5
6
7
8
9
10
11
|
// 关闭中断
void hal_cli()
{
__asm__ __volatile__("cli": : :"memory");
}
// 开启中断
void hal_sti()
{
__asm__ __volatile__("sti": : :"memory");
}
|
上面这种方式不支持嵌套调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
void foo()
{
hal_cli();
...
hal_sti();
}
void bar()
{
hal_cli();
foo();
...
hal_sti();
}
|
解决方案为:
- 关闭中断函数先保存eflags寄存器,然后执行cli指令
- 开启中断函数恢复保存的eflags寄存器的值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
typedef u32_t cpuflg_t;
static inline void hal_save_flags_cli(cpuflg_t* flags)
{
__asm__ __volatile__(
"pushfl \t\n" //把eflags寄存器压入当前栈顶
"cli \t\n" //关闭中断
"popl %0 \t\n"//把当前栈顶弹出到eflags为地址的内存中
: "=m"(*flags)
:
: "memory"
);
}
static inline void hal_restore_flags_sti(cpuflg_t* flags)
{
__asm__ __volatile__(
"pushl %0 \t\n"//把flags为地址处的值寄存器压入当前栈顶
"popfl \t\n" //把当前栈顶弹出到eflags寄存器中
:
: "m"(*flags)
: "memory"
);
}
|
方法三: 自旋锁,协调多核心CPU
控制中断只能控制当前CPU的中断,不能控制其他CPU的中断
自旋锁原理如下图所示:
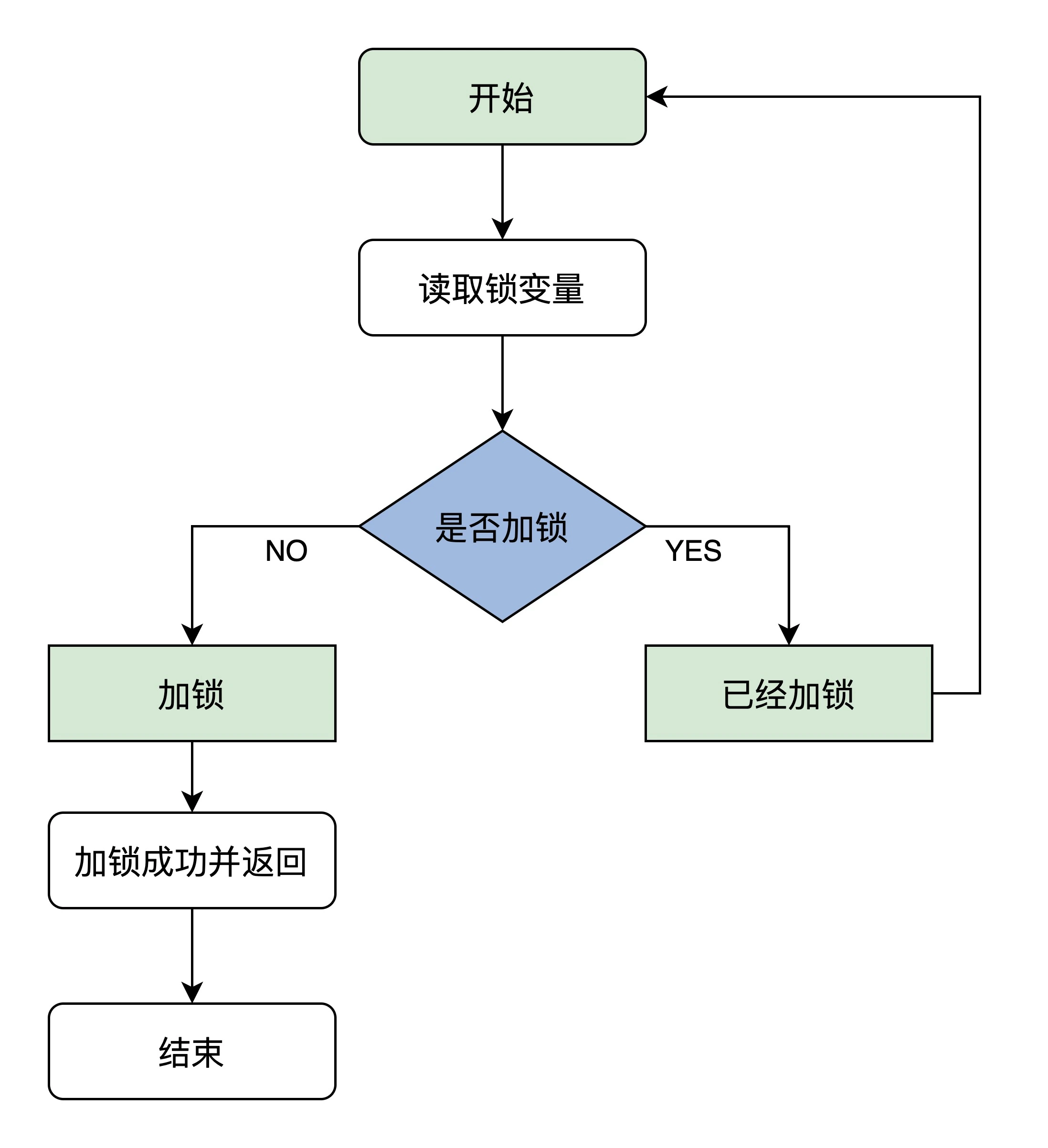
如果需要正确执行,需要保证读取锁变量和判断并加锁的操作是原子的
x86 提供了一个原子交换指令xchg,它可以让寄存器的值和内存空间的值进行交换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
//自旋锁结构
typedef struct
{
volatile u32_t lock;//volatile可以防止编译器优化,保证其它代码始终从内存加载lock变量的值
} spinlock_t;
//锁初始化函数
static inline void x86_spin_lock_init(spinlock_t * lock)
{
lock->lock = 0;//锁值初始化为0是未加锁状态
}
//加锁函数
static inline void x86_spin_lock(spinlock_t * lock)
{
__asm__ __volatile__ (
"1: \n"
"lock; xchg %0, %1 \n"//把值为1的寄存器和lock内存中的值进行交换
"cmpl $0, %0 \n" //用0和交换回来的值进行比较
"jnz 2f \n" //不等于0则跳转后面2标号处运行
"jmp 3f \n" //若等于0则跳转后面3标号处返回
"2: \n"
"cmpl $0, %1 \n"//用0和lock内存中的值进行比较
"jne 2b \n"//若不等于0则跳转到前面2标号处运行继续比较
"jmp 1b \n"//若等于0则跳转到前面1标号处运行,交换并加锁
"3: \n"
:
: "r"(1),
"m"(*lock));
}
//解锁函数
static inline void x86_spin_unlock(spinlock_t * lock)
{
__asm__ __volatile__(
"movl $0, %0\n"//解锁把lock内存中的值设为0就行
:
: "m"(*lock));
}
|
xchg %0, %1其中 %0 对应"r"(1),表示编译器自动分配一个通用寄存器,并填入值1;
而 %1对应"m"(*lock),表示lock是内存地址。
把1和内存的值交换,如果内存值是1,则不影响,否则已交换内存就变成了1,即加锁成功。
自旋锁需要在处理中断的过程中也能使用,所以需要改进
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
static inline void x86_spin_lock_disable_irq(spinlock_t * lock,cpuflg_t* flags)
{
__asm__ __volatile__(
"pushfq \n\t"
"cli \n\t"
"popq %0 \n\t"
"1: \n\t"
"lock; xchg %1, %2 \n\t"
"cmpl $0,%1 \n\t"
"jnz 2f \n\t"
"jmp 3f \n"
"2: \n\t"
"cmpl $0,%2 \n\t"
"jne 2b \n\t"
"jmp 1b \n\t"
"3: \n"
:"=m"(*flags)
: "r"(1), "m"(*lock));
}
static inline void x86_spin_unlock_enabled_irq(spinlock_t* lock,cpuflg_t* flags)
{
__asm__ __volatile__(
"movl $0, %0\n\t"
"pushq %1 \n\t"
"popfq \n\t"
:
: "m"(*lock), "m"(*flags));
}
|
方法四: 信号量,时间管理大师
信号量可以对资源进行保护,同一时刻只有一个代码执行流,又能在资源无法满足的情况下,让CPU执行其他任务
信号量数据结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#define SEM_FLG_MUTEX 0
#define SEM_FLG_MULTI 1
#define SEM_MUTEX_ONE_LOCK 1
#define SEM_MULTI_LOCK 0
//等待链数据结构,用于挂载等待代码执行流(线程)的结构,里面有用于挂载代码执行流的链表和计数器变量,这里我们先不深入研究这个数据结构。
typedef struct s_KWLST
{
spinlock_t wl_lock;
uint_t wl_tdnr;
list_h_t wl_list;
}kwlst_t;
//信号量数据结构
typedef struct s_SEM
{
spinlock_t sem_lock;//维护sem_t自身数据的自旋锁
uint_t sem_flg;//信号量相关的标志
sint_t sem_count;//信号量计数值
kwlst_t sem_waitlst;//用于挂载等待代码执行流(线程)结构
}sem_t;
|
假定信号量sem_count初始化为1,等待链sem_waitlst初始化为空
信号量的获取down和释放up的代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
//获取信号量
void krlsem_down(sem_t* sem)
{
cpuflg_t cpufg;
start_step:
krlspinlock_cli(&sem->sem_lock,&cpufg);//获取自旋锁
if(sem->sem_count<1)
{//如果信号量值小于1,则让代码执行流(线程)睡眠
krlwlst_wait(&sem->sem_waitlst);
krlspinunlock_sti(&sem->sem_lock,&cpufg);
krlschedul();//切换代码执行流,下次恢复执行时依然从下一行开始执行,所以要goto开始处重新获取信号量
goto start_step;
}
sem->sem_count--;//信号量值减1,表示成功获取信号量
krlspinunlock_sti(&sem->sem_lock,&cpufg);//释放自旋锁
return;
}
//释放信号量
void krlsem_up(sem_t* sem)
{
cpuflg_t cpufg;
krlspinlock_cli(&sem->sem_lock,&cpufg); //获取自旋锁
sem->sem_count++;//释放信号量
if(sem->sem_count<1)
{//如果小于1,则说数据结构出错了,挂起系统
krlspinunlock_sti(&sem->sem_lock,&cpufg);
hal_sysdie("sem up err");
}
//唤醒该信号量上所有等待的代码执行流(线程)
krlwlst_allup(&sem->sem_waitlst);
krlspinunlock_sti(&sem->sem_lock,&cpufg);
krlsched_set_schedflgs();
return;
}
|
获取信号量
- 对用于保护信号量本身的自旋锁sem_lock加锁
- 判断sem_count的值: 如果小于1则让进程进入等待状态并将其挂入sem_waitlst;
否则表示信号量获取成功,将sem_count-1,并释放自旋锁
释放信号量
- 对用于保护信号量本身的自旋锁sem_lock加锁
- 对sem_count+1
- 唤醒sem_waitlst的进程,释放自旋锁
第九讲 Linux的并发实现
原子变量
Linux提供了一个原子类型变量atomic_t
1
2
3
4
5
6
7
8
9
|
tyepedef struct
{
int counter;
} atomic_t;
typedef struct
{
s64 counter;
} atomic64_t;
|
操作函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
//原子读取变量中的值
static __always_inline int arch_atomic_read(const atomic_t *v)
{
return __READ_ONCE((v)->counter);
}
//原子写入一个具体的值
static __always_inline void arch_atomic_set(atomic_t *v, int i)
{
__WRITE_ONCE(v->counter, i);
}
//原子加上一个具体的值
static __always_inline void arch_atomic_add(int i, atomic_t *v)
{
asm volatile(LOCK_PREFIX "addl %1,%0"
: "+m" (v->counter)
: "ir" (i) : "memory");
}
//原子减去一个具体的值
static __always_inline void arch_atomic_sub(int i, atomic_t *v)
{
asm volatile(LOCK_PREFIX "subl %1,%0"
: "+m" (v->counter)
: "ir" (i) : "memory");
}
//原子加1
static __always_inline void arch_atomic_inc(atomic_t *v)
{
asm volatile(LOCK_PREFIX "incl %0"
: "+m" (v->counter) :: "memory");
}
//原子减1
static __always_inline void arch_atomic_dec(atomic_t *v)
{
asm volatile(LOCK_PREFIX "decl %0"
: "+m" (v->counter) :: "memory");
}
#define __READ_ONCE(x) \
(*(const volatile __unqual_scalar_typeof(x) *)&(x))
#define __WRITE_ONCE(x, val) \
do {*(volatile typeof(x) *)&(x) = (val);} while (0)
//__unqual_scalar_typeof表示声明一个非限定的标量类型,非标量类型保持不变。说人话就是返回x变量的类型,这是GCC的功能,typeof只是纯粹返回x的类型。
//如果 x 是int类型则返回“int”
#define __READ_ONCE(x) \
(*(const volatile int *)&(x))
#define __WRITE_ONCE(x, val) \
do {*(volatile int *)&(x) = (val);} while (0)
|
中断控制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
//实际保存eflags寄存器
extern __always_inline unsigned long native_save_fl(void){
unsigned long flags;
asm volatile("# __raw_save_flags\n\t"
"pushf ; pop %0":"=rm"(flags)::"memory");
return flags;
}
//实际恢复eflags寄存器
extern inline void native_restore_fl(unsigned long flags){
asm volatile("push %0 ; popf"::"g"(flags):"memory","cc");
}
//实际关中断
static __always_inline void native_irq_disable(void){
asm volatile("cli":::"memory");
}
//实际开启中断
static __always_inline void native_irq_enable(void){
asm volatile("sti":::"memory");
}
//arch层关中断
static __always_inline void arch_local_irq_disable(void){
native_irq_disable();
}
//arch层开启中断
static __always_inline void arch_local_irq_enable(void){
native_irq_enable();
}
//arch层保存eflags寄存器
static __always_inline unsigned long arch_local_save_flags(void){
return native_save_fl();
}
//arch层恢复eflags寄存器
static __always_inline void arch_local_irq_restore(unsigned long flags){
native_restore_fl(flags);
}
//实际保存eflags寄存器并关中断
static __always_inline unsigned long arch_local_irq_save(void){
unsigned long flags = arch_local_save_flags();
arch_local_irq_disable();
return flags;
}
//raw层关闭开启中断宏
#define raw_local_irq_disable() arch_local_irq_disable()
#define raw_local_irq_enable() arch_local_irq_enable()
//raw层保存恢复eflags寄存器宏
#define raw_local_irq_save(flags) \
do { \
typecheck(unsigned long, flags); \
flags = arch_local_irq_save(); \
} while (0)
#define raw_local_irq_restore(flags) \
do { \
typecheck(unsigned long, flags); \
arch_local_irq_restore(flags); \
} while (0)
#define raw_local_save_flags(flags) \
do { \
typecheck(unsigned long, flags); \
flags = arch_local_save_flags(); \
} while (0)
//通用层接口宏
#define local_irq_enable() \
do { \
raw_local_irq_enable(); \
} while (0)
#define local_irq_disable() \
do { \
raw_local_irq_disable(); \
} while (0)
#define local_irq_save(flags) \
do { \
raw_local_irq_save(flags); \
} while (0)
#define local_irq_restore(flags) \
do { \
raw_local_irq_restore(flags); \
} while (0)
|
do{}while(0)表达式会保证{}中的代码片段执行一次,保证宏展开时这个代码片段是一个整体
自旋锁
Linux自旋锁有多种实现,下面介绍两种
原始自旋锁
数据结构
1
2
3
|
typedef struct {
volatile unsigned long lock;
} spinlock_t;
|
函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
#define spin_unlock_string \
"movb $1,%0" \ //写入1表示解锁
:"=m" (lock->lock) : : "memory"
#define spin_lock_string \
"\n1:\t" \
"lock ; decb %0\n\t" \ //原子减1
"js 2f\n" \ //当结果小于0则跳转到标号2处,表示加锁失败
".section .text.lock,\"ax\"\n" \ //重新定义一个代码段,这是优化技术,避免后面的代码填充cache,因为大部分情况会加锁成功,链接器会处理好这个代码段的
"2:\t" \
"cmpb $0,%0\n\t" \ //和0比较
"rep;nop\n\t" \ //空指令
"jle 2b\n\t" \ //小于或等于0跳转到标号2
"jmp 1b\n" \ //跳转到标号1
".previous"
//获取自旋锁
static inline void spin_lock(spinlock_t*lock){
__asm__ __volatile__(
spin_lock_string
:"=m"(lock->lock)::"memory"
);
}
//释放自旋锁
static inline void spin_unlock(spinlock_t*lock){
__asm__ __volatile__(
spin_unlock_string
);
}
|
spin_unlock_string只是简单将锁值设置为1,表示释放自旋锁
spin_lock_string使用了decb原子减一指令,如果结果为0表示加锁成功;否则
进入循环比较
当有多个进程同时等在自旋锁时,后续获取锁的进程是不确定的,
取决于内存总线协议决定哪个CPU核心可以访问内存
排队自旋锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
//RAW层的自旋锁数据结构
typedef struct raw_spinlock{
unsigned int slock;//真正的锁值变量
}raw_spinlock_t;
//最上层的自旋锁数据结构
typedef struct spinlock{
struct raw_spinlock rlock;
}spinlock_t;
//Linux没有这样的结构,这只是为了描述方便
typedef struct raw_spinlock{
union {
unsigned int slock;//真正的锁值变量
}
}raw_spinlock_t;
|
slock域被分为两部分,分别保存锁持有者owner(低16位)和未来锁申请者next(高16位)的序号
只有next域和owner域相等时,才表示处于未使用的状态
slock初始值为0,即next和owner被置为0
进程申请自旋锁时,将next域加1,并将原值作为自己的序号
如果序号等于申请时的owner的值,说明自旋锁处于未使用的状态,则进程直接获得锁;
否则,该进程循环检查owner域是否等于自己持有的序号,一旦相等则表名锁轮到自己获取
进程释放锁时,原子的将owner域加 1 即可,下一个进程会发现这个变化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
static inline void __raw_spin_lock(raw_spinlock_t*lock){
int inc = 0x00010000;
int tmp;
__asm__ __volatile__(
"lock ; xaddl %0, %1\n" //将inc和slock交换,然后 inc=inc+slock
//相当于原子读取next和owner并对next+1
"movzwl %w0, %2\n\t"//将inc的低16位做0扩展后送tmp tmp=(u16)inc
"shrl $16, %0\n\t" //将inc右移16位 inc=inc>>16
"1:\t"
"cmpl %0, %2\n\t" //比较inc和tmp,即比较next和owner
"je 2f\n\t" //相等则跳转到标号2处返回
"rep ; nop\n\t" //空指令
"movzwl %1, %2\n\t" //将slock的低16位做0扩展后送tmp 即tmp=owner
"jmp 1b\n" //跳转到标号1处继续比较
"2:"
:"+Q"(inc),"+m"(lock->slock),"=r"(tmp)
::"memory","cc"
);
}
#define UNLOCK_LOCK_PREFIX LOCK_PREFIX
static inline void __raw_spin_unlock(raw_spinlock_t*lock){
__asm__ __volatile__(
UNLOCK_LOCK_PREFIX"incw %0"//将slock的低16位加1 即owner+1
:"+m"(lock->slock)
::"memory","cc");
}
|
try_lock实现当无法立即获取自旋锁时,资源放弃
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
static inline int __raw_spin_trylock(raw_spinlock_t*lock){
int tmp;
int new;
asm volatile(
"movl %2,%0\n\t"//tmp=slock
"movl %0,%1\n\t"//new=tmp
"roll $16, %0\n\t"//tmp循环左移16位,即next和owner交换了
"cmpl %0,%1\n\t"//比较tmp和new即(owner、next)?=(next、owner)
"jne 1f\n\t" //不等则跳转到标号1处
"addl $0x00010000, %1\n\t"//相当于next+1
"lock ; cmpxchgl %1,%2\n\t"//new和slock交换比较
"1:"
"sete %b1\n\t" //new = eflags.ZF位,ZF取决于前面的判断是否相等
"movzbl %b1,%0\n\t" //tmp = new
:"=&a"(tmp),"=Q"(new),"+m"(lock->slock)
::"memory","cc");
return tmp;
}
int __lockfunc _spin_trylock(spinlock_t*lock){
preempt_disable();
if(_raw_spin_trylock(lock)){
spin_acquire(&lock->dep_map,0,1,_RET_IP_);
return 1;
}
preempt_enable();
return 0;
}
#define spin_trylock(lock) __cond_lock(lock, _spin_trylock(lock))
|
_spin_trylock返回1表示尝试加锁成功
信号量
信号量可以分为单值信号量和多值信号量
信号量最大的优势是即可以是申请失败的进程睡眠,又可以作为资源计数器使用
1
2
3
4
5
6
|
struct semaphore
{
raw_spinlock_t lock; // 保护信号量自身的自旋锁
unsigned int count; // 信号量值
struct list_head wait_list; //挂载睡眠等待进程的链表
}
|
接口函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
static inline int __sched __down_common(struct semaphore *sem, long state,long timeout)
{
struct semaphore_waiter waiter;
//把waiter加入sem->wait_list的头部
list_add_tail(&waiter.list, &sem->wait_list);
waiter.task = current;//current表示当前进程,即调用该函数的进程
waiter.up = false;
for (;;) {
if (signal_pending_state(state, current))
goto interrupted;
if (unlikely(timeout <= 0))
goto timed_out;
__set_current_state(state);//设置当前进程的状态,进程睡眠,即先前__down函数中传入的TASK_UNINTERRUPTIBLE:该状态是等待资源有效时唤醒(比如等待键盘输入、socket连接、信号(signal)等等),但不可以被中断唤醒
raw_spin_unlock_irq(&sem->lock);//释放在down函数中加的锁
timeout = schedule_timeout(timeout);//真正进入睡眠
raw_spin_lock_irq(&sem->lock);//进程下次运行会回到这里,所以要加锁
if (waiter.up)
return 0;
}
timed_out:
list_del(&waiter.list);
return -ETIME;
interrupted:
list_del(&waiter.list);
return -EINTR;
//为了简单起见处理进程信号(signal)和超时的逻辑代码我已经删除
}
//进入睡眠等待
static noinline void __sched __down(struct semaphore *sem)
{
__down_common(sem, TASK_UNINTERRUPTIBLE, MAX_SCHEDULE_TIMEOUT);
}
//获取信号量
void down(struct semaphore *sem)
{
unsigned long flags;
//对信号量本身加锁并关中断,也许另一段代码也在操作该信号量
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;//如果信号量值大于0,则对其减1
else
__down(sem);//否则让当前进程进入睡眠
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
//实际唤醒进程
static noinline void __sched __up(struct semaphore *sem)
{
struct semaphore_waiter *waiter = list_first_entry(&sem->wait_list, struct semaphore_waiter, list);
//获取信号量等待链表中的第一个数据结构semaphore_waiter,它里面保存着睡眠进程的指针
list_del(&waiter->list);
waiter->up = true;
wake_up_process(waiter->task);//唤醒进程重新加入调度队列
}
//释放信号量
void up(struct semaphore *sem)
{
unsigned long flags;
//对信号量本身加锁并关中断,必须另一段代码也在操作该信号量
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(list_empty(&sem->wait_list)))
sem->count++;//如果信号量等待链表中为空,则对信号量值加1
else
__up(sem);//否则执行唤醒进程相关的操作
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
|
读写锁
读写之间是互斥的,读写竞争锁时,写会优先得到锁
读写锁本质上是自旋锁的变种,是带计数的自旋锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
//读写锁初始化锁值
#define RW_LOCK_BIAS 0x01000000
//读写锁的底层数据结构
typedef struct{
unsigned int lock;
}arch_rwlock_t;
//释放读锁
static inline void arch_read_unlock(arch_rwlock_t*rw){
asm volatile(
LOCK_PREFIX"incl %0" //原子对lock加1
:"+m"(rw->lock)::"memory");
}
//释放写锁
static inline void arch_write_unlock(arch_rwlock_t*rw){
asm volatile(
LOCK_PREFIX"addl %1, %0"//原子对lock加上RW_LOCK_BIAS
:"+m"(rw->lock):"i"(RW_LOCK_BIAS):"memory");
}
//获取写锁失败时调用
ENTRY(__write_lock_failed)
//(%eax)表示由eax指向的内存空间是调用者传进来的
2:LOCK_PREFIX addl $ RW_LOCK_BIAS,(%eax)
1:rep;nop//空指令
cmpl $RW_LOCK_BIAS,(%eax)
//不等于初始值则循环比较,相等则表示有进程释放了写锁
jne 1b
//执行加写锁
LOCK_PREFIX subl $ RW_LOCK_BIAS,(%eax)
jnz 2b //不为0则继续测试,为0则表示加写锁成功
ret //返回
ENDPROC(__write_lock_failed)
//获取读锁失败时调用
ENTRY(__read_lock_failed)
//(%eax)表示由eax指向的内存空间是调用者传进来的
2:LOCK_PREFIX incl(%eax)//原子加1
1: rep; nop//空指令
cmpl $1,(%eax) //和1比较 小于0则
js 1b //为负则继续循环比较
LOCK_PREFIX decl(%eax) //加读锁
js 2b //为负则继续加1并比较,否则返回
ret //返回
ENDPROC(__read_lock_failed)
//获取读锁
static inline void arch_read_lock(arch_rwlock_t*rw){
asm volatile(
LOCK_PREFIX" subl $1,(%0)\n\t"//原子对lock减1
"jns 1f\n"//不为小于0则跳转标号1处,表示获取读锁成功
"call __read_lock_failed\n\t"//调用__read_lock_failed
"1:\n"
::LOCK_PTR_REG(rw):"memory");
}
//获取写锁
static inline void arch_write_lock(arch_rwlock_t*rw){
asm volatile(
LOCK_PREFIX"subl %1,(%0)\n\t"//原子对lock减去RW_LOCK_BIAS
"jz 1f\n"//为0则跳转标号1处
"call __write_lock_failed\n\t"//调用__write_lock_failed
"1:\n"
::LOCK_PTR_REG(rw),"i"(RW_LOCK_BIAS):"memory");
}
|
计数器lock的初始值为0x01000000
-
获取读锁时,lock加1,判断lock的符号位是否为0(即lock是否大于0)为0则表示加锁成功;
否则表示获取读锁失败,此时调用__read_lock_failed,循环测试lock+1>=1
-
获取写时,lock减去初始值,判断lock是否为0,如果不为0则调用__write_lock_failed循环测试lock+0x01000000 == 0x01000000
第十讲:设置工作模式和环境
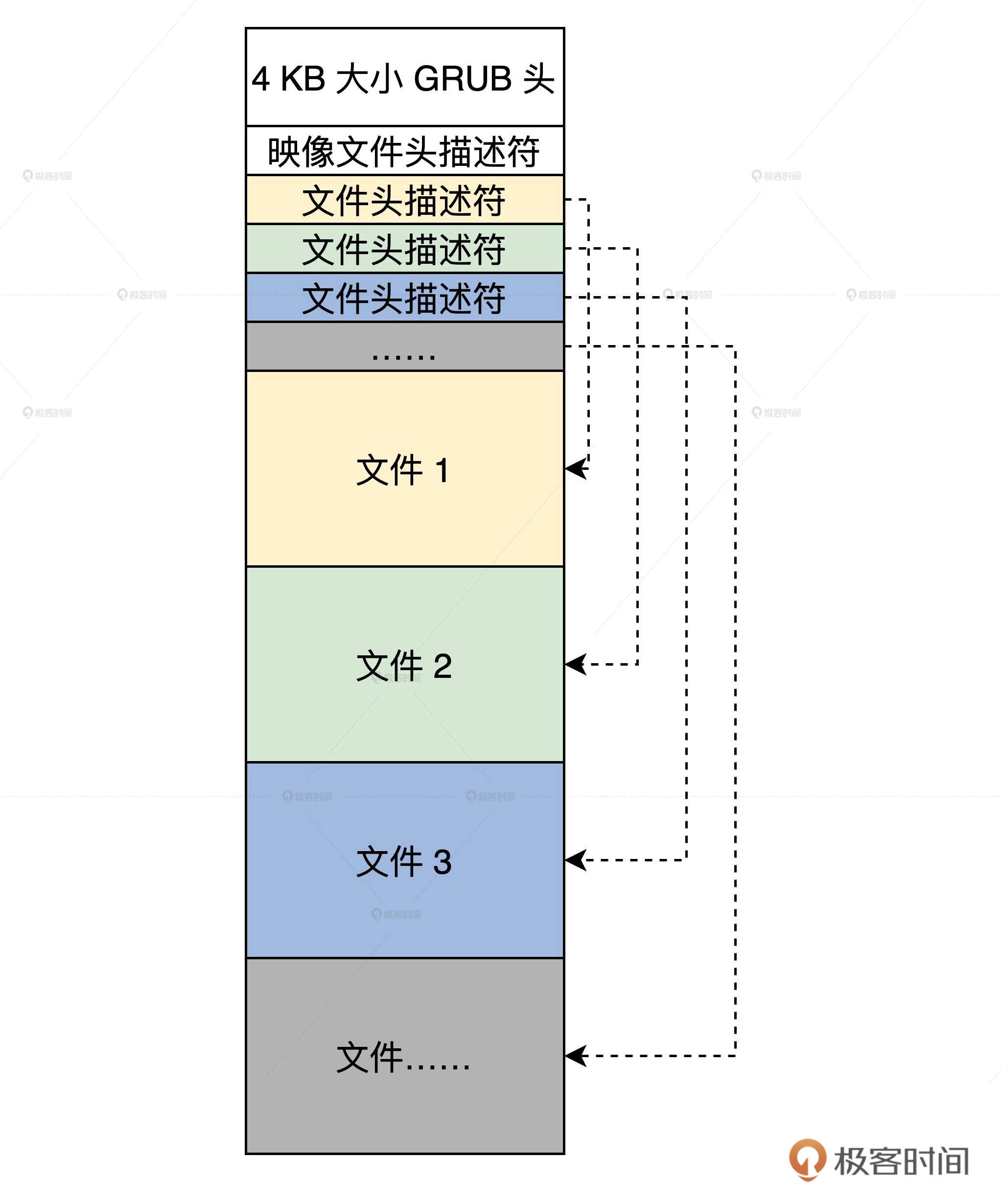
内核映像文件
内核映像文件是由多个文件封装的一个文件,其中包含二级引导器的模块,内核模块,图片和文字库文件等。
GRUB通过上图中的4KB的GRUB头来识别映像文件,然后根据映像文件头描述符和文件头描述符的信息解析其他文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
//映像文件头描述符
typedef struct s_mlosrddsc
{
u64_t mdc_mgic; //映像文件标识
u64_t mdc_sfsum;//未使用
u64_t mdc_sfsoff;//未使用
u64_t mdc_sfeoff;//未使用
u64_t mdc_sfrlsz;//未使用
u64_t mdc_ldrbk_s;//映像文件中二级引导器的开始偏移
u64_t mdc_ldrbk_e;//映像文件中二级引导器的结束偏移
u64_t mdc_ldrbk_rsz;//映像文件中二级引导器的实际大小
u64_t mdc_ldrbk_sum;//映像文件中二级引导器的校验和
u64_t mdc_fhdbk_s;//映像文件中文件头描述的开始偏移
u64_t mdc_fhdbk_e;//映像文件中文件头描述的结束偏移
u64_t mdc_fhdbk_rsz;//映像文件中文件头描述的实际大小
u64_t mdc_fhdbk_sum;//映像文件中文件头描述的校验和
u64_t mdc_filbk_s;//映像文件中文件数据的开始偏移
u64_t mdc_filbk_e;//映像文件中文件数据的结束偏移
u64_t mdc_filbk_rsz;//映像文件中文件数据的实际大小
u64_t mdc_filbk_sum;//映像文件中文件数据的校验和
u64_t mdc_ldrcodenr;//映像文件中二级引导器的文件头描述符的索引号
u64_t mdc_fhdnr;//映像文件中文件头描述符有多少个
u64_t mdc_filnr;//映像文件中文件头有多少个
u64_t mdc_endgic;//映像文件结束标识
u64_t mdc_rv;//映像文件版本
}mlosrddsc_t;
#define FHDSC_NMAX 192 //文件名长度
//文件头描述符
typedef struct s_fhdsc
{
u64_t fhd_type;//文件类型
u64_t fhd_subtype;//文件子类型
u64_t fhd_stuts;//文件状态
u64_t fhd_id;//文件id
u64_t fhd_intsfsoff;//文件在映像文件位置开始偏移
u64_t fhd_intsfend;//文件在映像文件的结束偏移
u64_t fhd_frealsz;//文件实际大小
u64_t fhd_fsum;//文件校验和
char fhd_name[FHDSC_NMAX];//文件名
}fhdsc_t;
|
内核映像文件使用lmoskrlimg打包
1
2
3
4
5
6
|
lmoskrlimg -m k -lhf GRUB头文件 -o 映像文件 -f 输入的文件列表
-m 表示模式 只能是k内核模式
-lhf 表示后面跟上GRUB头文件
-o 表示输出的映像文件名
-f 表示输入文件列表
#例如:lmoskrlimg -m k -lhf grubhead.bin -o kernel.img -f file1.bin file2.bin file3.bin file4.bin
|
准备环境
安装虚拟机
使用virtual box虚拟机
准备硬盘
生成纯二进制文件
1
2
3
4
5
6
7
|
dd bs=512 if=/dev/zero of=hd.img count=204800
#bs:表示块大小,这里是512字节
#if:表示输入文件,/dev/zero就是Linux下专门返回0数据的设备文件,读取它就返回0
#of:表示输出文件,即我们的硬盘文件。
#count:表示输出多少块
|
格式化(建立文件系统)
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 1. 将文件变成回环设备
# loop0可能被占用,换成其他名字即可
sudo losetup /dev/loop0 hd.img
# 2. 建立文件系统
sudo mkfs.ext4 -q /dev/loop0
# 3. 挂载
# 挂载硬盘文件, 可通过 lsblk 命令验证结果
sudo mount -o loop ./hd.img ./hdisk
# 建立boot目录
sudo mkdir ./hdist/boot
|
安装GRUB
- 安装GRUB
1
2
3
4
5
|
# 安装GRUB
sudo grub-install --boot-directory=./hdisk/boot/ --force --allow-floppy /dev/loop0
# --boot-directory 指向先前我们在虚拟硬盘中建立的boot目录。
# --force --allow-floppy :指向我们的虚拟硬盘设备文件/dev/loop0
|
- 编写配置文件
在 /hdisk/boot/grub/ 目录建立 grub.config 文件
1
2
3
4
5
6
7
8
9
10
11
|
menuentry 'HelloOS' {
insmod part_msdos
insmod ext2
set root='hd0,msdos1' #我们的硬盘只有一个分区所以是'hd0,msdos1'
multiboot2 /boot/HelloOS.eki #加载boot目录下的HelloOS.eki文件
boot #引导启动
}
set timeout_style=menu
if [ "${timeout}" = 0 ]; then
set timeout=10 #等待10秒钟自动启动
fi
|
转成硬盘格式
将Linux识别的硬盘 转换成虚拟机识别的硬盘
VBoxManage是在宿主机执行,文件可通过共享文件夹传输
1
2
3
|
VBoxManage convertfromraw ./hd.img --format VDI ./hd.vdi
#convertfromraw 指向原始格式文件
#--format VDI 表示转换成虚拟需要的VDI格式
|
安装虚拟硬盘
1
2
3
4
5
6
7
8
|
# 第一步:配置硬盘控制器
# SATA的硬盘其控制器是intelAHCI
VBoxManage storagectl HelloOS --name "SATA" --add sata --controller IntelAhci --portcount 1
# 第二步:挂载虚拟硬盘
VBoxManage closemedium disk ./hd.vdi #删除虚拟硬盘UUID并重新分配
#将虚拟硬盘挂到虚拟机的硬盘控制器
VBoxManage storageattach HelloOS --storagectl "SATA" --port 1 --device 0 --type hdd --medium ./hd.vdi
|
启动
1
|
VBoxManage startvm HelloOS #启动虚拟机
|
第十一讲:建造二级引导器
二级引导器作用
收集机器信息,对CPU、内存、显卡等进行初级配置
存储结构
收集的信息会存在如下的数据结构中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
typedef struct s_MACHBSTART
{
u64_t mb_krlinitstack;//内核栈地址
u64_t mb_krlitstacksz;//内核栈大小
u64_t mb_imgpadr;//操作系统映像
u64_t mb_imgsz;//操作系统映像大小
u64_t mb_bfontpadr;//操作系统字体地址
u64_t mb_bfontsz;//操作系统字体大小
u64_t mb_fvrmphyadr;//机器显存地址
u64_t mb_fvrmsz;//机器显存大小
u64_t mb_cpumode;//机器CPU工作模式
u64_t mb_memsz;//机器内存大小
u64_t mb_e820padr;//机器e820数组地址
u64_t mb_e820nr;//机器e820数组元素个数
u64_t mb_e820sz;//机器e820数组大小
//……
u64_t mb_pml4padr;//机器页表数据地址
u64_t mb_subpageslen;//机器页表个数
u64_t mb_kpmapphymemsz;//操作系统映射空间大小
//……
graph_t mb_ghparm;//图形信息
}__attribute__((packed)) machbstart_t;
|
模块规划
上图的文件经过编译会生成三个文件,具体流程如下
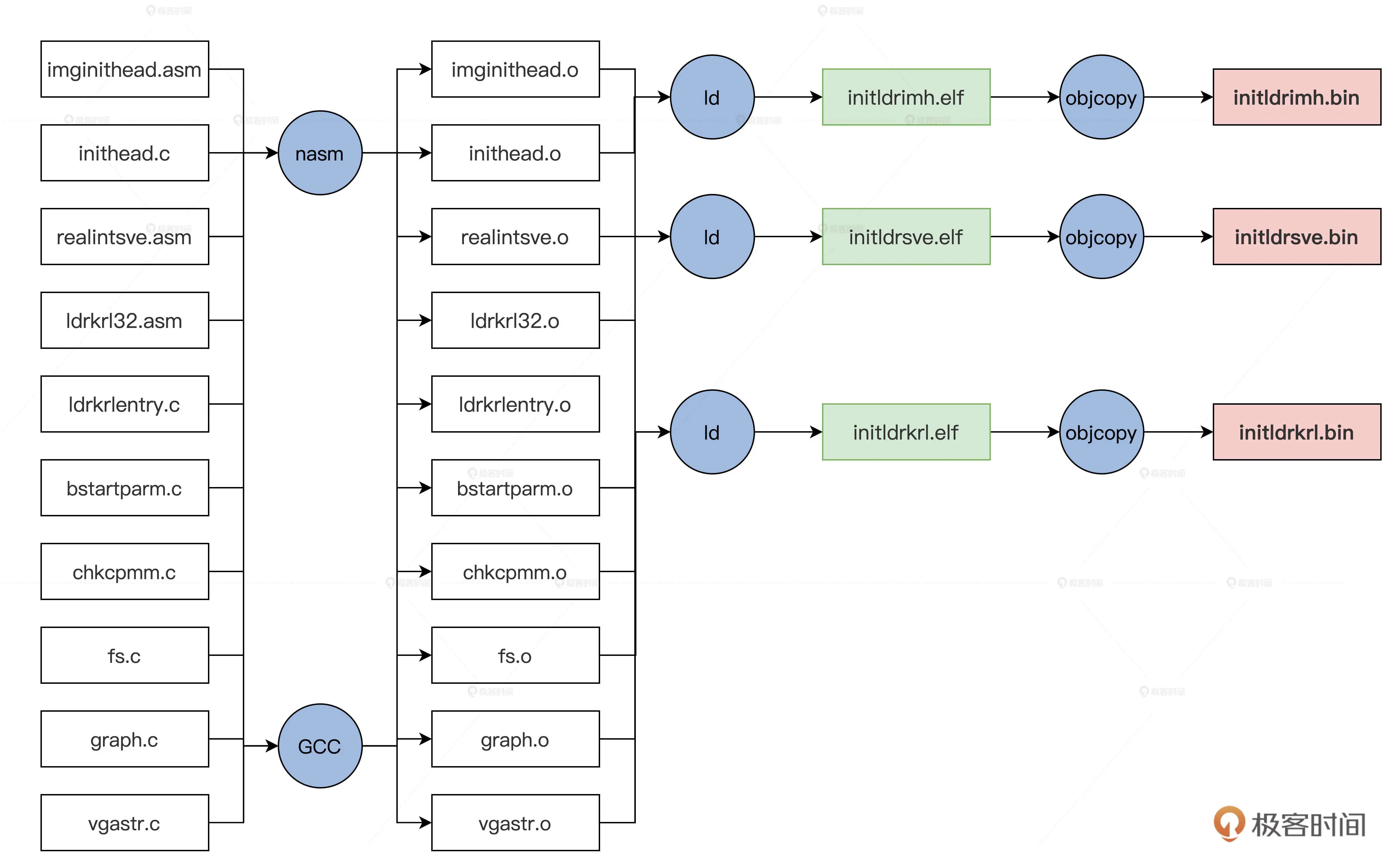
然后用映像打包工具打包成映像文件
1
2
|
lmoskrlimg -m k -lhf initldrimh.bin -o Cosmos.eki -f initldrkrl.bin initldrsve.bin
|
实现GRUB头
GRUB头有两个文件
- imginithead.asm汇编文件: 让GUR识别、设置C语言环境
- inithead.c文件:查找引导器核心文件initldrkrl,bin文件并将其放到特定的内存地址上
imginithead.asm
主要工作是初始化CPU的 寄存器,加载GDT,切换到CPU的保护模式
首先是 GRUB1 和 GRUB2需要的带个头结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
MBT_HDR_FLAGS EQU 0x00010003
MBT_HDR_MAGIC EQU 0x1BADB002
MBT2_MAGIC EQU 0xe85250d6
global _start
extern inithead_entry
[section .text]
[bits 32]
_start:
jmp _entry
align 4
mbt_hdr:
dd MBT_HDR_MAGIC
dd MBT_HDR_FLAGS
dd -(MBT_HDR_MAGIC+MBT_HDR_FLAGS)
dd mbt_hdr
dd _start
dd 0
dd 0
dd _entry
ALIGN 8
mbhdr:
DD 0xE85250D6
DD 0
DD mhdrend - mbhdr
DD -(0xE85250D6 + 0 + (mhdrend - mbhdr))
DW 2, 0
DD 24
DD mbhdr
DD _start
DD 0
DD 0
DW 3, 0
DD 12
DD _entry
DD 0
DW 0, 0
DD 8
mhdrend:
|
关闭中断并加载GDT
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
_entry:
cli ;关中断
in al, 0x70
or al, 0x80
out 0x70,al ;关掉不可屏蔽中断
lgdt [GDT_PTR] ;加载GDT地址到GDTR寄存器
jmp dword 0x8 :_32bits_mode ;长跳转刷新CS影子寄存器
;………………
;GDT全局段描述符表
GDT_START:
knull_dsc: dq 0
kcode_dsc: dq 0x00cf9e000000ffff
kdata_dsc: dq 0x00cf92000000ffff
k16cd_dsc: dq 0x00009e000000ffff ;16位代码段描述符
k16da_dsc: dq 0x000092000000ffff ;16位数据段描述符
GDT_END:
GDT_PTR:
GDTLEN dw GDT_END-GDT_START-1 ;GDT界限
GDTBASE dd GDT_ST
|
初始化段寄存器、通用寄存器和栈寄存器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
_32bits_mode:
mov ax, 0x10
mov ds, ax
mov ss, ax
mov es, ax
mov fs, ax
mov gs, ax
xor eax,eax
xor ebx,ebx
xor ecx,ecx
xor edx,edx
xor edi,edi
xor esi,esi
xor ebp,ebp
xor esp,esp
mov esp,0x7c00 ;设置栈顶为0x7c00
call inithead_entry ;调用inithead_entry函数在inithead.c中实现
jmp 0x200000 ;跳转到0x200000地址
|
上述代码最后调用了 inithead_entry 函数
inithead_entry分别调用了write_realintsvefile和write_ldrkrlfile,
将映像文件中的initldrsve.bin文件和initldrkrl.bin文件写入到特定的内存中
其中有两个依赖函数find_file 和m2mcopy
find_file函数负责扫描映像文件中的文件头描述符,对比其中的文件名,
然后返回对应的文件的文件头描述符地址,这样就可以得到其位置和大小
m2mcopy函数 负责将 映像文件复制到具体的内存空间中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
#define MDC_ENDGIC 0xaaffaaffaaffaaff
#define MDC_RVGIC 0xffaaffaaffaaffaa
#define REALDRV_PHYADR 0x1000
#define IMGFILE_PHYADR 0x4000000
#define IMGKRNL_PHYADR 0x2000000
#define LDRFILEADR IMGFILE_PHYADR
#define MLOSDSC_OFF (0x1000)
#define MRDDSC_ADR (mlosrddsc_t*)(LDRFILEADR+0x1000)
void inithead_entry()
{
write_realintsvefile();
write_ldrkrlfile();
return;
}
//写initldrsve.bin文件到特定的内存中
void write_realintsvefile()
{
fhdsc_t *fhdscstart = find_file("initldrsve.bin");
if (fhdscstart == NULL)
{
error("not file initldrsve.bin");
}
m2mcopy((void *)((u32_t)(fhdscstart->fhd_intsfsoff) + LDRFILEADR),
(void *)REALDRV_PHYADR, (sint_t)fhdscstart->fhd_frealsz);
return;
}
//写initldrkrl.bin文件到特定的内存中
void write_ldrkrlfile()
{
fhdsc_t *fhdscstart = find_file("initldrkrl.bin");
if (fhdscstart == NULL)
{
error("not file initldrkrl.bin");
}
m2mcopy((void *)((u32_t)(fhdscstart->fhd_intsfsoff) + LDRFILEADR),
(void *)ILDRKRL_PHYADR, (sint_t)fhdscstart->fhd_frealsz);
return;
}
//在映像文件中查找对应的文件
fhdsc_t *find_file(char_t *fname)
{
mlosrddsc_t *mrddadrs = MRDDSC_ADR;
if (mrddadrs->mdc_endgic != MDC_ENDGIC ||
mrddadrs->mdc_rv != MDC_RVGIC ||
mrddadrs->mdc_fhdnr < 2 ||
mrddadrs->mdc_filnr < 2)
{
error("no mrddsc");
}
s64_t rethn = -1;
fhdsc_t *fhdscstart = (fhdsc_t *)((u32_t)(mrddadrs->mdc_fhdbk_s) + LDRFILEADR);
for (u64_t i = 0; i < mrddadrs->mdc_fhdnr; i++)
{
if (strcmpl(fname, fhdscstart[i].fhd_name) == 0)
{
rethn = (s64_t)i;
goto ok_l;
}
}
rethn = -1;
ok_l:
if (rethn < 0)
{
error("not find file");
}
return &fhdscstart[rethn];
}
|
进入二级引导器
imginithead.asm最后的指令jump 0x200000跳转到了物理内存地址0x200000地址处
这个地址放置的正是initldrkrk.bin文件
这一跳进入了二级引导器的主模块
由于模块的 改变,需要写一小段汇编代码,建立下面这个initldr32.asm文件
重新把GDT(段描述符表)、IDT(中断选择子表)和寄存器重新初始化,然后调用二级引导器的主函数ldrkrl_entry
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
_entry:
cli
lgdt [GDT_PTR];加载GDT地址到GDTR寄存器
lidt [IDT_PTR];加载IDT地址到IDTR寄存器
jmp dword 0x8 :_32bits_mode;长跳转刷新CS影子寄存器
_32bits_mode:
mov ax, 0x10 ; 数据段选择子(目的)
mov ds, ax
mov ss, ax
mov es, ax
mov fs, ax
mov gs, ax
xor eax,eax
xor ebx,ebx
xor ecx,ecx
xor edx,edx
xor edi,edi
xor esi,esi
xor ebp,ebp
xor esp,esp
mov esp,0x90000 ;使得栈底指向了0x90000
call ldrkrl_entry ;调用ldrkrl_entry函数
xor ebx,ebx
jmp 0x2000000 ;跳转到0x2000000的内存地址
jmp $
GDT_START:
knull_dsc: dq 0
kcode_dsc: dq 0x00cf9a000000ffff ;a-e
kdata_dsc: dq 0x00cf92000000ffff
k16cd_dsc: dq 0x00009a000000ffff ;16位代码段描述符
k16da_dsc: dq 0x000092000000ffff ;16位数据段描述符
GDT_END:
GDT_PTR:
GDTLEN dw GDT_END-GDT_START-1 ;GDT界限
GDTBASE dd GDT_START
IDT_PTR:
IDTLEN dw 0x3ff
IDTBAS dd 0 ;这是BIOS中断表的地址和长度
|
调用BIOS中断
因为获取内存布局信息、设置显卡图像 模式等功能需要依赖BIOS的中断服务
可是BIOS中断工作在16位实模式,所以需要上下文切换,大体流程如下:
- 保存C语言环境下的 CPU上线文,即保护模式下的所有通用寄存器、段寄存器、程序指针寄存器和栈寄存器
- 切换到实模式,调用BIOS中断,把中断结果保存在内存中
- 切换回保护模式,加载之前保存的寄存器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
realadr_call_entry:
pushad ;保存通用寄存器
push ds
push es
push fs ;保存4个段寄存器
push gs
call save_eip_jmp ;调用save_eip_jmp
pop gs
pop fs
pop es ;恢复4个段寄存器
pop ds
popad ;恢复通用寄存器
ret
save_eip_jmp:
pop esi ;弹出call save_eip_jmp时保存的eip到esi寄存器中,
mov [PM32_EIP_OFF],esi ;把eip保存到特定的内存空间中
mov [PM32_ESP_OFF],esp ;把esp保存到特定的内存空间中
jmp dword far [cpmty_mode];长跳转这里表示把cpmty_mode处的第一个4字节装入eip,把其后的2字节装入cs
cpmty_mode:
dd 0x1000
dw 0x18
jmp $
|
jmp dword far [cpmty_mode]指令表示把 [cpmty_mode] 处的数据装入 CS: EIP,
即把 0x18: 0x1000 装入 CS: EIP 中,
0x18 是段描述索引,指向GDT中的 16 位代码段描述符,
0x10000 表示段内地址偏移
这个地址起始的代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
[bits 16]
_start:
_16_mode:
mov bp,0x20 ;0x20是指向GDT中的16位数据段描述符
mov ds, bp
mov es, bp
mov ss, bp
mov ebp, cr0
and ebp, 0xfffffffe
mov cr0, ebp ;CR0.P=0 关闭保护模式
jmp 0:real_entry ;刷新CS影子寄存器,真正进入实模式
real_entry:
mov bp, cs
mov ds, bp
mov es, bp
mov ss, bp ;重新设置实模式下的段寄存器 都是CS中值,即为0
mov sp, 08000h ;设置栈
mov bp,func_table
add bp,ax
call [bp] ;调用函数表中的汇编函数,ax是C函数中传递进来的
cli
call disable_nmi
mov ebp, cr0
or ebp, 1
mov cr0, ebp ;CR0.P=1 开启保护模式
jmp dword 0x8 :_32bits_mode
[BITS 32]
_32bits_mode:
mov bp, 0x10
mov ds, bp
mov ss, bp;重新设置保护模式下的段寄存器0x10是32位数据段描述符的索引
mov esi,[PM32_EIP_OFF];加载先前保存的EIP
mov esp,[PM32_ESP_OFF];加载先前保存的ESP
jmp esi ;eip=esi 回到了realadr_call_entry函数中
func_table: ;函数表
dw _getmmap ;获取内存布局视图的函数
dw _read ;读取硬盘的函数
dw _getvbemode ;获取显卡VBE模式
dw _getvbeonemodeinfo ;获取显卡VBE模式的数据
dw _setvbemode ;设置显卡VBE模式
|
上面的代码将其编译成16位的二进制文件,然后放在0x10000开始的内存空间
代码流程如下:
- 从
_16_mode进入实模式
- 在
real_entry根据ax寄存器的值找到函数表对应的函数,执行完后再次进入保护模式
- 加载EIP和ESP寄存器,从而回到
realadr_call_entry函数
引导器主函数
1
2
3
4
5
|
void ldrkrl_entry()
{
init_bstartparm();
return;
}
|
ldrkrl_entry函数在initldr32.asm文件中被调用
第十二讲:探查和收集信息
入口函数ldrkrl_entry实际调用了init_bstartparm
初始化
首先在1MB的内存地址处初始化了一个机器信息结构machbstart_t
1
2
3
4
5
6
7
8
9
10
11
12
13
|
//初始化machbstart_t结构体,清0,并设置一个标志
void machbstart_t_init(machbstart_t* initp)
{
memset(initp,0,sizeof(machbstart_t));
initp->mb_migc=MBS_MIGC;
return;
}
void init_bstartparm()
{
machbstart_t* mbsp = MBSPADR;//1MB的内存地址
machbstart_t_init(mbsp);
return;
}
|
检查CPU
我们需要检查CPU,主要通过两个函数实现:
- chk_cpuid: 检查CPU是否支持CPUID指令
- chk_cpuid: 用CPUID指令检查CPU是否支持64位长模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
//通过改写Eflags寄存器的第21位,观察其位的变化判断是否支持CPUID
int chk_cpuid()
{
int rets = 0;
__asm__ __volatile__(
"pushfl \n\t"
"popl %%eax \n\t"
"movl %%eax,%%ebx \n\t"
"xorl $0x0200000,%%eax \n\t"
"pushl %%eax \n\t"
"popfl \n\t"
"pushfl \n\t"
"popl %%eax \n\t"
"xorl %%ebx,%%eax \n\t"
"jz 1f \n\t"
"movl $1,%0 \n\t"
"jmp 2f \n\t"
"1: movl $0,%0 \n\t"
"2: \n\t"
: "=c"(rets)
:
:);
return rets;
}
//检查CPU是否支持长模式
int chk_cpu_longmode()
{
int rets = 0;
__asm__ __volatile__(
"movl $0x80000000,%%eax \n\t"
"cpuid \n\t" //把eax中放入0x80000000调用CPUID指令
"cmpl $0x80000001,%%eax \n\t"//看eax中返回结果
"setnb %%al \n\t" //不为0x80000001,则不支持0x80000001号功能
"jb 1f \n\t"
"movl $0x80000001,%%eax \n\t"
"cpuid \n\t"//把eax中放入0x800000001调用CPUID指令,检查edx中的返回数据
"bt $29,%%edx \n\t" //长模式 支持位 是否为1
"setcb %%al \n\t"
"1: \n\t"
"movzx %%al,%%eax \n\t"
: "=a"(rets)
:
:);
return rets;
}
//检查CPU主函数
void init_chkcpu(machbstart_t *mbsp)
{
if (!chk_cpuid())
{
kerror("Your CPU is not support CPUID sys is die!");
CLI_HALT();
}
if (!chk_cpu_longmode())
{
kerror("Your CPU is not support 64bits mode sys is die!");
CLI_HALT();
}
mbsp->mb_cpumode = 0x40;//如果成功则设置机器信息结构的cpu模式为64位
return;
}
|
获取内存布局
描述内存的数据结构
1
2
3
4
5
6
7
8
9
10
|
#define RAM_USABLE 1 //可用内存
#define RAM_RESERV 2 //保留内存不可使用
#define RAM_ACPIREC 3 //ACPI表相关的
#define RAM_ACPINVS 4 //ACPI NVS空间
#define RAM_AREACON 5 //包含坏内存
typedef struct s_e820{
u64_t saddr; /* 内存开始地址 */
u64_t lsize; /* 内存大小 */
u32_t type; /* 内存类型 */
}e820map_t;
|
获取内存布局信息就是获取这个结构体的数组,具体实现代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
void mmap(e820map_t **retemp, u32_t *retemnr)
{
realadr_call_entry(RLINTNR(0), 0, 0);
*retemnr = *((u32_t *)(E80MAP_NR));
*retemp = (e820map_t *)(*((u32_t *)(E80MAP_ADRADR)));
return;
}
#define ETYBAK_ADR 0x2000
#define PM32_EIP_OFF (ETYBAK_ADR)
#define PM32_ESP_OFF (ETYBAK_ADR+4)
#define E80MAP_NR (ETYBAK_ADR+64)//保存e820map_t结构数组元素个数的地址
#define E80MAP_ADRADR (ETYBAK_ADR+68) //保存e820map_t结构数组的开始地址
void init_mem(machbstart_t *mbsp)
{
e820map_t *retemp;
u32_t retemnr = 0;
mmap(&retemp, &retemnr);
if (retemnr == 0)
{
kerror("no e820map\n");
}
//根据e820map_t结构数据检查内存大小
if (chk_memsize(retemp, retemnr, 0x100000, 0x8000000) == NULL)
{
kerror("Your computer is low on memory, the memory cannot be less than 128MB!");
}
mbsp->mb_e820padr = (u64_t)((u32_t)(retemp));//把e820map_t结构数组的首地址传给mbsp->mb_e820padr
mbsp->mb_e820nr = (u64_t)retemnr;//把e820map_t结构数组元素个数传给mbsp->mb_e820nr
mbsp->mb_e820sz = retemnr * (sizeof(e820map_t));//把e820map_t结构数组大小传给mbsp->mb_e820sz
mbsp->mb_memsz = get_memsize(retemp, retemnr);//根据e820map_t结构数据计算内存大小。
return;
}
|
其中mmap通过realadr_call_entry调用实模式下的_getmmap
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
_getmmap:
push ds
push es
push ss
mov esi,0
mov dword[E80MAP_NR],esi
mov dword[E80MAP_ADRADR],E80MAP_ADR ;e820map结构体开始地址
xor ebx,ebx
mov edi,E80MAP_ADR
loop:
mov eax,0e820h ;获取e820map结构参数
mov ecx,20 ;e820map结构大小
mov edx,0534d4150h ;获取e820map结构参数必须是这个数据
int 15h ;BIOS的15h中断
jc .1
add edi,20
cmp edi,E80MAP_ADR+0x1000
jg .1
inc esi
cmp ebx,0
jne loop ;循环获取e820map结构
jmp .2
.1:
mov esi,0 ;出错处理,e820map结构数组元素个数为0
.2:
mov dword[E80MAP_NR],esi ;e820map结构数组元素个数
pop ss
pop es
pop ds
ret
|
初始化内核栈
因为操作系统使用C语言写的,所以需要有栈
初始化其实就是在机器信息结构machbstart_t中记录一下栈顶地址和栈大小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#define IKSTACK_PHYADR (0x90000-0x10)
#define IKSTACK_SIZE 0x1000
//初始化内核栈
void init_krlinitstack(machbstart_t *mbsp)
{
// 检查是否 和已经用到的内存空间(0x8f000 ~ 0x8f000_0x1001)冲突
if (1 > move_krlimg(mbsp, (u64_t)(0x8f000), 0x1001))
{
kerror("iks_moveimg err");
}
mbsp->mb_krlinitstack = IKSTACK_PHYADR;//栈顶地址
mbsp->mb_krlitstacksz = IKSTACK_SIZE; //栈大小是4KB
return;
}
|
放置内核文件和字库文件
从映像文件中解析出来放在特定内存空间中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
//放置内核文件
void init_krlfile(machbstart_t *mbsp)
{
//在映像中查找相应的文件,并复制到对应的地址,并返回文件的大小,这里是查找kernel.bin文件
u64_t sz = r_file_to_padr(mbsp, IMGKRNL_PHYADR, "kernel.bin");
if (0 == sz)
{
kerror("r_file_to_padr err");
}
//放置完成后更新机器信息结构中的数据
mbsp->mb_krlimgpadr = IMGKRNL_PHYADR;
mbsp->mb_krlsz = sz;
//mbsp->mb_nextwtpadr始终要保持指向下一段空闲内存的首地址
mbsp->mb_nextwtpadr = P4K_ALIGN(mbsp->mb_krlimgpadr + mbsp->mb_krlsz);
mbsp->mb_kalldendpadr = mbsp->mb_krlimgpadr + mbsp->mb_krlsz;
return;
}
//放置字库文件
void init_defutfont(machbstart_t *mbsp)
{
u64_t sz = 0;
//获取下一段空闲内存空间的首地址
u32_t dfadr = (u32_t)mbsp->mb_nextwtpadr;
//在映像中查找相应的文件,并复制到对应的地址,并返回文件的大小,这里是查找font.fnt文件
sz = r_file_to_padr(mbsp, dfadr, "font.fnt");
if (0 == sz)
{
kerror("r_file_to_padr err");
}
//放置完成后更新机器信息结构中的数据
mbsp->mb_bfontpadr = (u64_t)(dfadr);
mbsp->mb_bfontsz = sz;
//更新机器信息结构中下一段空闲内存的首地址
mbsp->mb_nextwtpadr = P4K_ALIGN((u32_t)(dfadr) + sz);
mbsp->mb_kalldendpadr = mbsp->mb_bfontpadr + mbsp->mb_bfontsz;
return;
}
|
建立MMU页表数据
Memory Management Unit
内核虚拟地址空间从 0xffff800000000000 开始,大小为 16GB,
所以映射关系为:0xffff800000000000~0xffff800400000000 映射到物理地址空间 0~0x400000000
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
#define KINITPAGE_PHYADR 0x1000000
void init_bstartpages(machbstart_t *mbsp)
{
//顶级页目录
u64_t *p = (u64_t *)(KINITPAGE_PHYADR);//16MB地址处
//页目录指针
u64_t *pdpte = (u64_t *)(KINITPAGE_PHYADR + 0x1000);
//页目录
u64_t *pde = (u64_t *)(KINITPAGE_PHYADR + 0x2000);
//物理地址从0开始
u64_t adr = 0;
if (1 > move_krlimg(mbsp, (u64_t)(KINITPAGE_PHYADR), (0x1000 * 16 + 0x2000)))
{
kerror("move_krlimg err");
}
//将顶级页目录、页目录指针的空间清0
for (uint_t mi = 0; mi < PGENTY_SIZE; mi++)
{
p[mi] = 0;
pdpte[mi] = 0;
}
//映射
for (uint_t pdei = 0; pdei < 16; pdei++)
{
pdpte[pdei] = (u64_t)((u32_t)pde | KPDPTE_RW | KPDPTE_P);
for (uint_t pdeii = 0; pdeii < PGENTY_SIZE; pdeii++)
{//大页KPDE_PS 2MB,可读写KPDE_RW,存在KPDE_P
pde[pdeii] = 0 | adr | KPDE_PS | KPDE_RW | KPDE_P;
adr += 0x200000;
}
pde = (u64_t *)((u32_t)pde + 0x1000);
}
//让顶级页目录中第0项和第((KRNL_VIRTUAL_ADDRESS_START) >> KPML4_SHIFT) & 0x1ff项,指向同一个页目录指针页
p[((KRNL_VIRTUAL_ADDRESS_START) >> KPML4_SHIFT) & 0x1ff] = (u64_t)((u32_t)pdpte | KPML4_RW | KPML4_P);
p[0] = (u64_t)((u32_t)pdpte | KPML4_RW | KPML4_P);
//把页表首地址保存在机器信息结构中
mbsp->mb_pml4padr = (u64_t)(KINITPAGE_PHYADR);
mbsp->mb_subpageslen = (u64_t)(0x1000 * 16 + 0x2000);
mbsp->mb_kpmapphymemsz = (u64_t)(0x400000000);
return;
}
|
为了简化编程,使用了长模式下的 2MB 分页方式
映射的核心逻辑由两重循环控制,外层循环控制页目录指针顶,只有 16 项,其中每一项都指向一个页目录,每个页目录中有 512 个物理页地址
物理地址每次增加 2MB,这是由 26~30 行的内层循环控制,每执行一次外层循环就要执行 512 次内层循环。
最后,顶级页目录中第 0 项和第 ((KRNL_VIRTUAL_ADDRESS_START) » KPML4_SHIFT) & 0x1ff 项,指向同一个页目录指针页,这样的话就能让虚拟地址:0xffff800000000000~0xffff800400000000 和虚拟地址:0~0x400000000,访问到同一个物理地址空间 0~0x400000000,这样做是有目的,内核在启动初期,虚拟地址和物理地址要保持相同。
设置显卡图形模式
显卡默认是文本模式,只能显示ASCII字符,需要切换到图形模式
切换显卡模式需要使用BIOS中断
1
2
3
4
5
6
7
8
9
10
11
12
|
void init_graph(machbstart_t* mbsp)
{
//初始化图形数据结构
graph_t_init(&mbsp->mb_ghparm);
//获取VBE模式,通过BIOS中断
get_vbemode(mbsp);
//获取一个具体VBE模式的信息,通过BIOS中断
get_vbemodeinfo(mbsp);
//设置VBE模式,通过BIOS中断
set_vbemodeinfo();
return;
}
|
这里使用了 VBE 的 118h 模式,该模式屏幕f分辨率为 1024*768,显存大小是 16.8MB
屏幕分辨率为 1024 * 768,即共768行,为行1024个像素点,
每个像素点占32位空间(红、绿、蓝、透明各8位)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
typedef struct s_PIXCL
{
u8_t cl_b; //蓝
u8_t cl_g; //绿
u8_t cl_r; //红
u8_t cl_a; //透明
}__attribute__((packed)) pixcl_t;
#define BGRA(r,g,b) ((0|(r<<16)|(g<<8)|b))
//通常情况下用pixl_t 和 BGRA宏
typedef u32_t pixl_t;
u32_t* dispmem = (u32_t*)mbsp->mb_ghparm.gh_framphyadr;
dispmem[x + (y * 1024)] = pix;
//x,y是像素的位置
|
集成
在init_bstartparm将上述功能串联起来,设置工作环境
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
void init_bstartparm()
{
machbstart_t *mbsp = MBSPADR;
machbstart_t_init(mbsp);
//检查CPU
init_chkcpu(mbsp);
//获取内存布局
init_mem(mbsp);
//初始化内核栈
init_krlinitstack(mbsp);
//放置内核文件
init_krlfile(mbsp);
//放置字库文件
init_defutfont(mbsp);
//将e820map结构数组从低地址(0x2068)搬到高地址(0x2000000)
init_meme820(mbsp);
//建立MMU页表
init_bstartpages(mbsp);
//设置图形模式
init_graph(mbsp);
return;
}
|
显示Logo
前面已经设置了图形模式,可以展示图片了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
void logo(machbstart_t* mbsp)
{
u32_t retadr=0,sz=0;
//在映像文件中获取logo.bmp文件
get_file_rpadrandsz("logo.bmp",mbsp,&retadr,&sz);
if(0==retadr)
{
kerror("logo getfilerpadrsz err");
}
//显示logo文件中的图像数据
bmp_print((void*)retadr,mbsp);
return;
}
void init_graph(machbstart_t* mbsp)
{
//……前面代码省略
//显示
logo(mbsp);
return;
}
|
切换CPU到长模式
切换到长模式(64位)后,寄存器位宽变了,需要重新初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
[section .start.text]
[BITS 32]
_start:
cli
mov ax,0x10
mov ds,ax
mov es,ax
mov ss,ax
mov fs,ax
mov gs,ax
lgdt [eGdtPtr]
;开启 PAE
mov eax, cr4
bts eax, 5 ; CR4.PAE = 1
mov cr4, eax
mov eax, PML4T_BADR ;加载MMU顶级页目录
mov cr3, eax
;开启 64bits long-mode
mov ecx, IA32_EFER
rdmsr
bts eax, 8 ; IA32_EFER.LME =1
wrmsr
;开启 PE 和 paging
mov eax, cr0
bts eax, 0 ; CR0.PE =1
bts eax, 31
;开启 CACHE
btr eax,29 ; CR0.NW=0
btr eax,30 ; CR0.CD=0 CACHE
mov cr0, eax ; IA32_EFER.LMA = 1
jmp 08:entry64
[BITS 64]
entry64:
mov ax,0x10
mov ds,ax
mov es,ax
mov ss,ax
mov fs,ax
mov gs,ax
xor rax,rax
xor rbx,rbx
xor rbp,rbp
xor rcx,rcx
xor rdx,rdx
xor rdi,rdi
xor rsi,rsi
xor r8,r8
xor r9,r9
xor r10,r10
xor r11,r11
xor r12,r12
xor r13,r13
xor r14,r14
xor r15,r15
mov rbx,MBSP_ADR
mov rax,KRLVIRADR
mov rcx,[rbx+KINITSTACK_OFF]
add rax,rcx
xor rcx,rcx
xor rbx,rbx
mov rsp,rax
push 0
push 0x8
mov rax,hal_start ;调用内核主函数
push rax
dw 0xcb48
jmp $
[section .start.data]
[BITS 32]
x64_GDT:
enull_x64_dsc: dq 0
ekrnl_c64_dsc: dq 0x0020980000000000 ; 64-bit 内核代码段
ekrnl_d64_dsc: dq 0x0000920000000000 ; 64-bit 内核数据段
euser_c64_dsc: dq 0x0020f80000000000 ; 64-bit 用户代码段
euser_d64_dsc: dq 0x0000f20000000000 ; 64-bit 用户数据段
eGdtLen equ $ - enull_x64_dsc ; GDT长度
eGdtPtr: dw eGdtLen - 1 ; GDT界限
dq ex64_GDT
|
上述代码具体详情是:
- 1~11行加载70~75行的 GDT
- 13~17行设置MMU、加载二级引导器中准备好的MMU页表
- 19~30行开启长模式、打开Cache
- 34~54行初始化寄存器
- 55~61行读取二级引导器中准备好的机器信息结构的栈地址存到RSP寄存器
- 63~66行把8和hal_start函数地址压入栈,利用
dw 0xcb48指令将数据弹出到
RIP和CS寄存器
第十三讲 实现板级初始化
hal层初始化
hal层对硬件相关的操作进行了抽象,对内核提供接口
初始化平台
init_halplaltform主要完成两个任务:
- 复制二级引导器建立的机器信息结构到hal层中的全局变量中,并释放二级引导器对应数据的内存
- 初始化图形显卡的驱动
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
void machbstart_t_init(machbstart_t *initp)
{
//清零
memset(initp, 0, sizeof(machbstart_t));
return;
}
void init_machbstart()
{
machbstart_t *kmbsp = &kmachbsp;
machbstart_t *smbsp = MBSPADR;//物理地址1MB处
machbstart_t_init(kmbsp);
//复制,要把地址转换成虚拟地址
memcopy((void *)phyadr_to_viradr((adr_t)smbsp), (void *)kmbsp, sizeof(machbstart_t));
return;
}
//平台初始化函数
void init_halplaltform()
{
//复制机器信息结构
init_machbstart();
//初始化图形显示驱动
init_bdvideo();
return;
}
|
kmachbsp是个hal层的全局变量,通过宏声明
1
2
3
4
5
6
|
//file: Comos/hal/x86
//全局变量定义变量放在data段
#define HAL_DEFGLOB_VARIABLE(vartype, varnam) \
EXTERN __attribute__((section(".data"))) vartype varname
HAL_DEFGLOB_VARIABLE(machbstart_t, kmachbsp);
|
图形显卡初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
void init_bdvideo()
{
dftgraph_t *kghp = &kdftgh;
//初始化图形数据结构,里面放有图形模式,分辨率,图形驱动函数指针
init_dftgraph();
//初始bga图形显卡的函数指针
init_bga();
//初始vbe图形显卡的函数指针
init_vbe();
//清空屏幕 为黑色
fill_graph(kghp, BGRA(0, 0, 0));
//显示背景图片
set_charsdxwflush(0, 0);
hal_background();
return;
}
typedef struct s_DFTGRAPH
{
u64_t gh_mode; //图形模式
u64_t gh_x; //水平像素点
u64_t gh_y; //垂直像素点
u64_t gh_framphyadr; //显存物理地址
u64_t gh_fvrmphyadr; //显存虚拟地址
u64_t gh_fvrmsz; //显存大小
u64_t gh_onepixbits; //一个像素字占用的数据位数
u64_t gh_onepixbyte;
u64_t gh_vbemodenr; //vbe模式号
u64_t gh_bank; //显存的bank数
u64_t gh_curdipbnk; //当前bank
u64_t gh_nextbnk; //下一个bank
u64_t gh_banksz; //bank大小
u64_t gh_fontadr; //字库地址
u64_t gh_fontsz; //字库大小
u64_t gh_fnthight; //字体高度
u64_t gh_nxtcharsx; //下一字符显示的x坐标
u64_t gh_nxtcharsy; //下一字符显示的y坐标
u64_t gh_linesz; //字符行高
pixl_t gh_deffontpx; //默认字体大小
u64_t gh_chardxw;
u64_t gh_flush;
u64_t gh_framnr;
u64_t gh_fshdata; //刷新相关的
dftghops_t gh_opfun; //图形驱动操作函数指针结构体
}dftgraph_t;
typedef struct s_DFTGHOPS
{
//读写显存数据
size_t (*dgo_read)(void* ghpdev,void* outp,size_t rdsz);
size_t (*dgo_write)(void* ghpdev,void* inp,size_t wesz);
sint_t (*dgo_ioctrl)(void* ghpdev,void* outp,uint_t iocode);
//刷新
void (*dgo_flush)(void* ghpdev);
sint_t (*dgo_set_bank)(void* ghpdev, sint_t bnr);
//读写像素
pixl_t (*dgo_readpix)(void* ghpdev,uint_t x,uint_t y);
void (*dgo_writepix)(void* ghpdev,pixl_t pix,uint_t x,uint_t y);
//直接读写像素
pixl_t (*dgo_dxreadpix)(void* ghpdev,uint_t x,uint_t y);
void (*dgo_dxwritepix)(void* ghpdev,pixl_t pix,uint_t x,uint_t y);
//设置x,y坐标和偏移
sint_t (*dgo_set_xy)(void* ghpdev,uint_t x,uint_t y);
sint_t (*dgo_set_vwh)(void* ghpdev,uint_t vwt,uint_t vhi);
sint_t (*dgo_set_xyoffset)(void* ghpdev,uint_t xoff,uint_t yoff);
//获取x,y坐标和偏移
sint_t (*dgo_get_xy)(void* ghpdev,uint_t* rx,uint_t* ry);
sint_t (*dgo_get_vwh)(void* ghpdev,uint_t* rvwt,uint_t* rvhi);
sint_t (*dgo_get_xyoffset)(void* ghpdev,uint_t* rxoff,uint_t* ryoff);
}dftghops_t;
//刷新显存
void flush_videoram(dftgraph_t *kghp)
{
kghp->gh_opfun.dgo_flush(kghp);
return;
}
|
我们将实际的图形驱动函数填入了dftghops_t结构体,通过结构体就可以调用相应的函数了
初始化内存
对二级引导器的内存布局信息进行扩展:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
#define PMR_T_OSAPUSERRAM 1
#define PMR_T_RESERVRAM 2
#define PMR_T_HWUSERRAM 8
#define PMR_T_ARACONRAM 0xf
#define PMR_T_BUGRAM 0xff
#define PMR_F_X86_32 (1<<0)
#define PMR_F_X86_64 (1<<1)
#define PMR_F_ARM_32 (1<<2)
#define PMR_F_ARM_64 (1<<3)
#define PMR_F_HAL_MASK 0xff
typedef struct s_PHYMMARGE
{
spinlock_t pmr_lock;//保护这个结构是自旋锁
u32_t pmr_type; //内存地址空间类型
u32_t pmr_stype;
u32_t pmr_dtype; //内存地址空间的子类型,见上面的宏
u32_t pmr_flgs; //结构的标志与状态
u32_t pmr_stus;
u64_t pmr_saddr; //内存空间的开始地址
u64_t pmr_lsize; //内存空间的大小
u64_t pmr_end; //内存空间的结束地址
u64_t pmr_rrvmsaddr;//内存保留空间的开始地址
u64_t pmr_rrvmend; //内存保留空间的结束地址
void* pmr_prip; //结构的私有数据指针,以后扩展所用
void* pmr_extp; //结构的扩展数据指针,以后扩展所用
}phymmarge_t;
u64_t initpmrge_core(e820map_t *e8sp, u64_t e8nr, phymmarge_t *pmargesp)
{
u64_t retnr = 0;
for (u64_t i = 0; i < e8nr; i++)
{
//根据一个e820map_t结构建立一个phymmarge_t结构
if (init_one_pmrge(&e8sp[i], &pmargesp[i]) == FALSE)
{
return retnr;
}
retnr++;
}
return retnr;
}
void init_phymmarge()
{
machbstart_t *mbsp = &kmachbsp;
phymmarge_t *pmarge_adr = NULL;
u64_t pmrgesz = 0;
//根据machbstart_t机器信息结构计算获得phymmarge_t结构的开始地址和大小
ret_phymmarge_adrandsz(mbsp, &pmarge_adr, &pmrgesz);
u64_t tmppmrphyadr = mbsp->mb_nextwtpadr;
e820map_t *e8p = (e820map_t *)((adr_t)(mbsp->mb_e820padr));
//建立phymmarge_t结构
u64_t ipmgnr = initpmrge_core(e8p, mbsp->mb_e820nr, pmarge_adr);
//把phymmarge_t结构的地址大小个数保存machbstart_t机器信息结构中
mbsp->mb_e820expadr = tmppmrphyadr;
mbsp->mb_e820exnr = ipmgnr;
mbsp->mb_e820exsz = ipmgnr * sizeof(phymmarge_t);
mbsp->mb_nextwtpadr = PAGE_ALIGN(mbsp->mb_e820expadr + mbsp->mb_e820exsz);
//phymmarge_t结构中地址空间从低到高进行排序,我已经帮你写好了
phymmarge_sort(pmarge_adr, ipmgnr);
return;
}
|
初始化中断
数据结构为gate_t,最大为256,由IDTR寄存器指向
1
2
3
4
5
6
7
8
9
10
11
12
|
typedef struct s_GATE
{
u16_t offset_low; /* 偏移 */
u16_t selector; /* 段选择子 */
u8_t dcount; /* 该字段只在调用门描述符中有效。如果在利用调用门调用子程序时引起特权级的转换和堆栈的改变,需要将外层堆栈中的参数复制到内层堆栈。该双字计数字段就是用于说明这种情况发生时,要复制的双字参数的数量。*/
u8_t attr; /* P(1) DPL(2) DT(1) TYPE(4) */
u16_t offset_high; /* 偏移的高位段 */
u32_t offset_high_h;
u32_t offset_resv;
}__attribute__((packed)) gate_t;
//定义中断表
HAL_DEFGLOB_VARIABLE(gate_t,x64_idt)[IDTMAX];
|
设置函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
//vector 向量也是中断号
//desc_type 中断门类型,中断门,陷阱门
//handler 中断处理程序的入口地址
//privilege 中断门的权限级别
void set_idt_desc(u8_t vector, u8_t desc_type, inthandler_t handler, u8_t privilege)
{
gate_t *p_gate = &x64_idt[vector];
u64_t base = (u64_t)handler;
p_gate->offset_low = base & 0xFFFF;
p_gate->selector = SELECTOR_KERNEL_CS;
p_gate->dcount = 0;
p_gate->attr = (u8_t)(desc_type | (privilege << 5));
p_gate->offset_high = (u16_t)((base >> 16) & 0xFFFF);
p_gate->offset_high_h = (u32_t)((base >> 32) & 0xffffffff);
p_gate->offset_resv = 0;
return;
}
|
中断处理程序负责保存CPU寄存器、调用中断程序、恢复CPU寄存器
保存和恢复寄存区汇编代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
|
//保存中断后的寄存器
%macro SAVEALL 0
push rax
push rbx
push rcx
push rdx
push rbp
push rsi
push rdi
push r8
push r9
push r10
push r11
push r12
push r13
push r14
push r15
xor r14,r14
mov r14w,ds
push r14
mov r14w,es
push r14
mov r14w,fs
push r14
mov r14w,gs
push r14
%endmacro
//恢复中断后寄存器
%macro RESTOREALL 0
pop r14
mov gs,r14w
pop r14
mov fs,r14w
pop r14
mov es,r14w
pop r14
mov ds,r14w
pop r15
pop r14
pop r13
pop r12
pop r11
pop r10
pop r9
pop r8
pop rdi
pop rsi
pop rbp
pop rdx
pop rcx
pop rbx
pop rax
iretq
%endmacro
//保存异常下的寄存器
%macro SAVEALLFAULT 0
push rax
push rbx
push rcx
push rdx
push rbp
push rsi
push rdi
push r8
push r9
push r10
push r11
push r12
push r13
push r14
push r15
xor r14,r14
mov r14w,ds
push r14
mov r14w,es
push r14
mov r14w,fs
push r14
mov r14w,gs
push r14
%endmacro
//恢复异常下寄存器
%macro RESTOREALLFAULT 0
pop r14
mov gs,r14w
pop r14
mov fs,r14w
pop r14
mov es,r14w
pop r14
mov ds,r14w
pop r15
pop r14
pop r13
pop r12
pop r11
pop r10
pop r9
pop r8
pop rdi
pop rsi
pop rbp
pop rdx
pop rcx
pop rbx
pop rax
add rsp,8
iretq
%endmacro
//没有错误码CPU异常
%macro SRFTFAULT 1
push _NOERRO_CODE
SAVEALLFAULT
mov r14w,0x10
mov ds,r14w
mov es,r14w
mov fs,r14w
mov gs,r14w
mov rdi,%1 ;rdi, rsi
mov rsi,rsp
call hal_fault_allocator
RESTOREALLFAULT
%endmacro
//CPU异常
%macro SRFTFAULT_ECODE 1
SAVEALLFAULT
mov r14w,0x10
mov ds,r14w
mov es,r14w
mov fs,r14w
mov gs,r14w
mov rdi,%1
mov rsi,rsp
call hal_fault_allocator
RESTOREALLFAULT
%endmacro
//硬件中断
%macro HARWINT 1
SAVEALL
mov r14w,0x10
mov ds,r14w
mov es,r14w
mov fs,r14w
mov gs,r14w
mov rdi, %1
mov rsi,rsp
call hal_intpt_allocator
RESTOREALL
%endmacro
//除法错误异常 比如除0
exc_divide_error:
SRFTFAULT 0
//单步执行异常
exc_single_step_exception:
SRFTFAULT 1
exc_nmi:
SRFTFAULT 2
//调试断点异常
exc_breakpoint_exception:
SRFTFAULT 3
//溢出异常
exc_overflow:
SRFTFAULT 4
//段不存在异常
exc_segment_not_present:
SRFTFAULT_ECODE 11
//栈异常
exc_stack_exception:
SRFTFAULT_ECODE 12
//通用异常
exc_general_protection:
SRFTFAULT_ECODE 13
//缺页异常
exc_page_fault:
SRFTFAULT_ECODE 14
hxi_exc_general_intpfault:
SRFTFAULT 256
//硬件1~7号中断
hxi_hwint00:
HARWINT (INT_VECTOR_IRQ0+0)
hxi_hwint01:
HARWINT (INT_VECTOR_IRQ0+1)
hxi_hwint02:
HARWINT (INT_VECTOR_IRQ0+2)
hxi_hwint03:
HARWINT (INT_VECTOR_IRQ0+3)
hxi_hwint04:
HARWINT (INT_VECTOR_IRQ0+4)
hxi_hwint05:
HARWINT (INT_VECTOR_IRQ0+5)
hxi_hwint06:
HARWINT (INT_VECTOR_IRQ0+6)
hxi_hwint07:
HARWINT (INT_VECTOR_IRQ0+7)
|
初始化函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
void init_idt_descriptor()
{
//一开始把所有中断的处理程序设置为保留的通用处理程序
for (u16_t intindx = 0; intindx <= 255; intindx++)
{
set_idt_desc((u8_t)intindx, DA_386IGate, hxi_exc_general_intpfault, PRIVILEGE_KRNL);
}
set_idt_desc(INT_VECTOR_DIVIDE, DA_386IGate, exc_divide_error, PRIVILEGE_KRNL);
set_idt_desc(INT_VECTOR_DEBUG, DA_386IGate, exc_single_step_exception, PRIVILEGE_KRNL);
set_idt_desc(INT_VECTOR_NMI, DA_386IGate, exc_nmi, PRIVILEGE_KRNL);
set_idt_desc(INT_VECTOR_BREAKPOINT, DA_386IGate, exc_breakpoint_exception, PRIVILEGE_USER);
set_idt_desc(INT_VECTOR_OVERFLOW, DA_386IGate, exc_overflow, PRIVILEGE_USER);
//篇幅所限,未全部展示
set_idt_desc(INT_VECTOR_PAGE_FAULT, DA_386IGate, exc_page_fault, PRIVILEGE_KRNL);
set_idt_desc(INT_VECTOR_IRQ0 + 0, DA_386IGate, hxi_hwint00, PRIVILEGE_KRNL);
set_idt_desc(INT_VECTOR_IRQ0 + 1, DA_386IGate, hxi_hwint01, PRIVILEGE_KRNL);
set_idt_desc(INT_VECTOR_IRQ0 + 2, DA_386IGate, hxi_hwint02, PRIVILEGE_KRNL);
set_idt_desc(INT_VECTOR_IRQ0 + 3, DA_386IGate, hxi_hwint03, PRIVILEGE_KRNL);
//篇幅所限,未全部展示
return;
}
|
CPU响应中断后,需要相应的分发器处理,具体的中断处理框架如下图
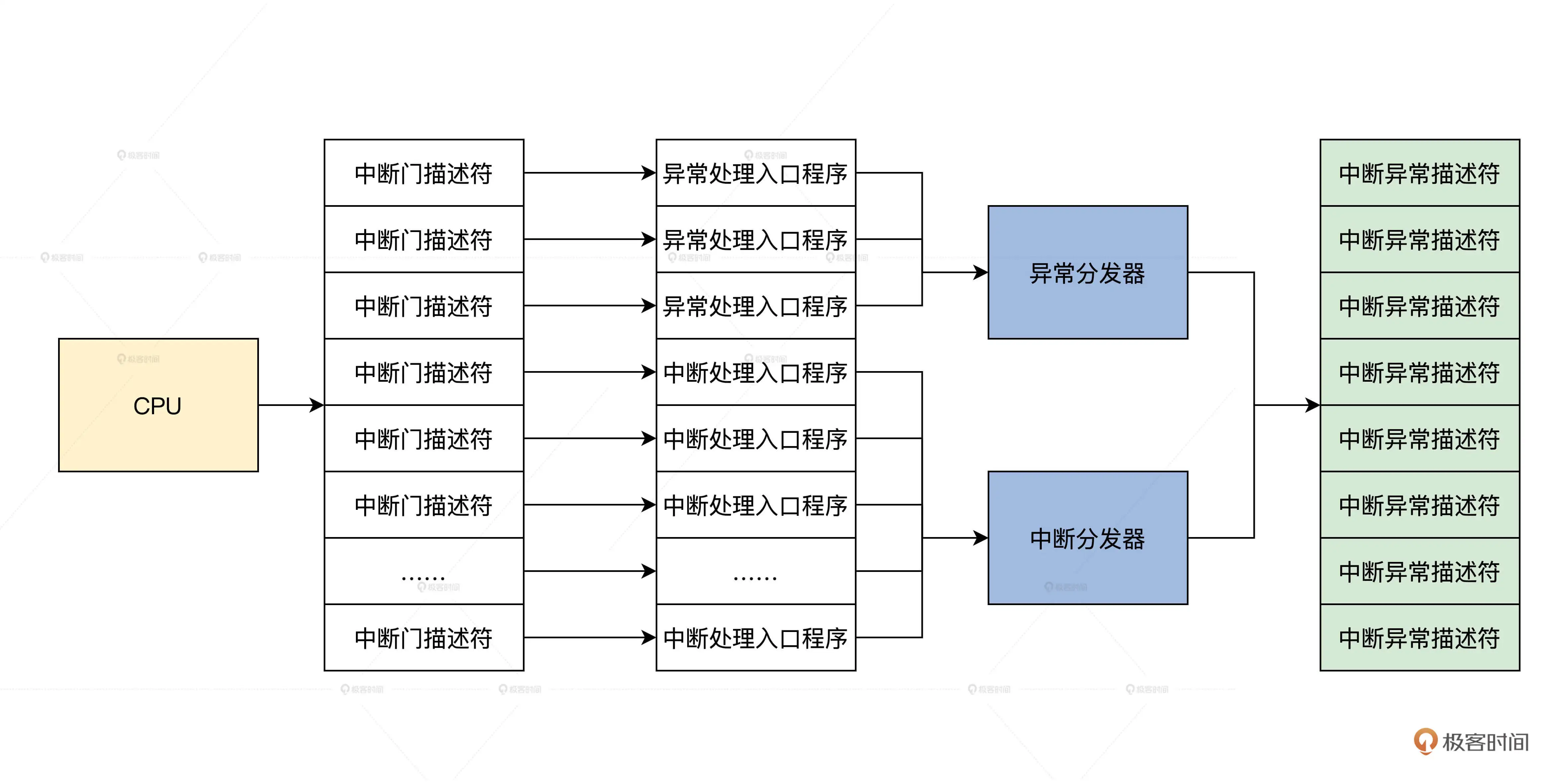
中断异常描述数据结构intfltdsc_t
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
typedef struct s_INTFLTDSC{
spinlock_t i_lock;
u32_t i_flg;
u32_t i_stus;
uint_t i_prity; //中断优先级
uint_t i_irqnr; //中断号
uint_t i_deep; //中断嵌套深度
u64_t i_indx; //中断计数
list_h_t i_serlist; //也可以使用中断回调函数的方式
uint_t i_sernr; //中断回调函数个数
list_h_t i_serthrdlst; //中断线程链表头
uint_t i_serthrdnr; //中断线程个数
void* i_onethread; //只有一个中断线程时直接用指针
void* i_rbtreeroot; //如果中断线程太多则按优先级组成红黑树
list_h_t i_serfisrlst;
uint_t i_serfisrnr;
void* i_msgmpool; //可能的中断消息池
void* i_privp;
void* i_extp;
}intfltdsc_t;
|
中断可以由另一个线程执行 ,也可以是一个回调函数,回调函数存放的结构体
1
2
3
4
5
6
7
8
9
10
|
typedef drvstus_t (*intflthandle_t)(uint_t ift_nr,void* device,void* sframe); //中断处理函数的指针类型
typedef struct s_INTSERDSC{
list_h_t s_list; //在中断异常描述符中的链表
list_h_t s_indevlst; //在设备描述描述符中的链表
u32_t s_flg;
intfltdsc_t* s_intfltp; //指向中断异常描述符
void* s_device; //指向设备描述符
uint_t s_indx;
intflthandle_t s_handle; //中断处理的回调函数指针
}intserdsc_t;
|
当内核或者设备 驱动要安装一个中断处理函数时,先申请一个intserdsc_t结构体,然后
把中断函数的地址写入其中,最后把结构体挂载到对应的intfltdsc_t中的i_serfisrlst链表中
由于中断信号有限,而驱动设备可以有更多,所以发生中断时,对应信号所有的处理函数会依次执行,
如果不是自己设备产生的中断,就会跳过。
分发器函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
//中断处理函数
void hal_do_hwint(uint_t intnumb, void *krnlsframp)
{
intfltdsc_t *ifdscp = NULL;
cpuflg_t cpuflg;
//根据中断号获取中断异常描述符地址
ifdscp = hal_retn_intfltdsc(intnumb);
//对断异常描述符加锁并中断
hal_spinlock_saveflg_cli(&ifdscp->i_lock, &cpuflg);
ifdscp->i_indx++;
ifdscp->i_deep++;
//运行中断处理的回调函数
hal_run_intflthandle(intnumb, krnlsframp);
ifdscp->i_deep--;
//解锁并恢复中断状态
hal_spinunlock_restflg_sti(&ifdscp->i_lock, &cpuflg);
return;
}
//异常分发器
void hal_fault_allocator(uint_t faultnumb, void *krnlsframp)
{
//我们的异常处理回调函数也是放在中断异常描述符中的
hal_do_hwint(faultnumb, krnlsframp);
return;
}
//中断分发器
void hal_hwint_allocator(uint_t intnumb, void *krnlsframp)
{
hal_do_hwint(intnumb, krnlsframp);
return;
}
|
调用回调函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
void hal_run_intflthandle(uint_t ifdnr, void *sframe)
{
intserdsc_t *isdscp;
list_h_t *lst;
//根据中断号获取中断异常描述符地址
intfltdsc_t *ifdscp = hal_retn_intfltdsc(ifdnr);
//遍历i_serlist链表
list_for_each(lst, &ifdscp->i_serlist)
{
//获取i_serlist链表上对象即intserdsc_t结构
isdscp = list_entry(lst, intserdsc_t, s_list);
//调用中断处理回调函数
isdscp->s_handle(ifdnr, isdscp->s_device, sframe);
}
return;
}
|
初始化中断控制器
中断控制器可以屏蔽或启动哪些设备,也可以设定设备之间的优先级
x86平台最开始使用的是8259A控制器,以级联的方式存在,有15个信号源
第十四讲 Linux初始化(上)
全局流程
机器加电后,BIOS会进行自检,然后加载引导设备中的引导扇区,在安装有Linux
操作系统的环境的引导扇区有GRUB程序,GRUB会加载Linux内核映像vmlinuz
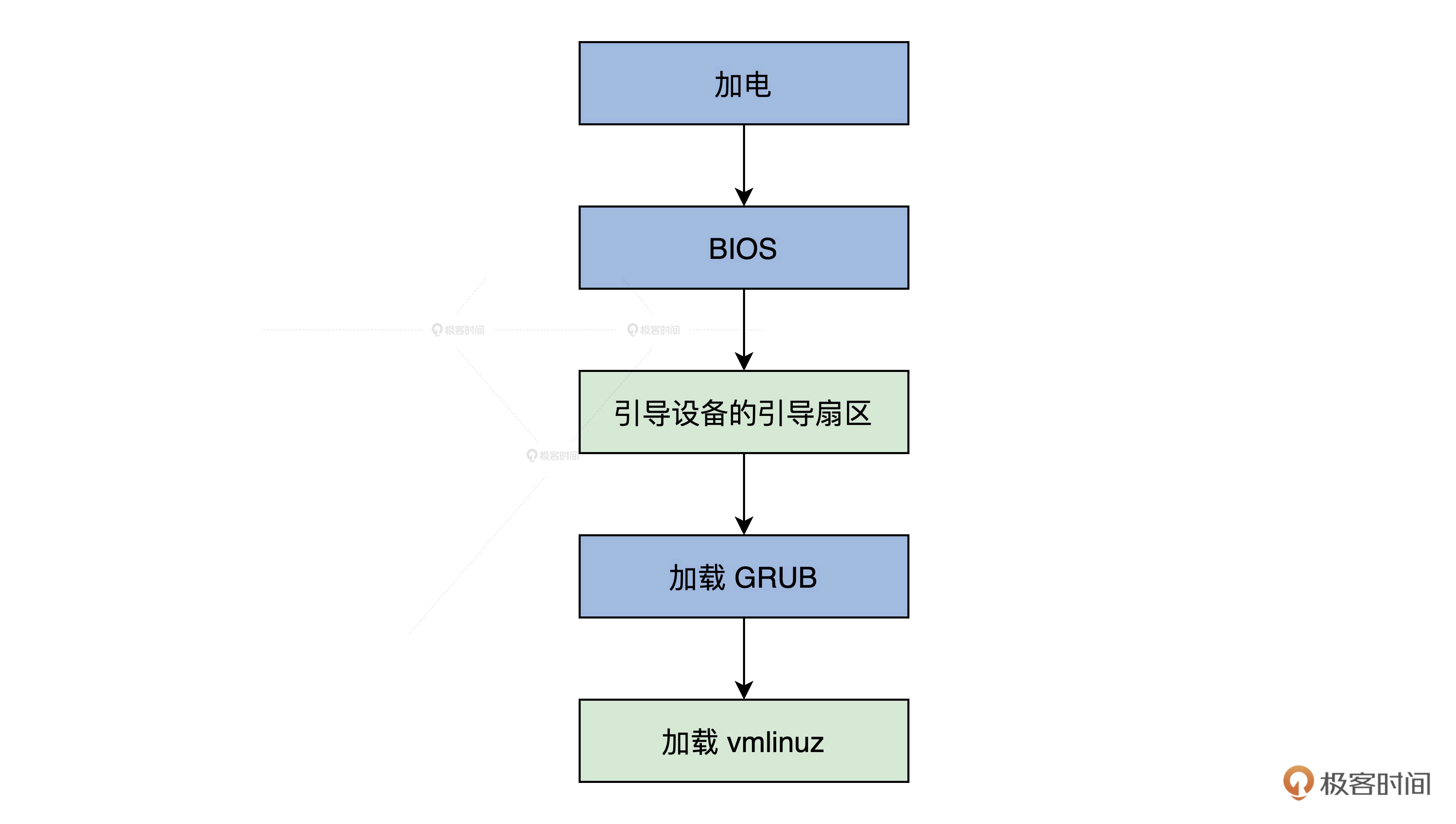
从BIOS到GRUB
加电时,会将CS和IP寄存器设置为0XF000和0XFFF0,这个对应物理地址0XFFF0(CS左移4位+IP),
这个 地址连接了主板上的一个小 ROM芯片,这个芯片和内存有相同的访问机制和寻址方式,
只是在断电时也不会丢失数据,BIOS程序就存储在这个芯片上。
BIOS一开始会初始化CPU;然后检查内存,将自己的一部分复制到内存,跳转到内存中运行;
接下来枚举本地设备进行初始化,检查硬件是否损坏;
之后在内存中建立中断表和中断服程序,从0x00000~0x003ff的1KB空间构建中断表,中断表有256个条目,每个条目4字节(CS+IP寄存器),
0x00400~0x004FF的256KBk空间构建BIOSu数据区,其中在0x0e05b的地址加载了8KB大小的和中断表对应的中断服务程序。
当BIOS找到启动区后(设备的0盘0道1扇区,共 512字节,最后两字节为0x55和0xaa,即代表包含GRUB启动程序),将数据复制到
0x7c00起始的内存地址,然后加控制权交给了GRUB
GRUB启动
由于GRUB程序不止512字节,所以会分多次加载。
其中有两个重要的文件,第一个是boot.img,
boot.img会被GRUB程序写到硬盘的启动区,同时在文件中的第一个位置
写入core.img占用的第一个扇区的区号;
第二个文件是core.img,core.img中嵌入了足够多的功能,
可以识别硬盘文件系统 、访问/boot/grub目录、加载启动菜单等
详解vmlinuz文件结构
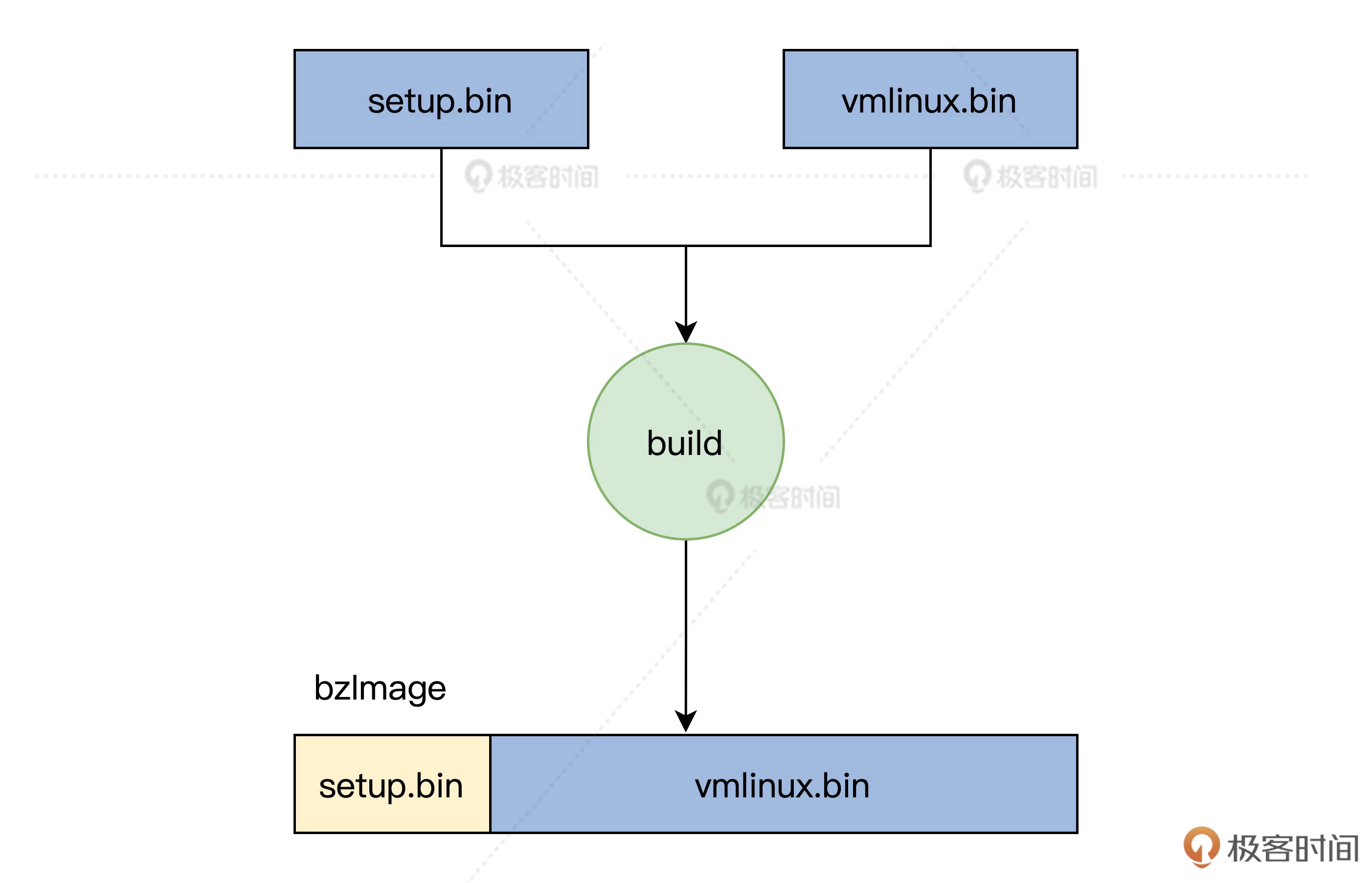
第十五讲 Linux初始化(下)
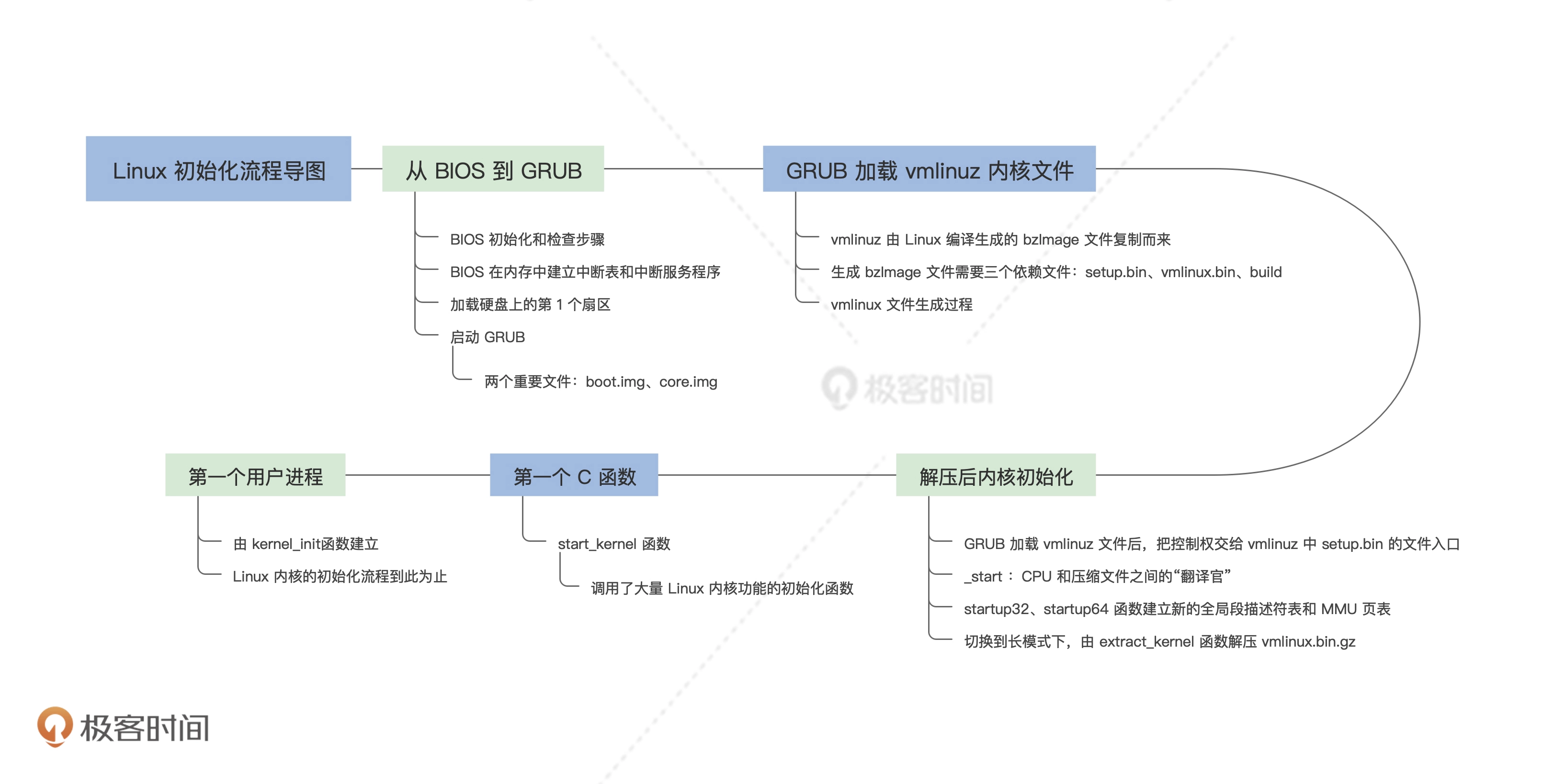
-
GRUB 加载 vmlinuz 文件之后,会把控制权交给 vmlinuz 文件的 setup.bin 的部分中 _start,它会设置好栈,清空 bss,设置好 setup_header 结构,调用 16 位 main 切换到保护模式,最后跳转到 1MB 处的 vmlinux.bin 文件中。
-
从 vmlinux.bin 文件中 startup32、startup64 函数开始建立新的全局段描述符表和 MMU 页表,切换到长模式下解压 vmlinux.bin.gz。释放出 vmlinux 文件之后,由解析 elf 格式的函数进行解析,释放 vmlinux 中的代码段和数据段到指定的内存。然后调用其中的 startup_64 函数,在这个函数的最后调用 Linux 内核的第一个 C 函数。
-
Linux 内核第一个 C 函数重新设置 MMU 页表,随后便调用了最有名的 start_kernel 函数, start_kernel 函数中调用了大多数 Linux 内核功能性初始化函数,在最后调用 rest_init 函数建立了两个内核线程,在其中的 kernel_init 线程建立了第一个用户态进程。
第十六讲 划分土地(上):如何划分和组织内存
由于分段模式难以映射虚拟地址空间,我们使用分页模式管理内存,每页大小为4KB
如何表示一个页
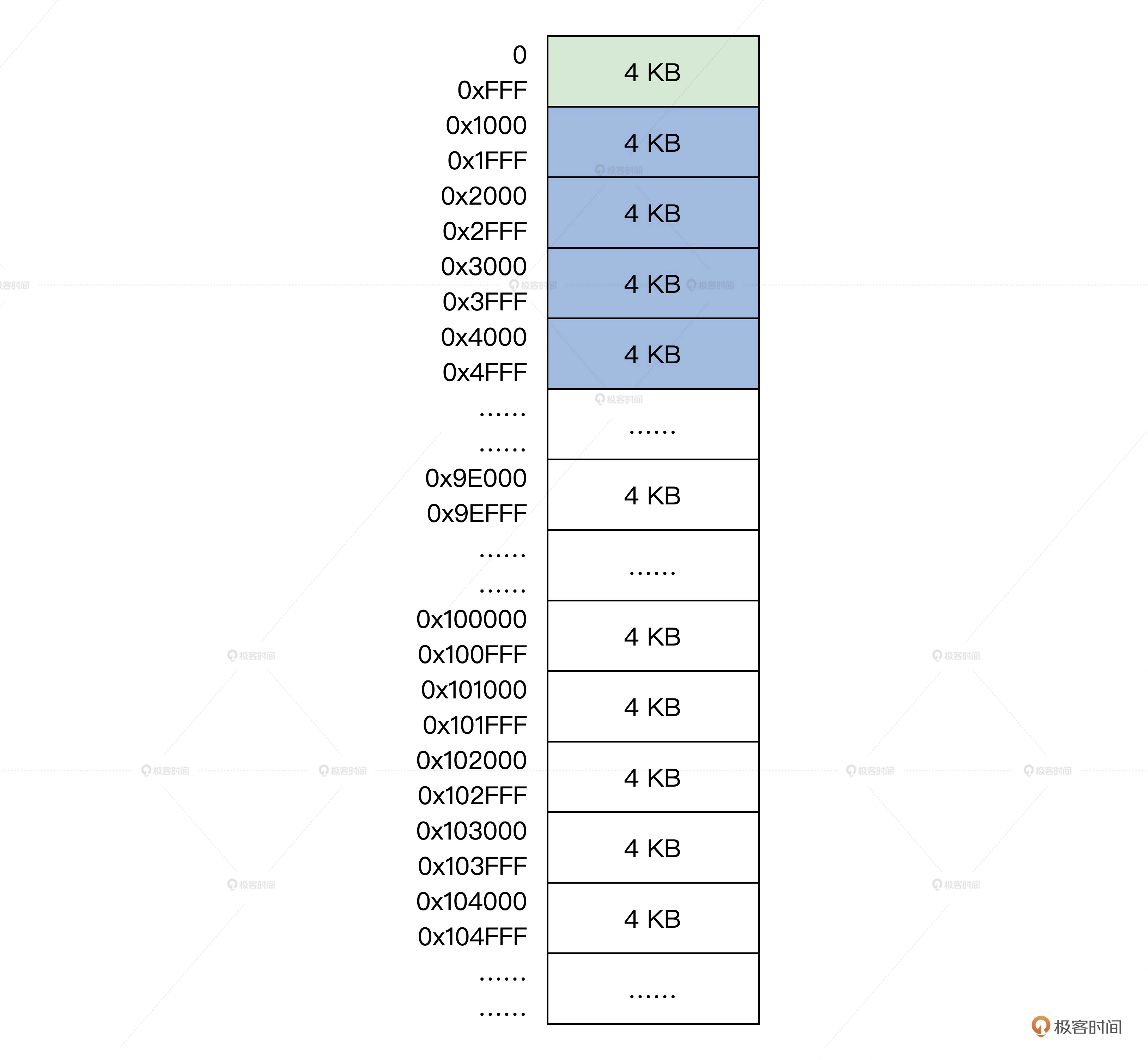
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
//物理地址和标志
typedef struct s_PHYADRFLGS
{
u64_t paf_alloc:1; //分配位
u64_t paf_shared:1; //共享位
u64_t paf_swap:1; //交换位
u64_t paf_cache:1; //缓存位
u64_t paf_kmap:1; //映射位
u64_t paf_lock:1; //锁定位
u64_t paf_dirty:1; //脏位
u64_t paf_busy:1; //忙位
u64_t paf_rv2:4; //保留位
u64_t paf_padrs:52; //页物理地址位
}__attribute__((packed)) phyadrflgs_t;
|
页的物理地址是4KB(0x1000=2**12)对齐的,所以低12位可用作其他标志位
内存区
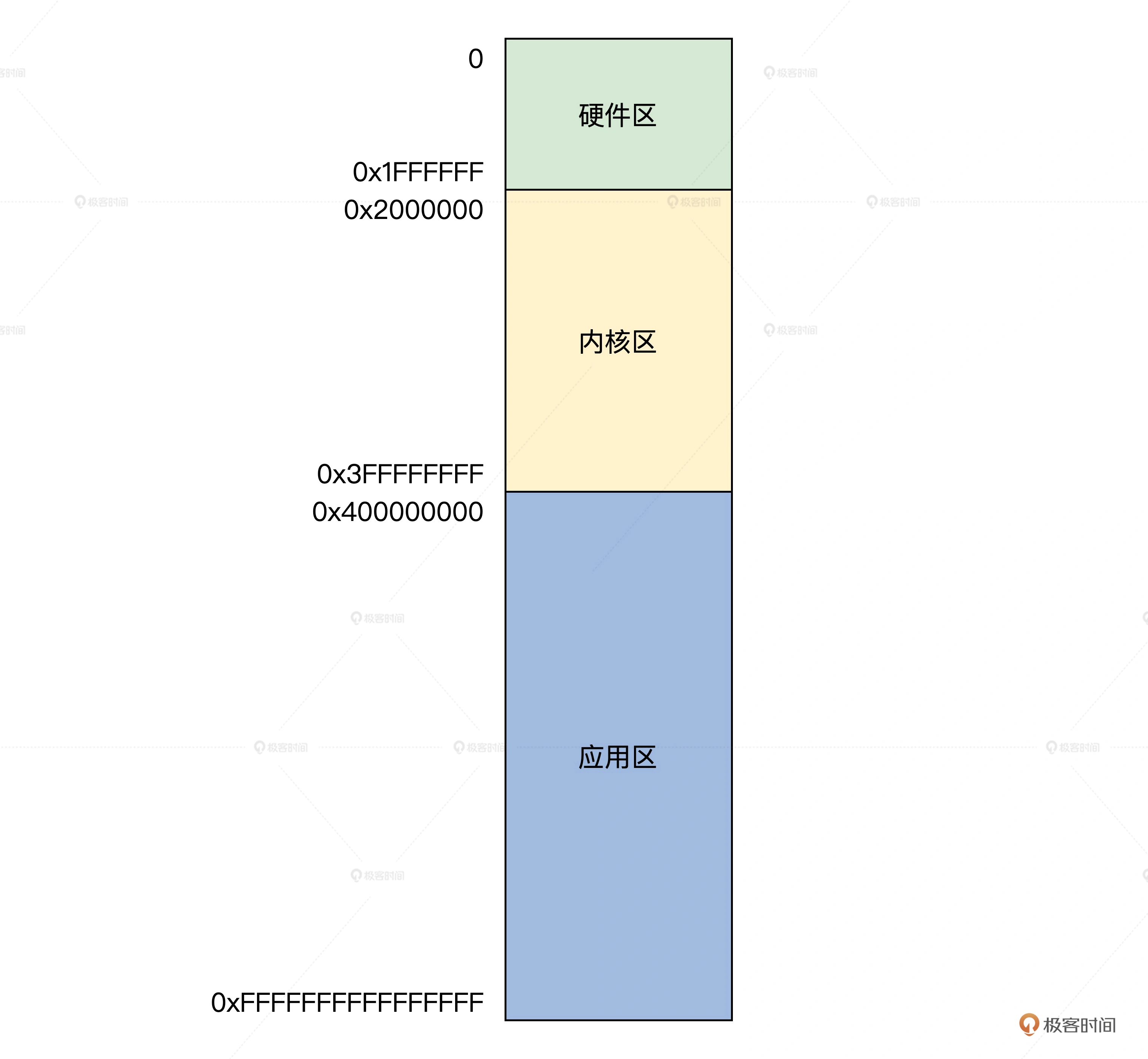
将物理内存分为三个区: 硬件区、内核区和应用区
硬件区
硬件区占用地址区间为 0~32MB,用于一些不依赖 CPU 直接和内存交换数据的硬件,如 DMA
内核区
用于内核
应用区
用于用户态程序
按需分配,应用用到一个页,就分配一个页,如果访问到没有和物理内存页建立映射关系的虚拟内存页,
CPU 会产生缺页中断,操作系统会非配一个物理页,并和虚拟也建好映射关系
组织内存页
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
typedef struct s_BAFHLST
{
spinlock_t af_lock; //保护自身结构的自旋锁
u32_t af_stus; //状态
uint_t af_oder; //页面数的位移量
uint_t af_oderpnr; //oder对应的页面数比如 oder为2那就是1<<2=4
uint_t af_fobjnr; //多少个空闲msadsc_t结构,即空闲页面
uint_t af_mobjnr; //此结构的msadsc_t结构总数,即此结构总页面
uint_t af_alcindx; //此结构的分配计数
uint_t af_freindx; //此结构的释放计数
list_h_t af_frelst; //挂载此结构的空闲msadsc_t结构
list_h_t af_alclst; //挂载此结构已经分配的msadsc_t结构
}bafhlst_t;
#define MDIVMER_ARR_LMAX 52
typedef struct s_MEMDIVMER
{
spinlock_t dm_lock; //保护自身结构的自旋锁
u32_t dm_stus; //状态
uint_t dm_divnr; //内存分配次数
uint_t dm_mernr; //内存合并次数
bafhlst_t dm_mdmlielst[MDIVMER_ARR_LMAX];//bafhlst_t结构数组
bafhlst_t dm_onemsalst; //单个的bafhlst_t结构
}memdivmer_t;
|
dm_mdmlielst第 n个元素挂载 2 ** n 个 物理地址连续的msadsc_t 结构,
第十七讲 划分土地(中):如何实现内存页面初始化
内存页结构初始化
内存区结构构初始化
处理内存占用
合并内存页到内存区
虚实地址映射
第十八讲 划分土地(下):如何实现内存页的分配和释放
内存页的分配
比如现在我们要分配一个页面,这个算法将执行如下步骤:
- 根据一个页面的请求,会返回 m_mdmlielst 数组中的第 0 个 bafhlst_t 结构。
- 如果第 0 个 bafhlst_t 结构中有 msadsc_t 结构就直接返回,若没有 msadsc_t 结构,就会继续查找 m_mdmlielst 数组中的第 1 个 bafhlst_t 结构。
- 如果第 1 个 bafhlst_t 结构中也没有 msadsc_t 结构,就会继续查找 m_mdmlielst 数组中的第 2 个 bafhlst_t 结构。
- 如果第 2 个 bafhlst_t 结构中有 msadsc_t 结构,记住第 2 个 bafhlst_t 结构中对应是 4 个连续的 msadsc_t 结构。这时让这 4 个连续的 msadsc_t 结构从第 2 个 bafhlst_t 结构中脱离。
- 把这 4 个连续的 msadsc_t 结构,对半分割成 2 个双 msadsc_t 结构,把其中一个双 msadsc_t 结构挂载到第 1 个 bafhlst_t 结构中。
- 把剩下一个双 msadsc_t 结构,继续对半分割成两个单 msadsc_t 结构,把其中一个单 msadsc_t 结构挂载到第 0 个 bafhlst_t 结构中,剩下一个单 msadsc_t 结构返回给请求者,完成内存分配。
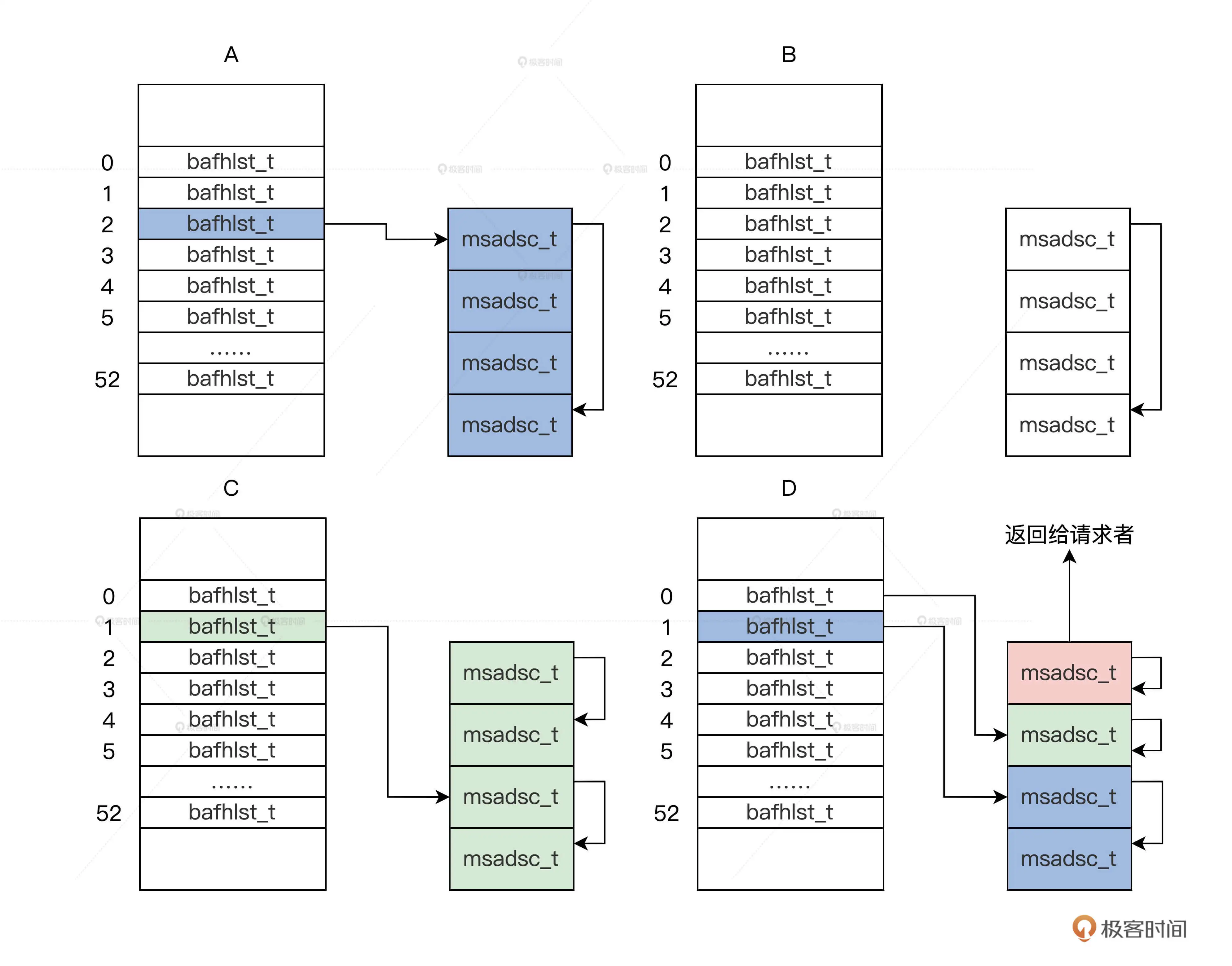
内存页的释放
比如现在我们要释放一个页面,这个算法将执行如下步骤。
- 释放一个页面,会返回 m_mdmlielst 数组中的第 0 个 bafhlst_t 结构。
- 设置这个页面对应的 msadsc_t 结构的相关信息,表示已经执行了释放操作。
- 开始查看第 0 个 bafhlst_t 结构中有没有空闲的 msadsc_t,并且它和要释放的 msadsc_t 对应的物理地址是连续的。没有则把这个释放的 msadsc_t 挂载第 0 个 bafhlst_t 结构中,算法结束,否则进入下一步。
- 把第 0 个 bafhlst_t 结构中的 msadsc_t 结构拿出来与释放的 msadsc_t 结构,合并成 2 个连续且更大的 msadsc_t。
- 继续查看第 1 个 bafhlst_t 结构中有没有空闲的 msadsc_t,而且这个空闲 msadsc_t 要和上一步合并的 2 个 msadsc_t 对应的物理地址是连续的。没有则把这个合并的 2 个 msadsc_t 挂载第 1 个 bafhlst_t 结构中,算法结束,否则进入下一步。
- 把第 1 个 bafhlst_t 结构中的 2 个连续的 msadsc_t 结构,还有合并的 2 个地址连续的 msadsc_t 结构拿出来,合并成 4 个连续且更大的 msadsc_t 结构。
- 继续查看第 2 个 bafhlst_t 结构,有没有空闲的 msadsc_t 结构,并且它要和上一步合并的 4 个 msadsc_t 结构对应的物理地址是连续的。没有则把这个合并的 4 个 msadsc_t 挂载第 2 个 bafhlst_t 结构中,算法结束。
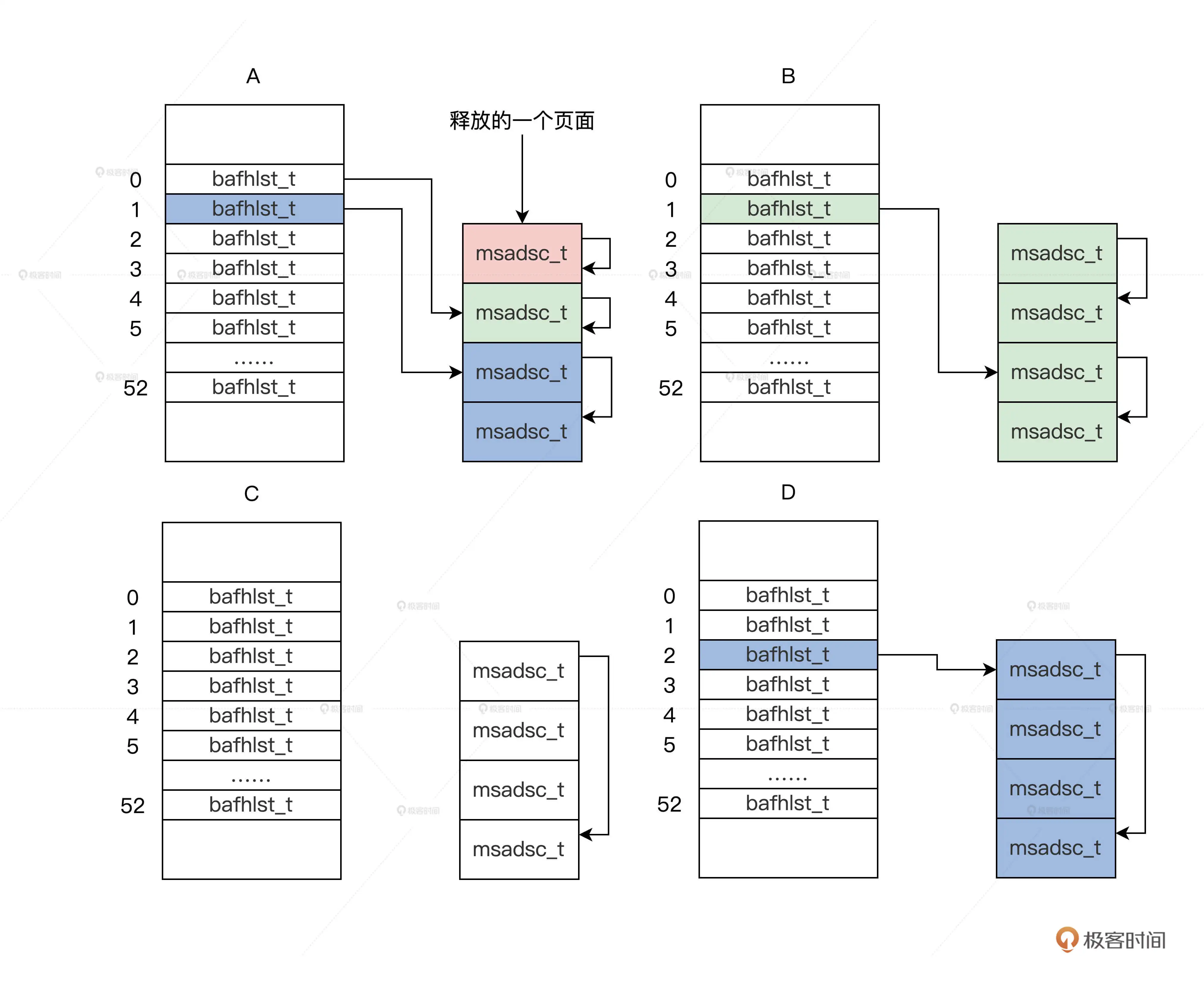
第十九讲 如何管理内存对象
第二十讲 如何表示虚拟内存
空间划分
x86
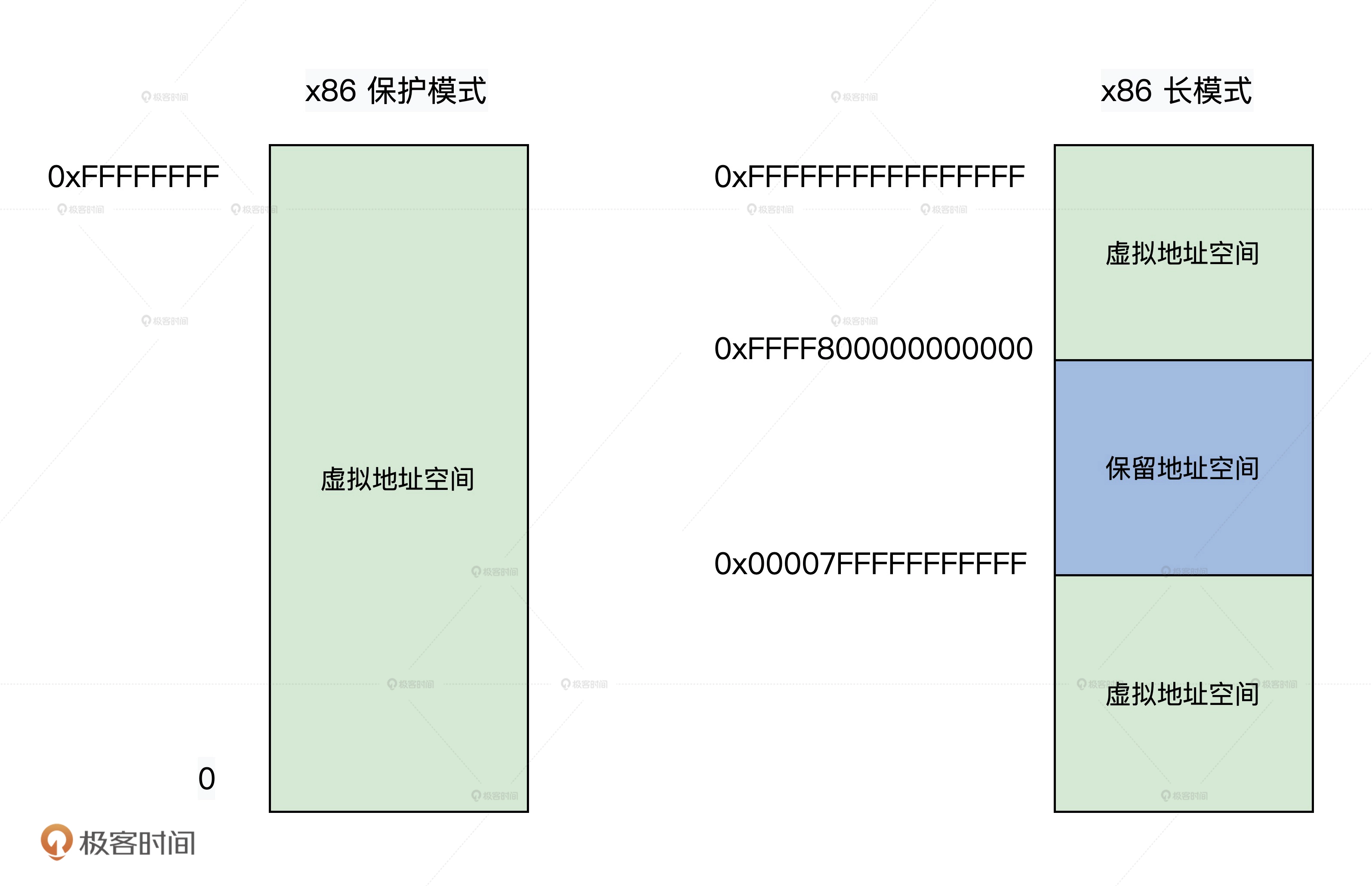
长模式下地址分成了三段,CPU目前只实现了 48位地址空间,高16位要么全是0,要么全是1
第二十一讲 如何分配和释放虚拟内存
第二十二讲 Linux伙伴系统
Linux使用伙伴系统来管理物理内存页面
如何表示一个页
早期 Linux 使用位图,后来使用字节数组,目前使用 page 结构体表示
如何表示一个区
属性相同的物理内存页,归结到同一个区
可使用 cat /proc/zoneinfo | grep None 查看分区
Linux 使用 zone 结构体表示一个区,其中 free_area[MAX_ORDER]结构体数组分别
表示挂载地址连续的 pages, 可能的数量为 1, 2, 4, …, 1024
如何表示一个内存节点
在多核服务器中,每个核都会有自己的本地内存,访问自己的本地内存比较快,
访问其他核的本地内存就比较慢,这个结构称之为 Non-Uniform Memory Access (NUMA)
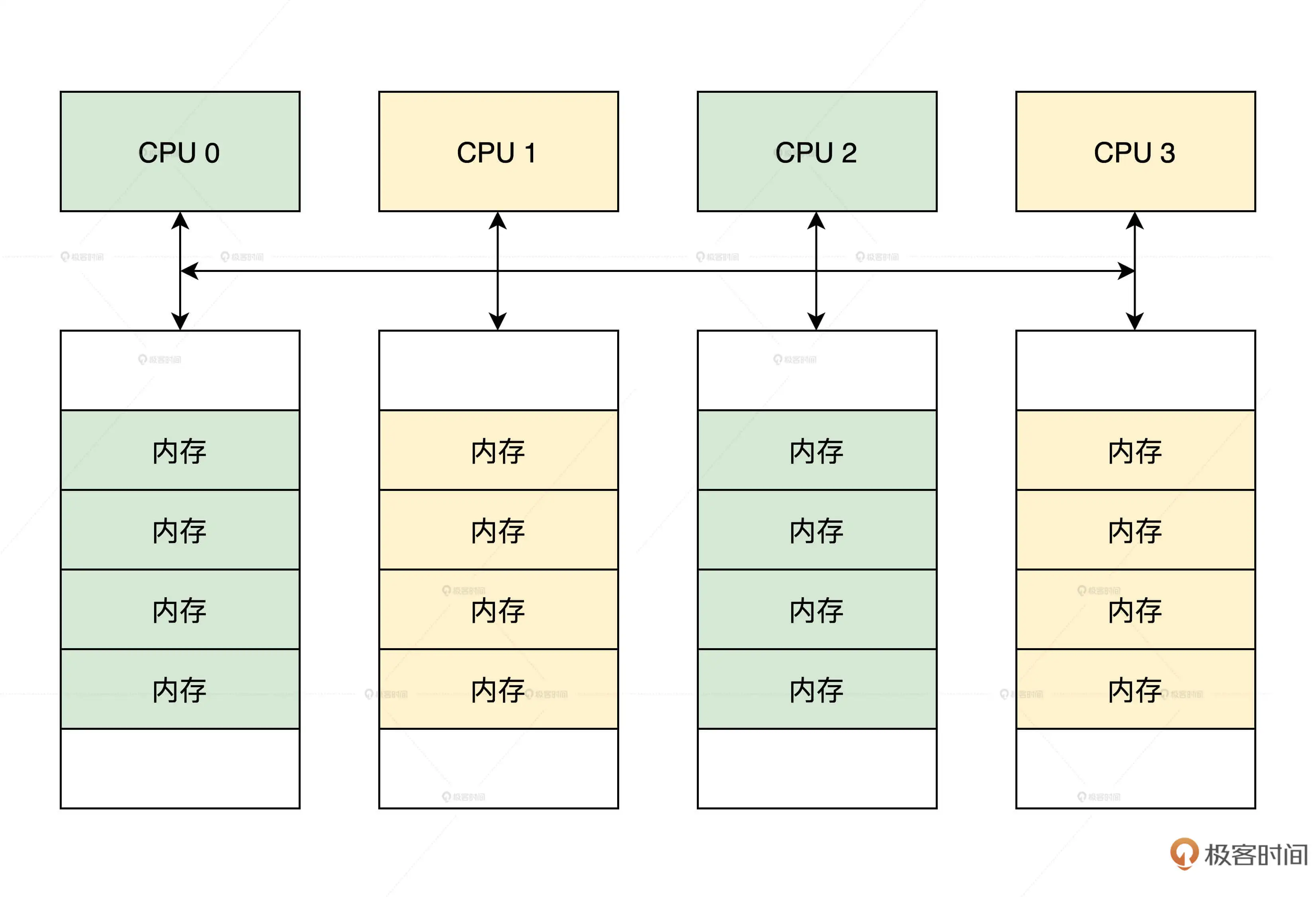
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
enum {
ZONELIST_FALLBACK,
#ifdef CONFIG_NUMA
ZONELIST_NOFALLBACK,
#endif
MAX_ZONELISTS
};
struct zoneref {
struct zone *zone;//内存区指针
int zone_idx; //内存区对应的索引
};
struct zonelist {
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
};
//zone枚举类型 从0开始
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
//定义MAX_NR_ZONES为__MAX_NR_ZONES 最大为6
DEFINE(MAX_NR_ZONES, __MAX_NR_ZONES);
//内存节点
typedef struct pglist_data {
//定一个内存区数组,最大为6个zone元素
struct zone node_zones[MAX_NR_ZONES];
//两个zonelist,一个是指向本节点的的内存区,另一个指向由本节点分配不到内存时可选的备用内存区。
struct zonelist node_zonelists[MAX_ZONELISTS];
//本节点有多少个内存区
int nr_zones;
//本节点开始的page索引号
unsigned long node_start_pfn;
//本节点有多少个可用的页面
unsigned long node_present_pages;
//本节点有多少个可用的页面包含内存空洞
unsigned long node_spanned_pages;
//节点id
int node_id;
//交换内存页面相关的字段
wait_queue_head_t kswapd_wait;
wait_queue_head_t pfmemalloc_wait;
struct task_struct *kswapd;
//本节点保留的内存页面
unsigned long totalreserve_pages;
//自旋锁
spinlock_t lru_lock;
} pg_data_t;
|
pglist_data 结构包含 长度为 2 的 zonelist 数组,第一个 zonelist 指向本节点内的内存区,另一个指向
其他节点内存区,以便本节点内存不足时备用
pglist_data、zonelist、zone、 page之间的关系如下图
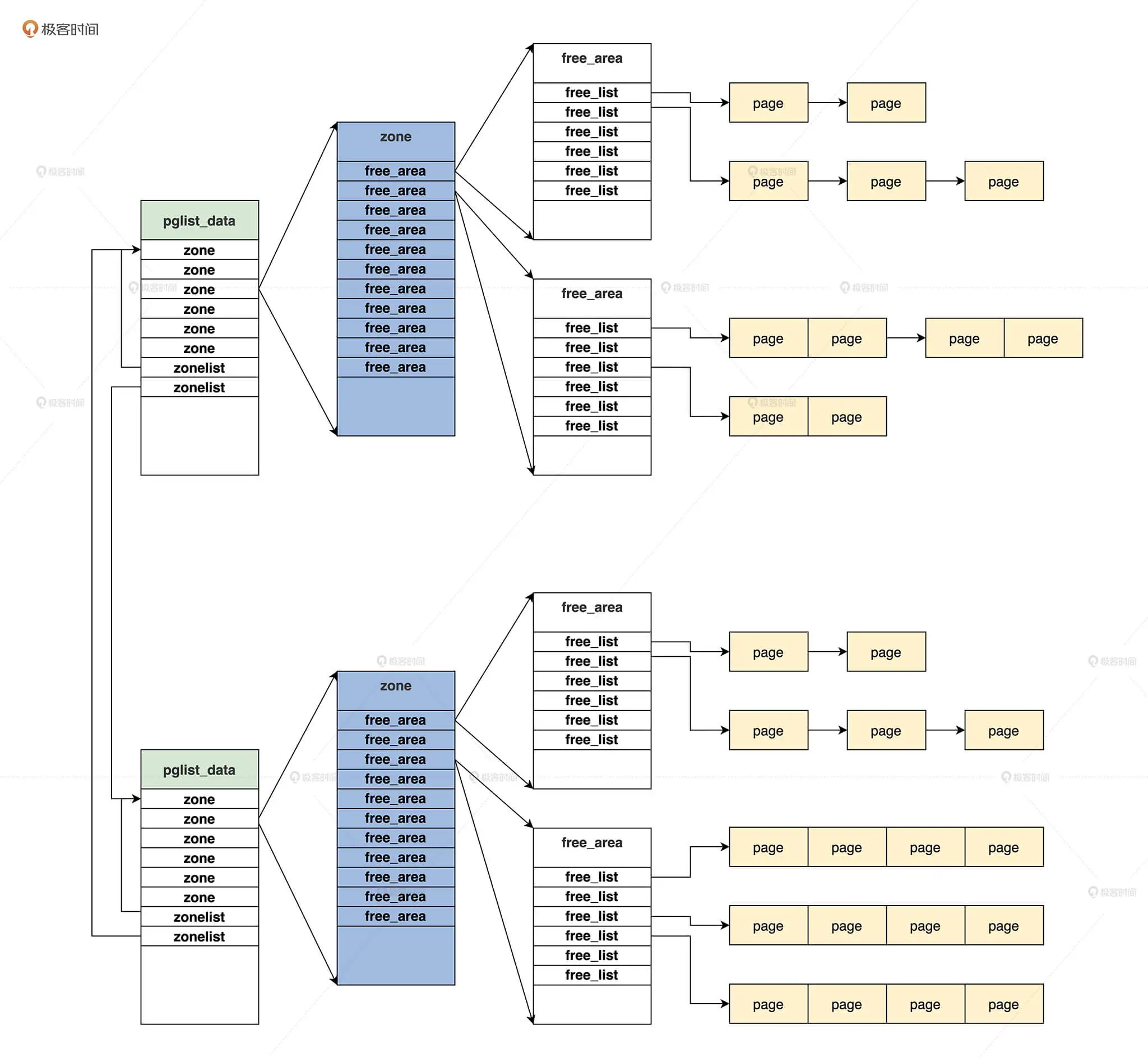
何为伙伴
page(0, 1) 是伙伴, page(2, 3) 是伙伴,A 和 B 是伙伴, E 和 F 是伙伴
页面分配流程
首先找到内存节点, 接着找到内存区, 然后找到合适的空闲链表 ,最后在其中找到 page, 完成物理内存分配
第二十三讲 Linux SLAB分配内存
对于小对象,使用SLAB分配器分配
SLAB将一组连续的内存页划分成相同大小的块,这种块称之为 SLAB 对象,除此之外,
还有 SLAB 管理头和着色区。
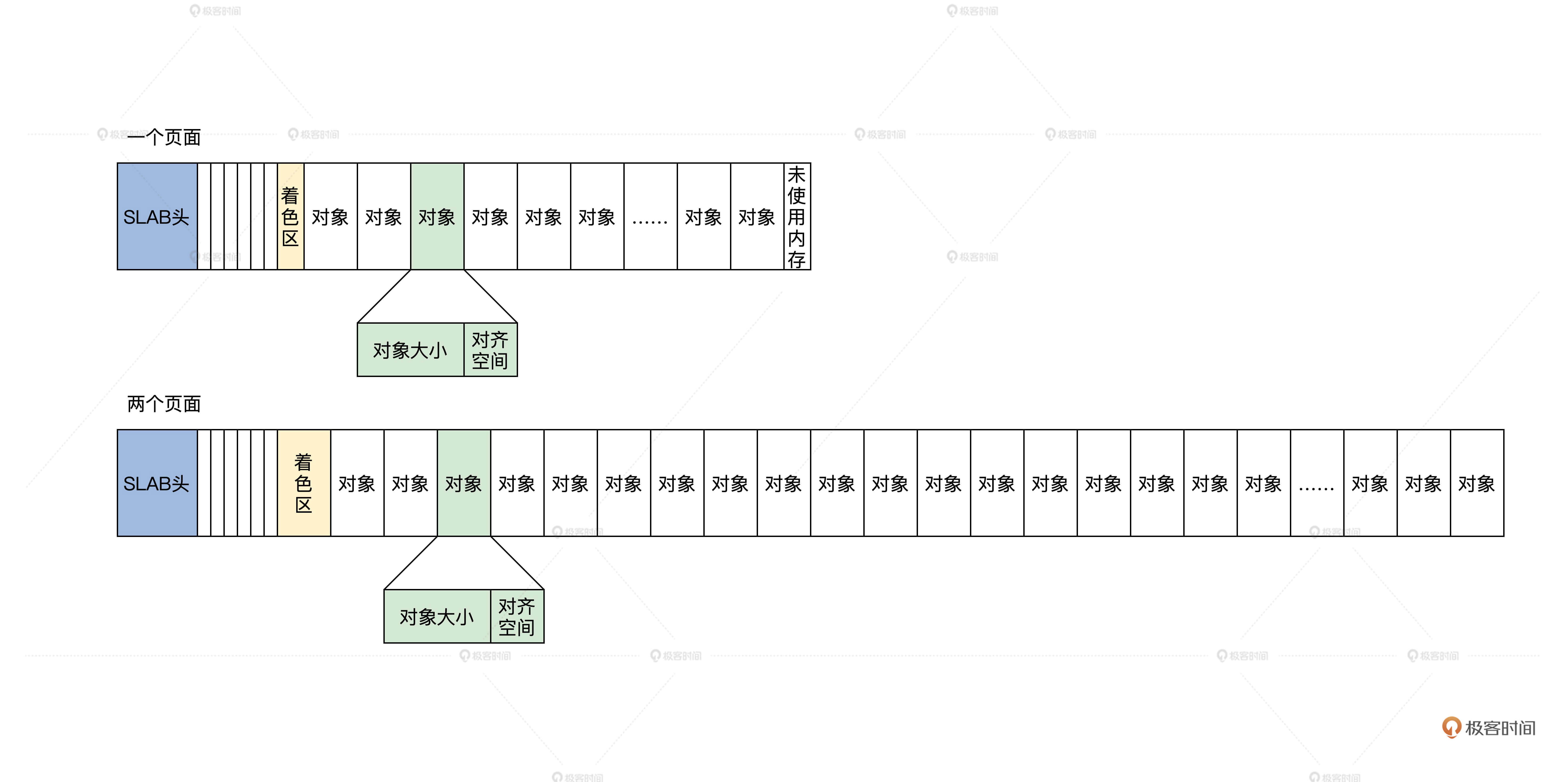
SLAB管理头用 kmem_cache 结构表示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
struct array_cache {
unsigned int avail;
unsigned int limit;
void *entry[];
};
struct kmem_cache {
//是每个CPU一个array_cache类型的变量,cpu_cache是用于管理空闲对象的
struct array_cache __percpu *cpu_cache;
unsigned int size; //cache大小
slab_flags_t flags;//slab标志
unsigned int num;//对象个数
unsigned int gfporder;//分配内存页面的order
gfp_t allocflags;
size_t colour;//着色区大小
unsigned int colour_off;//着色区的开始偏移
const char *name;//本SLAB的名字
struct list_head list;//所有的SLAB都要链接起来
int refcount;//引用计数
int object_size;//对象大小
int align;//对齐大小
struct kmem_cache_node *node[MAX_NUMNODES];//指向管理kmemcache的上层结构
};
|
不同对象大小会有 不同 的kmem_cache,
一个kmem_cache中,每个CPU都有自己的 array_cache,entry[] 是一个 LIFO 顺序数组 ,avail 和 limit
分别指定了当前可用对象的数目和允许容纳的最大数目
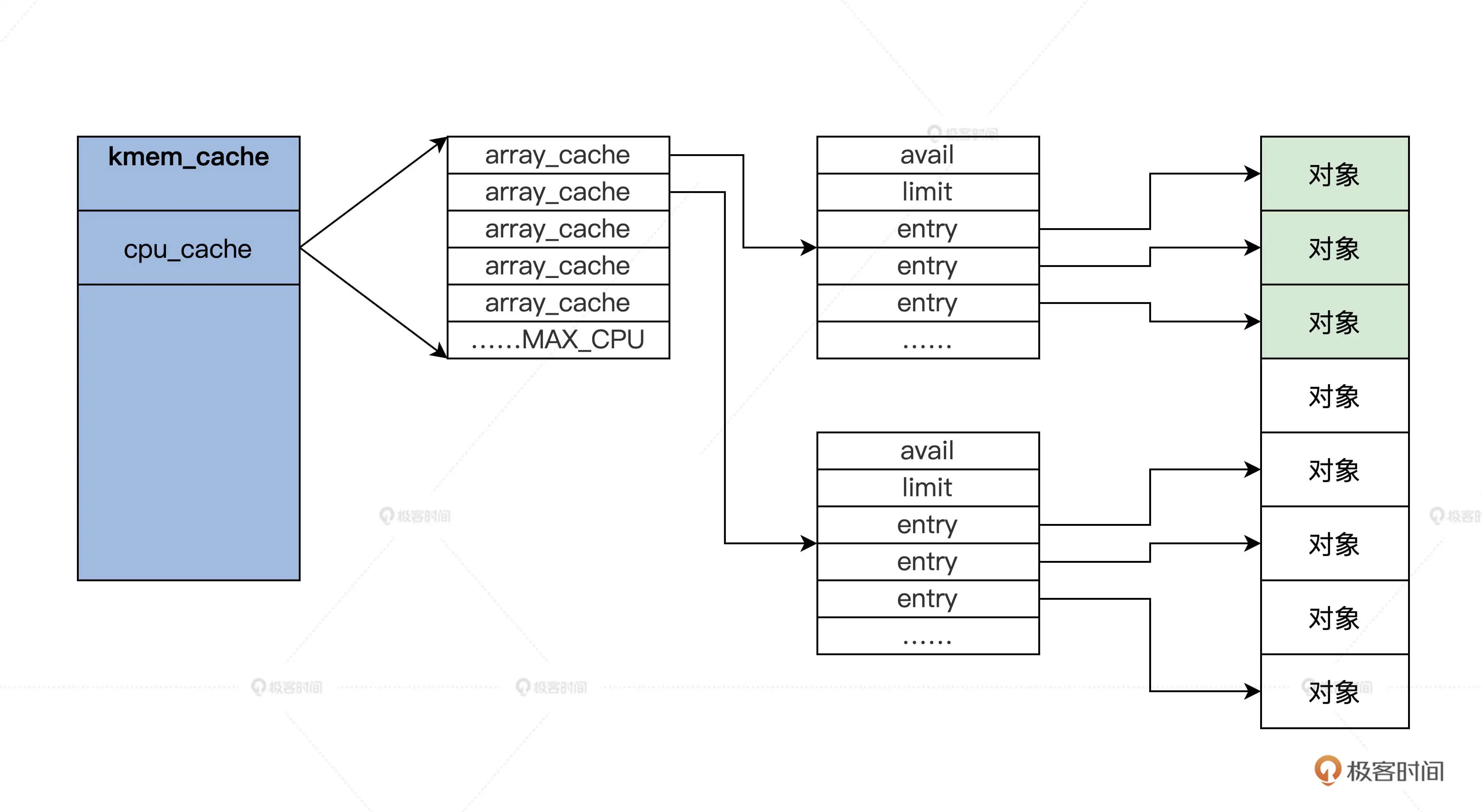
第一个kmem_cache
第一个kmem_cache是静态定义在代码中的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
static struct kmem_cache kmem_cache_boot = {
.batchcount = 1,
.limit = BOOT_CPUCACHE_ENTRIES,
.shared = 1,
.size = sizeof(struct kmem_cache),
.name = "kmem_cache",
};
void __init kmem_cache_init(void)
{
int i;
//指向静态定义的kmem_cache_boot
kmem_cache = &kmem_cache_boot;
for (i = 0; i < NUM_INIT_LISTS; i++)
kmem_cache_node_init(&init_kmem_cache_node[i]);
//建立保存kmem_cache结构的kmem_cache
create_boot_cache(kmem_cache, "kmem_cache",
offsetof(struct kmem_cache, node) +
nr_node_ids * sizeof(struct kmem_cache_node *),
SLAB_HWCACHE_ALIGN, 0, 0);
//加入全局slab_caches链表中
list_add(&kmem_cache->list, &slab_caches);
{
int nid;
for_each_online_node(nid) {
init_list(kmem_cache, &init_kmem_cache_node[CACHE_CACHE + nid], nid);
init_list(kmalloc_caches[KMALLOC_NORMAL][INDEX_NODE], &init_kmem_cache_node[SIZE_NODE + nid], nid);
}
}
//建立kmalloc函数使用的的kmem_cache
create_kmalloc_caches(ARCH_KMALLOC_FLAGS);
}
|
管理 kmem_cache
使用 kem_cache_node 结构体管理 kmem_cache
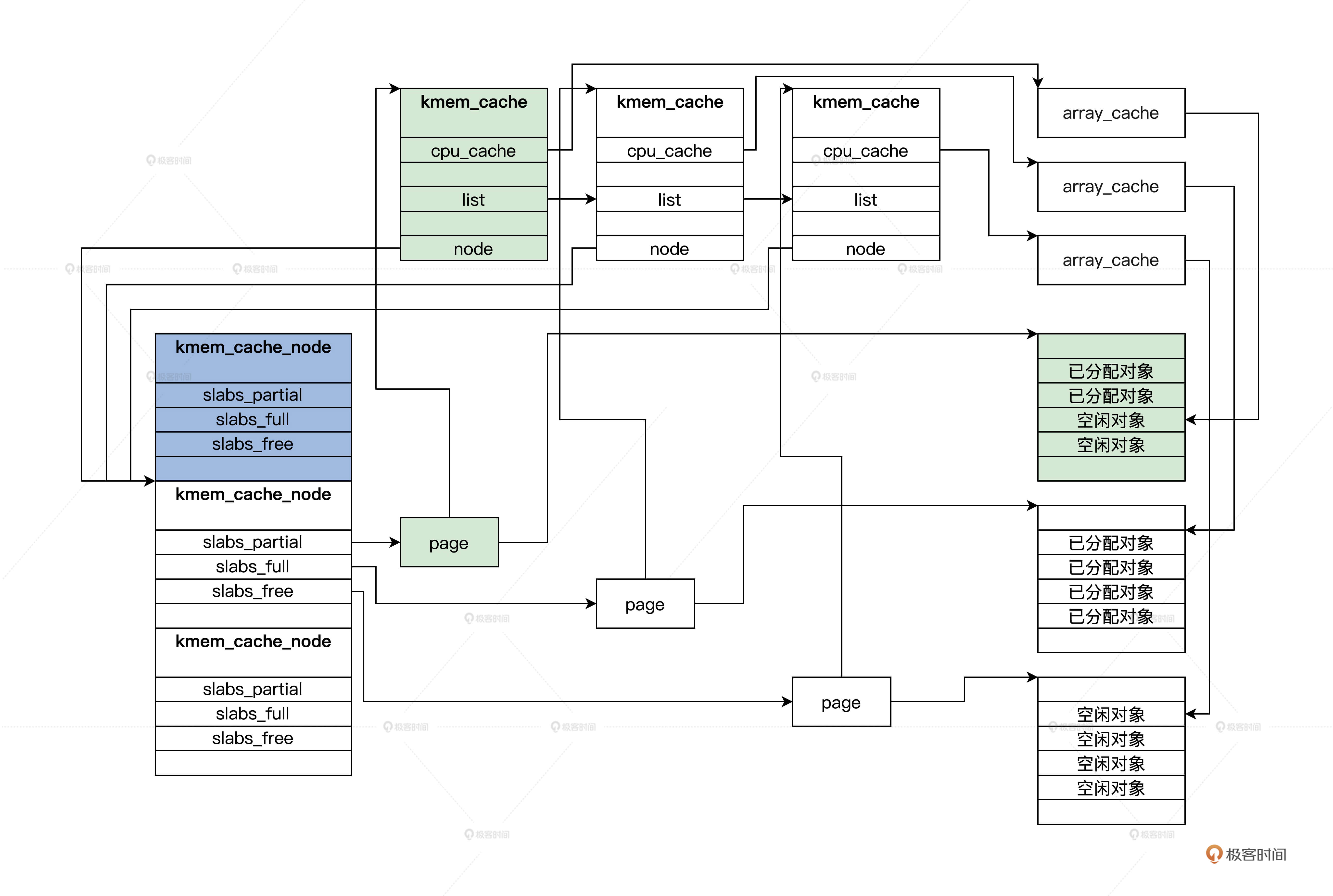
SLAB分配对象
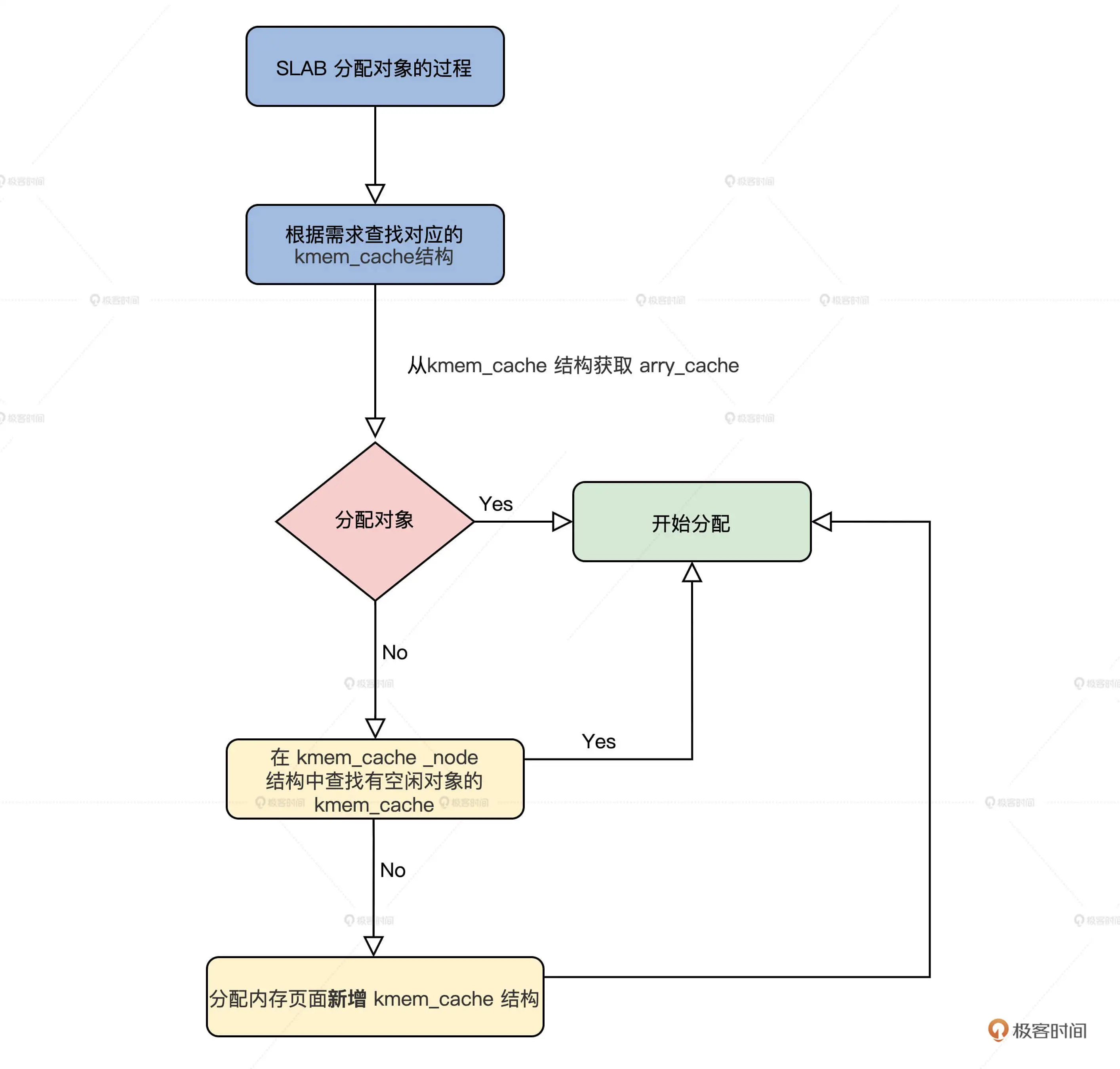
第二十四讲 什么是进程
进程的结构
进程是一个应用程序运行时刻的实例
每个进程拥有整个CPU虚拟地址空间,
空间分为两部分,上半部分是所有进程共享的内核部分,里面放着放着一份内核代码和数据,
下半部分是应用程序
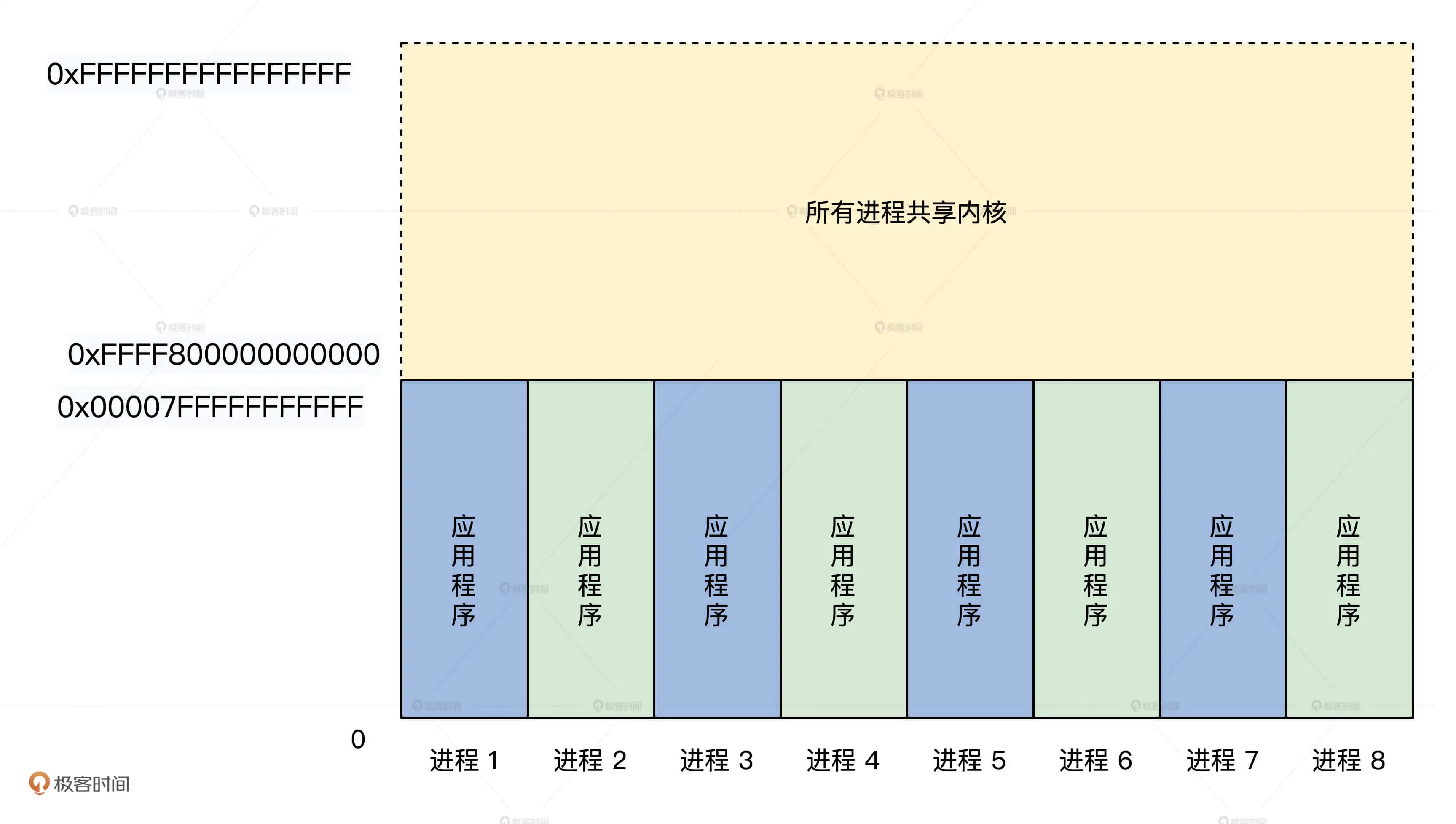
当 CPU 在 R0 特权级别运行时,就运行在上半部分的内核空间地址,当
CPU 在 R3 特权级别运行时,就运行在下半部分的应用程序地址空间
各进程的虚拟地址空间是相同的,他们之间的物理空间不同,是由 MMU 页表进行隔离的
内核服务机制:通过挺住应用程序的代码运行,进入内核地址空间运行内核代码,然后返回结果。这个过程内核需要记录每个应用程序访问了哪些资源,通过资源描述符表示。
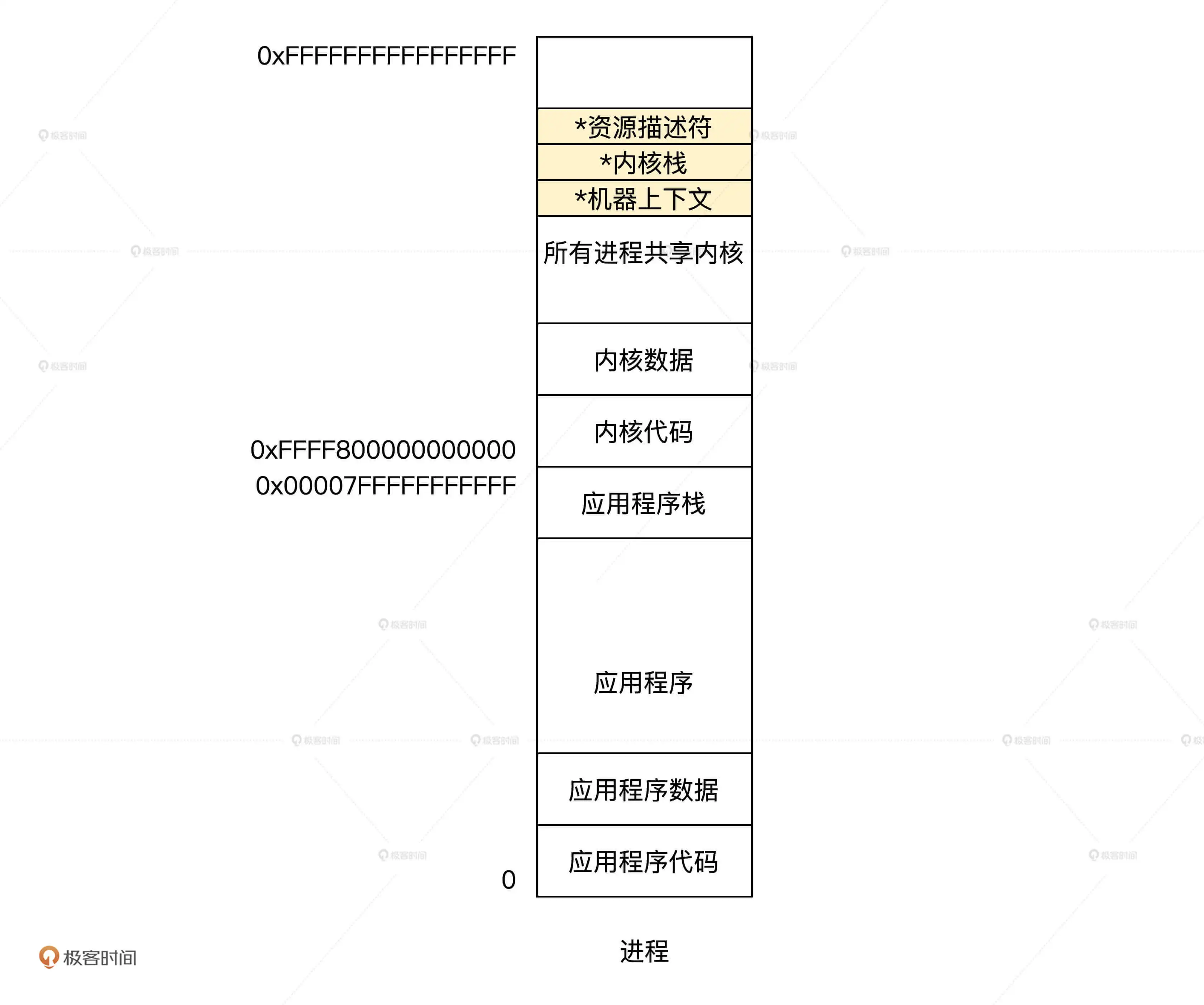
上图中带 * 号的部分每个进程都独有一份
实现进程
如何表示一个进程
一个进程,通常有状态, id, 运行时间,优先级,应用程序栈,内核栈,机器上下文,资源描述符,地址空间等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
typedef struct s_THREAD
{
spinlock_t td_lock; //进程的自旋锁
list_h_t td_list; //进程链表
uint_t td_flgs; //进程的标志
uint_t td_stus; //进程的状态
uint_t td_cpuid; //进程所在的CPU的id
uint_t td_id; //进程的id
uint_t td_tick; //进程运行了多少tick
uint_t td_privilege; //进程的权限
uint_t td_priority; //进程的优先级
uint_t td_runmode; //进程的运行模式
adr_t td_krlstktop; //应用程序内核栈顶地址
adr_t td_krlstkstart; //应用程序内核栈开始地址
adr_t td_usrstktop; //应用程序栈顶地址
adr_t td_usrstkstart; //应用程序栈开始地址
mmadrsdsc_t* td_mmdsc; //地址空间结构
context_t td_context; //机器上下文件结构
objnode_t* td_handtbl[TD_HAND_MAX];//打开的对象数组
}thread_t;
|
在 Cosmos 中,我们使用 thread_t 结构表示一个进程
进程的内核栈和应用程序栈是两块内存空间
进程的权限区分进程是用户进程还是系统进程
进程打开的文件对应的资源描述符保存在 td_handtbl 数据中
进程的地址空间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
typedef struct s_MMADRSDSC
{
spinlock_t msd_lock; //保护自身的自旋锁
list_h_t msd_list; //链表
uint_t msd_flag; //状态和标志
uint_t msd_stus;
uint_t msd_scount; //计数,该结构可能被共享
sem_t msd_sem; //信号量
mmudsc_t msd_mmu; //MMU页表相关的信息
virmemadrs_t msd_virmemadrs; //虚拟地址空间结构
adr_t msd_stext; //应用的指令区的开始、结束地址
adr_t msd_etext;
adr_t msd_sdata; //应用的数据区的开始、结束地址
adr_t msd_edata;
adr_t msd_sbss; //应用初始化为0的区域开始、结束地址
adr_t msd_ebss;
adr_t msd_sbrk; //应用的堆区的开始、结束地址
adr_t msd_ebrk;
}mmadrsdsc_t;
|
使用 mmadrsdsc_t 结构体表示一个进程的完整的地址空间
进程的机器上下文
机器的上下文分为两部分:CPU 寄存器;内核函数调用路径。
中断发生时,CPU 通用寄存器会压入内核栈中
进程切换函数中会保存栈寄存器的值, 用 context_t 结构体表示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
typedef struct s_CONTEXT
{
uint_t ctx_nextrip; //保存下一次运行的地址
uint_t ctx_nextrsp; //保存下一次运行时内核栈的地址
x64tss_t* ctx_nexttss; //指向tss结构
}context_t;
// cosmos/hal/x86/halglobal.c
// 每个CPU核心一个tss
HAL_DEFGLOB_VARIABLE(x64tss_t,x64tss)[CPUCORE_MAX];
typedef struct s_X64TSS
{
u32_t reserv0; //保留
u64_t rsp0; //R0特权级的栈地址
u64_t rsp1; //R1特权级的栈地址,我们未使用
u64_t rsp2; //R2特权级的栈地址,我们未使用
u64_t reserv28;//保留
u64_t ist[7]; //我们未使用
u64_t reserv92;//保留
u16_t reserv100;//保留
u16_t iobase; //我们未使用
}__attribute__((packed)) x64tss_t;
|
建立进程
建立进程是会创建 thread_t 结构的变量实例,并建立对应的应用程序栈、内核栈和进程地址空间。
内核进程的的区别在于这个进程只会在内核地址空间中运行,
用户进程会多分配一个应用程序栈,除了十分内核空间页表外,多了一份用户空间页表
第二十五讲 多进程如何调度
管理进程
进程的生命周期
我们定义进程有如下状态
1
2
3
4
5
|
#define TDSTUS_RUN 0 //进程运行状态
#define TDSTUS_SLEEP 3 //进程睡眠状态
#define TDSTUS_WAIT 4 //进程等待状态
#define TDSTUS_NEW 5 //进程新建状态
#define TDSTUS_ZOMB 6 //进程僵死状态
|
进程状态切换如下
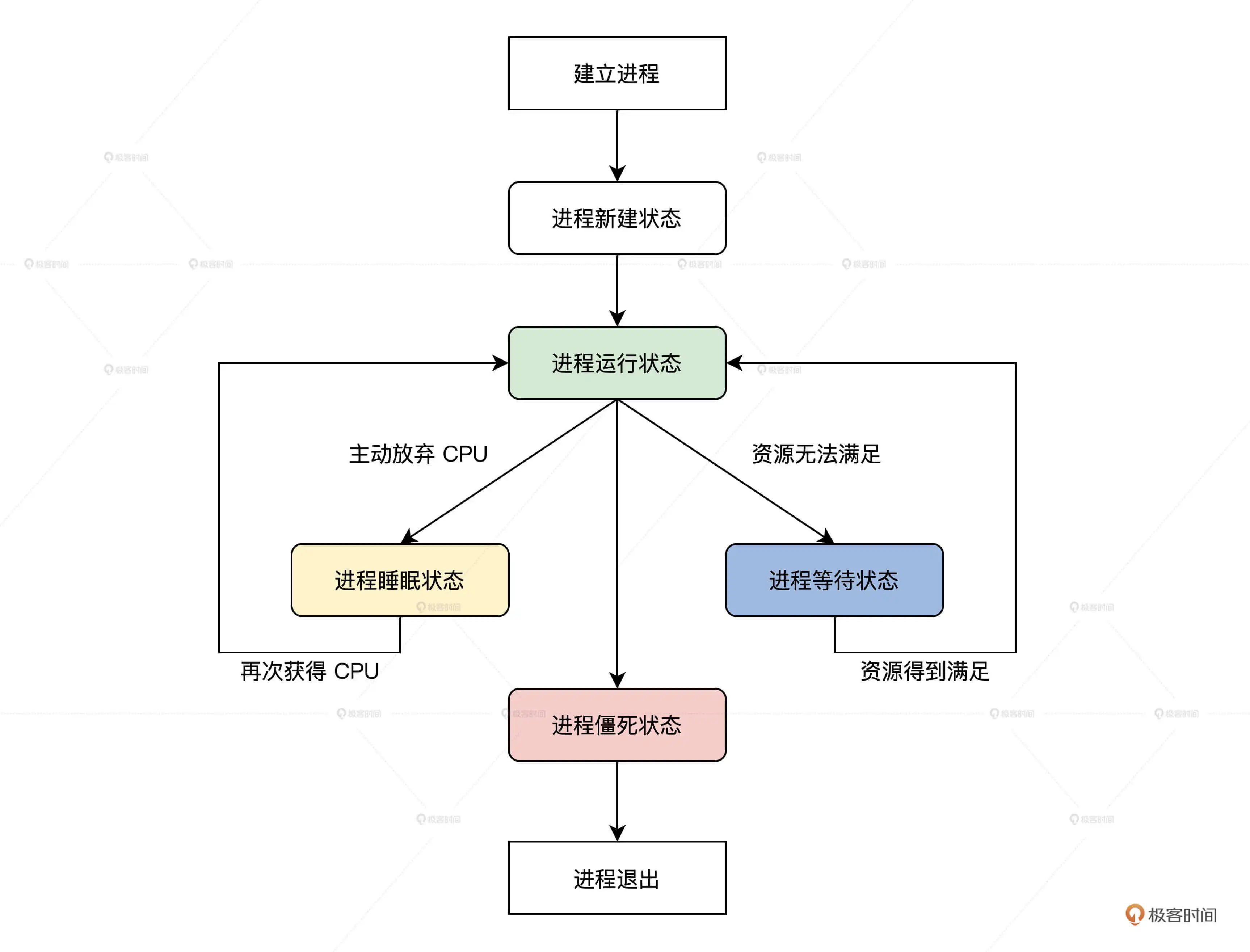
如何组织进程
由于进程随时可能创建或退出,我们使用灵活的链表结构组织进程,由于进程有优先级,
我们设计每个优先级对应一个链表头
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
typedef struct s_THRDLST
{
list_h_t tdl_lsth; //挂载进程的链表头
thread_t* tdl_curruntd; //该链表上正在运行的进程
uint_t tdl_nr; //该链表上进程个数
}thrdlst_t;
typedef struct s_SCHDATA
{
spinlock_t sda_lock; //自旋锁
uint_t sda_cpuid; //当前CPU id
uint_t sda_schdflgs; //标志
uint_t sda_premptidx; //进程抢占计数
uint_t sda_threadnr; //进程数
uint_t sda_prityidx; //当前优先级
thread_t* sda_cpuidle; //当前CPU的空转进程
thread_t* sda_currtd; //当前正在运行的进程
thrdlst_t sda_thdlst[PRITY_MAX]; //进程链表数组
}schdata_t;
typedef struct s_SCHEDCALSS
{
spinlock_t scls_lock; //自旋锁
uint_t scls_cpunr; //CPU个数
uint_t scls_threadnr; //系统中所有的进程数
uint_t scls_threadid_inc; //分配进程id所用
schdata_t scls_schda[CPUCORE_MAX]; //每个CPU调度数据结构
}schedclass_t;
|
设计进程调度器
进程调度器入口
找到当前运行的进程和下一运行的进程,从当前进程切换到下一进程
为简单起见,我们选择优先级最高的进程为下一运行的进程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
void krlschedul()
{
thread_t *prev = krlsched_retn_currthread(),//返回当前运行进程
*next = krlsched_select_thread();//选择下一个运行的进程
save_to_new_context(next, prev);//从当前进程切换到下一个进程
return;
}
thread_t *krlsched_retn_currthread()
{
uint_t cpuid = hal_retn_cpuid();
//通过cpuid获取当前cpu的调度数据结构
schdata_t *schdap = &osschedcls.scls_schda[cpuid];
if (schdap->sda_currtd == NULL)
{//若调度数据结构中当前运行进程的指针为空,就出错死机
hal_sysdie("schdap->sda_currtd NULL");
}
return schdap->sda_currtd;//返回当前运行的进程
}
thread_t *krlsched_select_thread()
{
thread_t *retthd, *tdtmp;
cpuflg_t cufg;
uint_t cpuid = hal_retn_cpuid();
schdata_t *schdap = &osschedcls.scls_schda[cpuid];
krlspinlock_cli(&schdap->sda_lock, &cufg);
for (uint_t pity = 0; pity < PRITY_MAX; pity++)
{//从最高优先级开始扫描
if (schdap->sda_thdlst[pity].tdl_nr > 0)
{//若当前优先级的进程链表不为空
if (list_is_empty_careful(&(schdap->sda_thdlst[pity].tdl_lsth)) == FALSE)
{//取出当前优先级进程链表下的第一个进程
tdtmp = list_entry(schdap->sda_thdlst[pity].tdl_lsth.next, thread_t, td_list);
list_del(&tdtmp->td_list);//脱链
if (schdap->sda_thdlst[pity].tdl_curruntd != NULL)
{//将这sda_thdlst[pity].tdl_curruntd的进程挂入链表尾
list_add_tail(&(schdap->sda_thdlst[pity].tdl_curruntd->td_list), &schdap->sda_thdlst[pity].tdl_lsth);
}
schdap->sda_thdlst[pity].tdl_curruntd = tdtmp;
retthd = tdtmp;//将选择的进程放入sda_thdlst[pity].tdl_curruntd中,并返回
goto return_step;
}
if (schdap->sda_thdlst[pity].tdl_curruntd != NULL)
{//若sda_thdlst[pity].tdl_curruntd不为空就直接返回它
retthd = schdap->sda_thdlst[pity].tdl_curruntd;
goto return_step;
}
}
}
//如果最后也没有找到进程就返回默认的空转进程
schdap->sda_prityidx = PRITY_MIN;
retthd = krlsched_retn_idlethread();
return_step:
//解锁并返回进程
krlspinunlock_sti(&schdap->sda_lock, &cufg);
return retthd;
}
|
进程切换
假设进程 P1 调用的函数 A,接着在函数 A 中调用了函数 B,然后函数 B 调用了函数 C,
最后在函数 C 中调用了调度器函数 S,这个函数 A 到函数 S 的路径就是进程 P1 的函数调用路径
- 将当前进程的通用寄存器保存到单签进程的内核栈中
- 保存 CPU 的 RSP 寄存器到当前进程的机器上下文结构中
- 读取保存在下一进程机器上下文结构中的 RSP 值,保存到 RSP 寄存器中
- 切换 MMU 页表
- 从下一个进程的内核栈中恢复通用寄存器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
void save_to_new_context(thread_t *next, thread_t *prev)
{
__asm__ __volatile__(
"pushfq \n\t"//保存当前进程的标志寄存器
"cli \n\t" //关中断
//保存当前进程的通用寄存器
"pushq %%rax\n\t"
"pushq %%rbx\n\t"
"pushq %%rcx\n\t"
"pushq %%rdx\n\t"
"pushq %%rbp\n\t"
"pushq %%rsi\n\t"
"pushq %%rdi\n\t"
"pushq %%r8\n\t"
"pushq %%r9\n\t"
"pushq %%r10\n\t"
"pushq %%r11\n\t"
"pushq %%r12\n\t"
"pushq %%r13\n\t"
"pushq %%r14\n\t"
"pushq %%r15\n\t"
//保存CPU的RSP寄存器到当前进程的机器上下文结构中
"movq %%rsp,%[PREV_RSP] \n\t"
//把下一个进程的机器上下文结构中的RSP的值,写入CPU的RSP寄存器中
"movq %[NEXT_RSP],%%rsp \n\t"//事实上这里已经切换到下一个进程了,因为切换进程的内核栈
//调用__to_new_context函数切换MMU页表
"callq __to_new_context\n\t"
//恢复下一个进程的通用寄存器
"popq %%r15\n\t"
"popq %%r14\n\t"
"popq %%r13\n\t"
"popq %%r12\n\t"
"popq %%r11\n\t"
"popq %%r10\n\t"
"popq %%r9\n\t"
"popq %%r8\n\t"
"popq %%rdi\n\t"
"popq %%rsi\n\t"
"popq %%rbp\n\t"
"popq %%rdx\n\t"
"popq %%rcx\n\t"
"popq %%rbx\n\t"
"popq %%rax\n\t"
"popfq \n\t" //恢复下一个进程的标志寄存器
//输出当前进程的内核栈地址
: [ PREV_RSP ] "=m"(prev->td_context.ctx_nextrsp)
//读取下一个进程的内核栈地址
: [ NEXT_RSP ] "m"(next->td_context.ctx_nextrsp), "D"(next), "S"(prev)//为调用__to_new_context函数传递参数
: "memory");
return;
}
|
第二十六讲 如何实现进程的等待与唤醒
进程的等待和唤醒
等待数据结构
1
2
3
4
5
6
|
typedef struct s_KWLST
{
spinlock_t wl_lock; //自旋锁
uint_t wl_tdnr; //等待进程的个数
list_h_t wl_list; //挂载等待进程的链表头
}kwlst_t;
|
进程等待
设置进程状态为等待状态,从调度系统数据结构中脱离,然后加入到 kwlst_t 等待结构中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
void krlsched_wait(kwlst_t *wlst)
{
cpuflg_t cufg, tcufg;
uint_t cpuid = hal_retn_cpuid();
schdata_t *schdap = &osschedcls.scls_schda[cpuid];
//获取当前正在运行的进程
thread_t *tdp = krlsched_retn_currthread();
uint_t pity = tdp->td_priority;
krlspinlock_cli(&schdap->sda_lock, &cufg);
krlspinlock_cli(&tdp->td_lock, &tcufg);
tdp->td_stus = TDSTUS_WAIT;//设置进程状态为等待状态
list_del(&tdp->td_list);//脱链
krlspinunlock_sti(&tdp->td_lock, &tcufg);
if (schdap->sda_thdlst[pity].tdl_curruntd == tdp)
{
schdap->sda_thdlst[pity].tdl_curruntd = NULL;
}
schdap->sda_thdlst[pity].tdl_nr--;
krlspinunlock_sti(&schdap->sda_lock, &cufg);
krlwlst_add_thread(wlst, tdp);//将进程加入等待结构中
return;
}
|
进程唤醒
从等待数据结构中获取进程,设置状态为运行状态,最后加到到进程调度数据结构中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
void krlsched_up(kwlst_t *wlst)
{
cpuflg_t cufg, tcufg;
uint_t cpuid = hal_retn_cpuid();
schdata_t *schdap = &osschedcls.scls_schda[cpuid];
thread_t *tdp;
uint_t pity;
//取出等待数据结构第一个进程并从等待数据结构中删除
tdp = krlwlst_del_thread(wlst);
pity = tdp->td_priority;//获取进程的优先级
krlspinlock_cli(&schdap->sda_lock, &cufg);
krlspinlock_cli(&tdp->td_lock, &tcufg);
tdp->td_stus = TDSTUS_RUN;//设置进程的状态为运行状态
krlspinunlock_sti(&tdp->td_lock, &tcufg);
list_add_tail(&tdp->td_list, &(schdap->sda_thdlst[pity].tdl_lsth));//加入进程优先级链表
schdap->sda_thdlst[pity].tdl_nr++;
krlspinunlock_sti(&schdap->sda_lock, &cufg);
return;
}
|
空转进程
当没有任何进程可以调度的时候,需要调度空转进程来运行
建立空转进程
空转进程是一个内核进程,不加入调度系统,使用一个专门的指针指向它
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
|
thread_t *new_cpuidle_thread()
{
thread_t *ret_td = NULL;
bool_t acs = FALSE;
adr_t krlstkadr = NULL;
uint_t cpuid = hal_retn_cpuid();
schdata_t *schdap = &osschedcls.scls_schda[cpuid];
krlstkadr = krlnew(DAFT_TDKRLSTKSZ);//分配进程的内核栈
if (krlstkadr == NULL)
{
return NULL;
}
//分配thread_t结构体变量
ret_td = krlnew_thread_dsc();
if (ret_td == NULL)
{
acs = krldelete(krlstkadr, DAFT_TDKRLSTKSZ);
if (acs == FALSE)
{
return NULL;
}
return NULL;
}
//设置进程具有系统权限
ret_td->td_privilege = PRILG_SYS;
ret_td->td_priority = PRITY_MIN;
//设置进程的内核栈顶和内核栈开始地址
ret_td->td_krlstktop = krlstkadr + (adr_t)(DAFT_TDKRLSTKSZ - 1);
ret_td->td_krlstkstart = krlstkadr;
//初始化进程的内核栈
krlthread_kernstack_init(ret_td, (void *)krlcpuidle_main, KMOD_EFLAGS);
//设置调度系统数据结构的空转进程和当前进程为ret_td
schdap->sda_cpuidle = ret_td;
schdap->sda_currtd = ret_td;
return ret_td;
}
//新建空转进程
void new_cpuidle()
{
thread_t *thp = new_cpuidle_thread();//建立空转进程
if (thp == NULL)
{//失败则主动死机
hal_sysdie("newcpuilde err");
}
kprint("CPUIDLETASK: %x\n", (uint_t)thp);
return;
}
thread_t *new_cpuidle_thread()
{
thread_t *ret_td = NULL;
bool_t acs = FALSE;
adr_t krlstkadr = NULL;
uint_t cpuid = hal_retn_cpuid();
schdata_t *schdap = &osschedcls.scls_schda[cpuid];
krlstkadr = krlnew(DAFT_TDKRLSTKSZ);//分配进程的内核栈
if (krlstkadr == NULL)
{
return NULL;
}
//分配thread_t结构体变量
ret_td = krlnew_thread_dsc();
if (ret_td == NULL)
{
acs = krldelete(krlstkadr, DAFT_TDKRLSTKSZ);
if (acs == FALSE)
{
return NULL;
}
return NULL;
}
//设置进程具有系统权限
ret_td->td_privilege = PRILG_SYS;
ret_td->td_priority = PRITY_MIN;
//设置进程的内核栈顶和内核栈开始地址
ret_td->td_krlstktop = krlstkadr + (adr_t)(DAFT_TDKRLSTKSZ - 1);
ret_td->td_krlstkstart = krlstkadr;
//初始化进程的内核栈
krlthread_kernstack_init(ret_td, (void *)krlcpuidle_main, KMOD_EFLAGS);
//设置调度系统数据结构的空转进程和当前进程为ret_td
schdap->sda_cpuidle = ret_td;
schdap->sda_currtd = ret_td;
return ret_td;
}
//新建空转进程
void new_cpuidle()
{
thread_t *thp = new_cpuidle_thread();//建立空转进程
if (thp == NULL)
{//失败则主动死机
hal_sysdie("newcpuilde err");
}
kprint("CPUIDLETASK: %x\n", (uint_t)thp);
return;
}
|
空转进程运行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
void krlcpuidle_start()
{
uint_t cpuid = hal_retn_cpuid();
schdata_t *schdap = &osschedcls.scls_schda[cpuid];
//取得空转进程
thread_t *tdp = schdap->sda_cpuidle;
//设置空转进程的tss和R0特权级的栈
tdp->td_context.ctx_nexttss = &x64tss[cpuid];
tdp->td_context.ctx_nexttss->rsp0 = tdp->td_krlstktop;
//设置空转进程的状态为运行状态
tdp->td_stus = TDSTUS_RUN;
//启动进程运行
retnfrom_first_sched(tdp);
return;
}
|
第二十七讲 Linux如何实现进程和进程调度
进程
进程数据结构
使用 task_struct 表示一个运行中的应用程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
struct task_struct {
struct thread_info thread_info;//处理器特有数据
volatile long state; //进程状态
void *stack; //进程内核栈地址
refcount_t usage; //进程使用计数
int on_rq; //进程是否在运行队列上
int prio; //动态优先级
int static_prio; //静态优先级
int normal_prio; //取决于静态优先级和调度策略
unsigned int rt_priority; //实时优先级
const struct sched_class *sched_class;//指向其所在的调度类
struct sched_entity se;//普通进程的调度实体
struct sched_rt_entity rt;//实时进程的调度实体
struct sched_dl_entity dl;//采用EDF算法调度实时进程的调度实体
struct sched_info sched_info;//用于调度器统计进程的运行信息
struct list_head tasks;//所有进程的链表
struct mm_struct *mm; //指向进程内存结构
struct mm_struct *active_mm;
pid_t pid; //进程id
struct task_struct __rcu *parent;//指向其父进程
struct list_head children; //链表中的所有元素都是它的子进程
struct list_head sibling; //用于把当前进程插入到兄弟链表中
struct task_struct *group_leader;//指向其所在进程组的领头进程
u64 utime; //用于记录进程在用户态下所经过的节拍数
u64 stime; //用于记录进程在内核态下所经过的节拍数
u64 gtime; //用于记录作为虚拟机进程所经过的节拍数
unsigned long min_flt;//缺页统计
unsigned long maj_flt;
struct fs_struct *fs; //进程相关的文件系统信息
struct files_struct *files;//进程打开的所有文件
struct vm_struct *stack_vm_area;//内核栈的内存区
};
|
创建 task_struct 实例
早期 task_struct 结构和内核栈放在一起,首先分配两个连续的页面
作为进程的内核栈,再把 task_struct 结构体实例放在栈底。
将 RSP 寄存器的值低 13 位清零,就可以得到实例地址
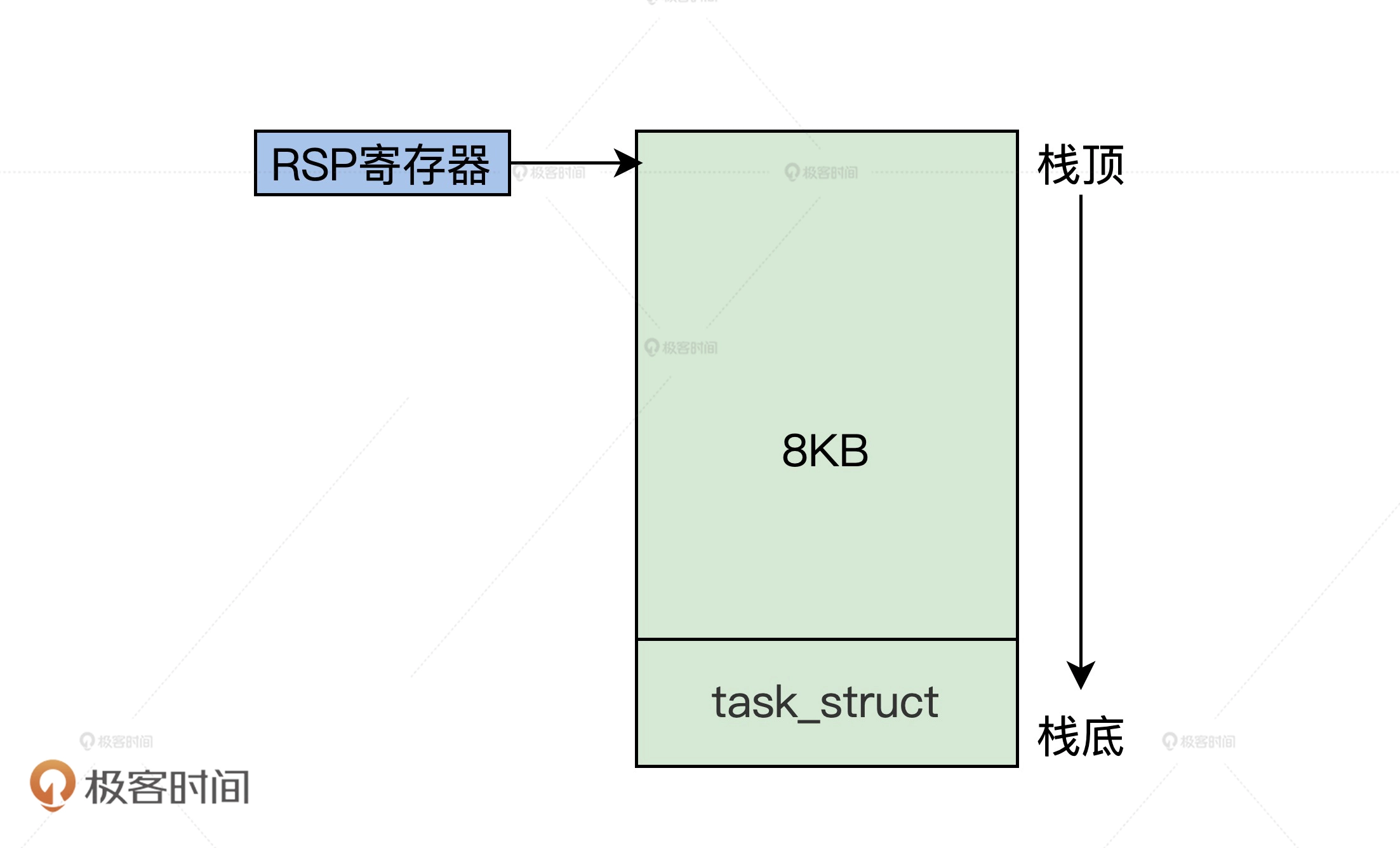
后期随着 task_struct 结构体 越来越大,和内核栈分开了,使用 stack 字段指向内核栈地址
进程地址空间
进程地址空间使用 mm_struct 结构表示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
struct mm_struct {
struct vm_area_struct *mmap; //虚拟地址区间链表VMAs
struct rb_root mm_rb; //组织vm_area_struct结构的红黑树的根
unsigned long task_size; //进程虚拟地址空间大小
pgd_t * pgd; //指向MMU页表
atomic_t mm_users; //多个进程共享这个mm_struct
atomic_t mm_count; //mm_struct结构本身计数
atomic_long_t pgtables_bytes;//页表占用了多个页
int map_count; //多少个VMA
spinlock_t page_table_lock; //保护页表的自旋锁
struct list_head mmlist; //挂入mm_struct结构的链表
//进程应用程序代码开始、结束地址,应用程序数据的开始、结束地址
unsigned long start_code, end_code, start_data, end_data;
//进程应用程序堆区的开始、当前地址、栈开始地址
unsigned long start_brk, brk, start_stack;
//进程应用程序参数区开始、结束地址
unsigned long arg_start, arg_end, env_start, env_end;
};
|
进程文件表
进程打开的文件表使用 files_struct 结构表示
1
2
3
4
5
6
7
8
9
10
11
12
|
struct files_struct {
atomic_t count;//自动计数
struct fdtable __rcu *fdt;
struct fdtable fdtab;
spinlock_t file_lock; //自旋锁
unsigned int next_fd;//下一个文件句柄
unsigned long close_on_exec_init[1];//执行exec()时要关闭的文件句柄
unsigned long open_fds_init[1];
unsigned long full_fds_bits_init[1];
struct file __rcu * fd_array[NR_OPEN_DEFAULT];//默认情况下打开文件的指针数组
};
|
当使用如 int fd = open("/tmp/test.txt") 打开一个文件时,会建立一个 struct file实例与之对应,并加入 fd_array 数组中
Linux在新建一个进程时,会复制当前进程的files_struct结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
static int copy_files(unsigned long clone_flags, struct task_struct *tsk)
{
struct files_struct *oldf, *newf;
int error = 0;
oldf = current->files;//获取当前进程的files_struct的指针
if (!oldf)
goto out;
if (clone_flags & CLONE_FILES) {
atomic_inc(&oldf->count);
goto out;
}
//分配新files_struct结构的实例变量,并复制当前的files_struct结构
newf = dup_fd(oldf, NR_OPEN_MAX, &error);
if (!newf)
goto out;
tsk->files = newf;//新进程的files_struct结构指针指向新的files_struct结构
error = 0;
out:
return error;
|
进程调度
Linux 有多种调度算法,我们具体介绍完全公平调度算法 (CFQ)
进程调度实体数据结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
struct sched_entity {
struct load_weight load;//表示当前调度实体的权重
struct rb_node run_node;//红黑树的数据节点
struct list_head group_node;// 链表节点,被链接到 percpu 的 rq->cfs_tasks
unsigned int on_rq; //当前调度实体是否在就绪队列上
u64 exec_start;//当前实体上次被调度执行的时间
u64 sum_exec_runtime;//当前实体总执行时间
u64 prev_sum_exec_runtime;//截止到上次统计,进程执行的时间
u64 vruntime;//当前实体的虚拟时间
u64 nr_migrations;//实体执行迁移的次数
struct sched_statistics statistics;//统计信息包含进程的睡眠统计、等待延迟统计、CPU迁移统计、唤醒统计等。
#ifdef CONFIG_FAIR_GROUP_SCHED
int depth;// 表示当前实体处于调度组中的深度
struct sched_entity *parent;//指向父级调度实体
struct cfs_rq *cfs_rq;//当前调度实体属于的 cfs_rq.
struct cfs_rq *my_q;
#endif
#ifdef CONFIG_SMP
struct sched_avg avg ;// 记录当前实体对于CPU的负载
#endif
};
|
在 task_struct 结构中 ,会包含至少一个 sched_entity 结构的变量,
可以通过 sched_entity结构地址偏移访问 task_struct 结构
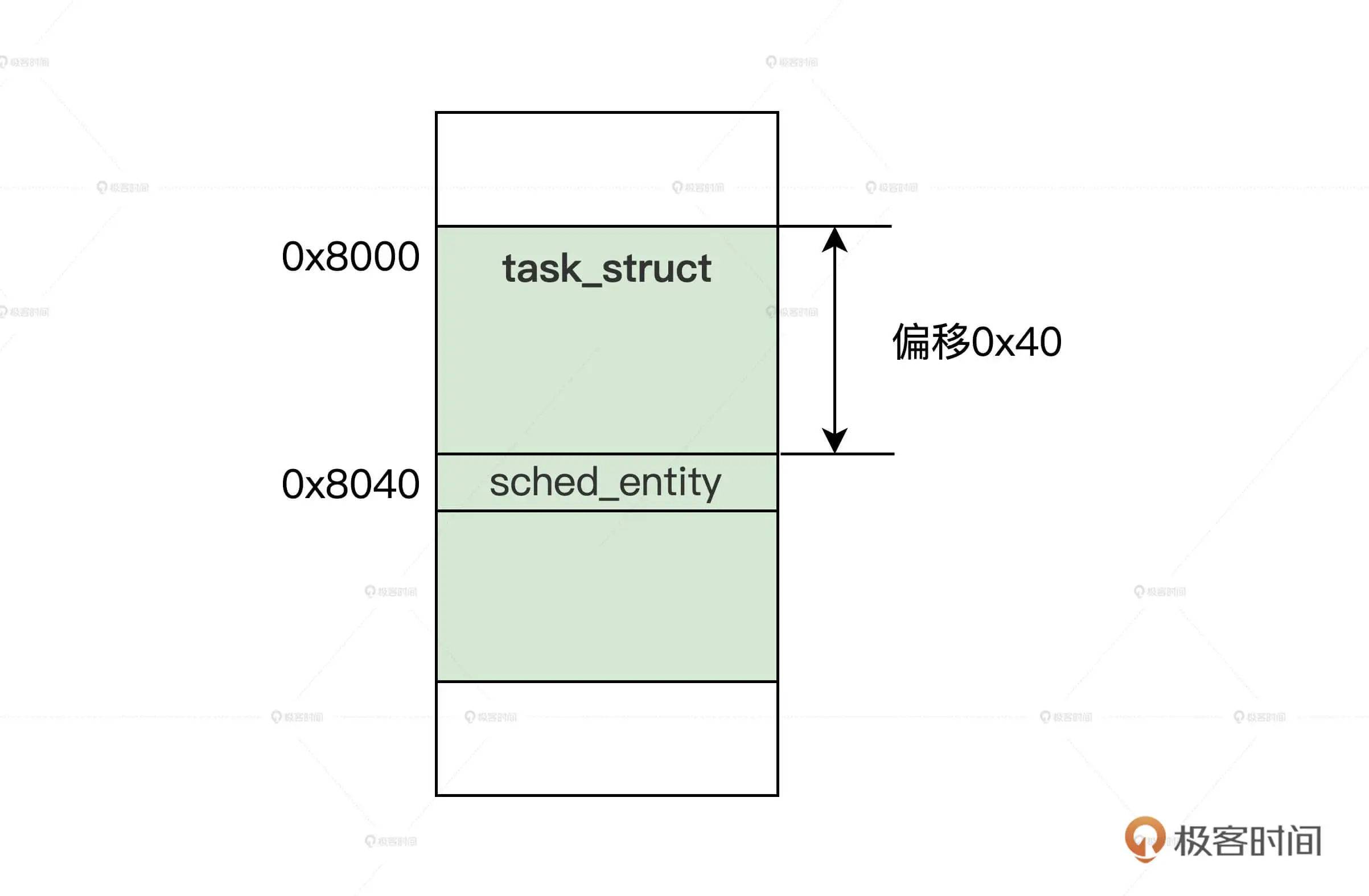
进程运行队列
每个 CPU 分配一个进程运行队列,队列包含多重调度算法的队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
struct rq {
raw_spinlock_t lock;//自旋锁
unsigned int nr_running;//多个就绪运行进程
struct cfs_rq cfs; //作用于完全公平调度算法的运行队列
struct rt_rq rt;//作用于实时调度算法的运行队列
struct dl_rq dl;//作用于EDF调度算法的运行队列
struct task_struct __rcu *curr;//这个运行队列当前正在运行的进程
struct task_struct *idle;//这个运行队列的空转进程
struct task_struct *stop;//这个运行队列的停止进程
struct mm_struct *prev_mm;//这个运行队列上一次运行进程的mm_struct
unsigned int clock_update_flags;//时钟更新标志
u64 clock; //运行队列的时间
//后面的代码省略
};
struct rb_root_cached {
struct rb_root rb_root; //红黑树的根
struct rb_node *rb_leftmost;//红黑树最左子节点
};
struct cfs_rq {
struct load_weight load;//cfs_rq上所有调度实体的负载总和
unsigned int nr_running;//cfs_rq上所有的调度实体不含调度组中的调度实体
unsigned int h_nr_running;//cfs_rq上所有的调度实体包含调度组中所有调度实体
u64 exec_clock;//当前 cfs_rq 上执行的时间
u64 min_vruntime;//最小虚拟运行时间
struct rb_root_cached tasks_timeline;//所有调度实体的根
struct sched_entity *curr;//当前调度实体
struct sched_entity *next;//下一个调度实体
struct sched_entity *last;//上次执行过的调度实体
//省略不关注的代码
};
|
调度实体和运行队列的关系

task_struct 结构中 包含 sched_entity 结构,sched_entity 通过红黑树
组织起来,红黑树的根在 cfs_rq 结构中, cfs_rq 结构又被 包含在 rq 结构中
调度器类
1
2
3
4
5
6
7
8
9
10
|
struct sched_class {
//向运行队列中添加一个进程,入队
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
//向运行队列中删除一个进程,出队
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
//检查当前进程是否可抢占
void (*check_preempt_curr)(struct rq *rq, struct task_struct *p, int flags);
//从运行队列中返回可以投入运行的一个进程
struct task_struct *(*pick_next_task)(struct rq *rq);
} ;
|
Linux 定义了五个 sched_class 结构的实变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
//定义在链接脚本文件中
extern struct sched_class __begin_sched_classes[];
extern struct sched_class __end_sched_classes[];
#define sched_class_highest (__end_sched_classes - 1)
#define sched_class_lowest (__begin_sched_classes - 1)
#define for_class_range(class, _from, _to) \
for (class = (_from); class != (_to); class--)
//遍历每个调度类
#define for_each_class(class) \
for_class_range(class, sched_class_highest, sched_class_lowest)
extern const struct sched_class stop_sched_class;//停止调度类
extern const struct sched_class dl_sched_class;//Deadline调度类
extern const struct sched_class rt_sched_class;//实时调度类
extern const struct sched_class fair_sched_class;//CFS调度类
extern const struct sched_class idle_sched_class;//空转调度类
|
它们的优先级是:stop_sched_class > dl_sched_class > rt_sched_class > fair_sched_class > idle_sched_class
CFS 调度器对应的类
1
2
3
4
5
6
7
8
|
const struct sched_class fair_sched_class
__section("__fair_sched_class") = {
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = __pick_next_task_fair,
};
|
CFS调度器
CFS没有时间片的概念,分配的是CPU时间比例。
举个例子,现在有 A、B 两个进程。进程 A 的权重是 1024,进程 B 的权重是 2048。
那么进程 A 获得 CPU 的时间比例是 1024/(1024+2048) = 33.3%。
进程 B 获得的 CPU 时间比例是 2048/(1024+2048)=66.7%。
进程的时间 = CPU 总时间 * 进程的权重 / 就绪队列所有进程权重之和
通过 nice 值设置进程权重,数据越小,权重越大
1
2
3
4
5
6
7
8
9
10
|
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
|
进程调度延迟
调度延迟指的是保证每个可运行的进程都至少运行一次的时间间隔
当可运行的进程少于等于 8 个时,调度延迟固定为 6ms;超过8个,
就要保证每个进程至少运行一段时间才被调度,这个一段时间叫做 最小调度粒度时间。
CFS 调度器 的默认最小调度粒度时间是 0.75ms
虚拟时间
CFS引入了虚拟时间,保证每个进程允许的虚拟时间相等,
nice 为 0 的进程的虚拟时间和实际时间是相等的
在选择下一个运行的进程时,只需要找到虚拟时间最小的进程就行了
1
|
vruntime = wtime*( NICE_0_LOAD/weight)
|
定时周期调度
Linux会启动定时器,来更新进程的虚拟时间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));//获取当前时间
u64 delta_exec;
delta_exec = now - curr->exec_start;//间隔时间
curr->exec_start = now;
curr->sum_exec_runtime += delta_exec;//累计运行时间
curr->vruntime += calc_delta_fair(delta_exec, curr);//计算进程的虚拟时间
update_min_vruntime(cfs_rq);//更新运行队列中的最小虚拟时间,这是新建进程的虚拟时间,避免一个新建进程因为虚拟时间太小而长时间占用CPU
}
static void entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
update_curr(cfs_rq);//更新当前运行进程和运行队列相关的时间
if (cfs_rq->nr_running > 1)//当运行进程数量大于1就检查是否可抢占
check_preempt_tick(cfs_rq, curr);
}
#define for_each_sched_entity(se) \
for (; se; se = NULL)
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;//获取当前进程的调度实体
for_each_sched_entity(se) {//仅对当前进程的调度实体
cfs_rq = cfs_rq_of(se);//获取当前进程的调度实体对应运行队列
entity_tick(cfs_rq, se, queued);
}
}
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);//获取运行CPU运行进程队列
struct task_struct *curr = rq->curr;//获取当进程
update_rq_clock(rq);//更新运行队列的时间等数据
curr->sched_class->task_tick(rq, curr, 0);//更新当前时间的虚拟时间
}
|
第二十八讲 如何管理设备
计算机的结构
各种设备通过总线相连
设备分类
操作系统内核感知的设备并不需要和物理设备对应,这取决于
设备控制代码的自身行为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
#define NOT_DEVICE 0 //不表示任何设备
#define BRIDGE_DEVICE 4 //总线桥接器设备
#define CPUCORE_DEVICE 5 //CPU设备,CPU也是设备
#define RAMCONTER_DEVICE 6 //内存控制器设备
#define RAM_DEVICE 7 //内存设备
#define USBHOSTCONTER_DEVICE 8 //USB主控制设备
#define INTUPTCONTER_DEVICE 9 //中断控制器设备
#define DMA_DEVICE 10 //DMA设备
#define CLOCKPOWER_DEVICE 11 //时钟电源设备
#define LCDCONTER_DEVICE 12 //LCD控制器设备
#define NANDFLASH_DEVICE 13 //nandflash设备
#define CAMERA_DEVICE 14 //摄像头设备
#define UART_DEVICE 15 //串口设备
#define TIMER_DEVICE 16 //定时器设备
#define USB_DEVICE 17 //USB设备
#define WATCHDOG_DEVICE 18 //看门狗设备
#define RTC_DEVICE 22 //实时时钟设备
#define SD_DEVICE 25 //SD卡设备
#define AUDIO_DEVICE 26 //音频设备
#define TOUCH_DEVICE 27 //触控设备
#define NETWORK_DEVICE 28 //网络设备
#define VIR_DEVICE 29 //虚拟设备
#define FILESYS_DEVICE 30 //文件系统设备
#define SYSTICK_DEVICE 31 //系统TICK设备
#define UNKNOWN_DEVICE 32 //未知设备,也是设备
#define HD_DEVICE 33 //硬盘设备
|
设备驱动
设备
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
typedef struct s_DEVID
{
uint_t dev_mtype;//设备类型号
uint_t dev_stype; //设备子类型号
uint_t dev_nr; //设备序号
}devid_t;
typedef struct s_DEVICE
{
list_h_t dev_list;//设备链表
list_h_t dev_indrvlst; //设备在驱动程序数据结构中对应的挂载链表
list_h_t dev_intbllst; //设备在设备表数据结构中对应的挂载链表
spinlock_t dev_lock; //设备自旋锁
uint_t dev_count; //设备计数
sem_t dev_sem; //设备信号量
uint_t dev_stus; //设备状态
uint_t dev_flgs; //设备标志
devid_t dev_id; //设备ID
uint_t dev_intlnenr; //设备中断服务例程的个数
list_h_t dev_intserlst; //设备中断服务例程的链表
list_h_t dev_rqlist; //对设备的请求服务链表
uint_t dev_rqlnr; //对设备的请求服务个数
sem_t dev_waitints; //用于等待设备的信号量
struct s_DRIVER* dev_drv; //设备对应的驱动程序数据结构的指针
void* dev_attrb; //设备属性指针
void* dev_privdata; //设备私有数据指针
void* dev_userdata;//将来扩展所用
void* dev_extdata;//将来扩展所用
char_t* dev_name; //设备名
}device_t;
|
设备 ID 表示设备的类型和设备号,指向驱动程序的指针用于访问设备时调用设备驱动程序。
驱动程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
typedef struct s_DRIVER
{
spinlock_t drv_lock; //保护驱动程序数据结构的自旋锁
list_h_t drv_list;//挂载驱动程序数据结构的链表
uint_t drv_stuts; //驱动程序的相关状态
uint_t drv_flg; //驱动程序的相关标志
uint_t drv_id; //驱动程序ID
uint_t drv_count; //驱动程序的计数器
sem_t drv_sem; //驱动程序的信号量
void* drv_safedsc; //驱动程序的安全体
void* drv_attrb; //LMOSEM内核要求的驱动程序属性体
void* drv_privdata; //驱动程序私有数据的指针
drivcallfun_t drv_dipfun[IOIF_CODE_MAX]; //驱动程序功能派发函数指针数组
list_h_t drv_alldevlist; //挂载驱动程序所管理的所有设备的链表
drventyexit_t drv_entry; //驱动程序的入口函数指针
drventyexit_t drv_exit; //驱动程序的退出函数指针
void* drv_userdata;//用于将来扩展
void* drv_extdata; //用于将来扩展
char_t* drv_name; //驱动程序的名字
}driver_t;
|
驱动程序实例化的时候会建立设备的数据结构
组织设备
我们使用设备表来组织驱动和设备
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#define DEVICE_MAX 34
typedef struct s_DEVTLST
{
uint_t dtl_type;//设备类型
uint_t dtl_nr;//设备计数
list_h_t dtl_list;//挂载设备device_t结构的链表
}devtlst_t;
typedef struct s_DEVTABLE
{
list_h_t devt_list; //设备表自身的链表
spinlock_t devt_lock; //设备表自旋锁
list_h_t devt_devlist; //全局设备链表
list_h_t devt_drvlist; //全局驱动程序链表,驱动程序不需要分类,一个链表就行
uint_t devt_devnr; //全局设备计数
uint_t devt_drvnr; //全局驱动程序计数
devtlst_t devt_devclsl[DEVICE_MAX]; //分类存放设备数据结构的devtlst_t结构数组
}devtable_t;
|
驱动程序功能
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
//驱动程序入口和退出函数
drvstus_t device_entry(driver_t* drvp,uint_t val,void* p);
drvstus_t device_exit(driver_t* drvp,uint_t val,void* p);
//设备中断处理函数
drvstus_t device_handle(uint_t ift_nr,void* devp,void* sframe);
//打开、关闭设备函数
drvstus_t device_open(device_t* devp,void* iopack);
drvstus_t device_close(device_t* devp,void* iopack);
//读、写设备数据函数
drvstus_t device_read(device_t* devp,void* iopack);
drvstus_t device_write(device_t* devp,void* iopack);
//调整读写设备数据位置函数
drvstus_t device_lseek(device_t* devp,void* iopack);
//控制设备函数
drvstus_t device_ioctrl(device_t* devp,void* iopack);
//开启、停止设备函数
drvstus_t device_dev_start(device_t* devp,void* iopack);
drvstus_t device_dev_stop(device_t* devp,void* iopack);
//设置设备电源函数
drvstus_t device_set_powerstus(device_t* devp,void* iopack);
//枚举设备函数
drvstus_t device_enum_dev(device_t* devp,void* iopack);
//刷新设备缓存函数
drvstus_t device_flush(device_t* devp,void* iopack);
//设备关机函数
drvstus_t device_shutdown(device_t* devp,void* iopack);
|
driver_t 结构体中 的 drv_dipfunc 函数指针数组存放了上述12个
驱动函数的指针
第二十九讲 如何注册设备
注册流程
电脑插入一个 USB 鼠标时,会有如下步骤
- 操作系统收到一个中断
- USB总线驱动的中断处理程序会执行
- 调用内核相关服务,查找 USB 鼠标对应的驱动程序
- 操作系统加载驱动程序
- 驱动程序执行,向内核注册一个鼠标设备
驱动程序表
加载驱动时,将驱动程序的入口函数加入驱动程序表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
//cosmos/kernel/krlglobal.c
KRL_DEFGLOB_VARIABLE(drventyexit_t,osdrvetytabl)[]={NULL};
void init_krldriver()
{
//遍历驱动程序表中的每个驱动程序入口函数
for (uint_t ei = 0; osdrvetytabl[ei] != NULL; ei++)
{ //运行一个驱动程序入口
if (krlrun_driverentry(osdrvetytabl[ei]) == DFCERRSTUS)
{
hal_sysdie("init driver err");
}
}
return;
}
void init_krl()
{
init_krlmm();
init_krldevice();
init_krldriver();
//……
return;
}
|
运行驱动程序
调用驱动程序入口函数
建立一个 driver_t结构实例,将其作为参数传入驱动程序入口函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
void init_krldriver()
{
//遍历驱动程序表中的每个驱动程序入口函数
for (uint_t ei = 0; osdrvetytabl[ei] != NULL; ei++)
{ //运行一个驱动程序入口
if (krlrun_driverentry(osdrvetytabl[ei]) == DFCERRSTUS)
{
hal_sysdie("init driver err");
}
}
return;
}
void init_krl()
{
init_krlmm();
init_krldevice();
init_krldriver();
//……
return;
}
|
挂载设备到驱动上
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
drvstus_t krldev_add_driver(device_t *devp, driver_t *drvp)
{
list_h_t *lst;
device_t *fdevp;
//遍历这个驱动上所有设备
list_for_each(lst, &drvp->drv_alldevlist)
{
fdevp = list_entry(lst, device_t, dev_indrvlst);
//比较设备ID有相同的则返回错误
if (krlcmp_devid(&devp->dev_id, &fdevp->dev_id) == TRUE)
{
return DFCERRSTUS;
}
}
//将设备挂载到驱动上
list_add(&devp->dev_indrvlst, &drvp->drv_alldevlist);
devp->dev_drv = drvp;//让设备中dev_drv字段指向管理自己的驱动
return DFCOKSTUS;
}
|
向内核注册设备
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
drvstus_t krlnew_device(device_t *devp)
{
device_t *findevp;
drvstus_t rets = DFCERRSTUS;
cpuflg_t cpufg;
list_h_t *lstp;
devtable_t *dtbp = &osdevtable;
uint_t devmty = devp->dev_id.dev_mtype;
if (devp->dev_drv == NULL)//没有驱动的设备不行
{
return DFCERRSTUS;
}
krlspinlock_cli(&dtbp->devt_lock, &cpufg);//加锁
//遍历设备类型链表上的所有设备
list_for_each(lstp, &dtbp->devt_devclsl[devmty].dtl_list)
{
findevp = list_entry(lstp, device_t, dev_intbllst);
//不能有设备ID相同的设备,如果有则出错
if (krlcmp_devid(&devp->dev_id, &findevp->dev_id) == TRUE)
{
rets = DFCERRSTUS;
goto return_step;
}
}
//先把设备加入设备表的全局设备链表
list_add(&devp->dev_intbllst, &dtbp->devt_devclsl[devmty].dtl_list);
//将设备加入对应设备类型的链表中
list_add(&devp->dev_list, &dtbp->devt_devlist);
dtbp->devt_devclsl[devmty].dtl_nr++;//设备计数加一
dtbp->devt_devnr++;//总的设备数加一
rets = DFCOKSTUS;
return_step:
krlspinunlock_sti(&dtbp->devt_lock, &cpufg);//解锁
return rets;
}
|
安装中断回调函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
//中断回调函数类型
typedef drvstus_t (*intflthandle_t)(uint_t ift_nr,void* device,void* sframe);
//安装中断回调函数接口
drvstus_t krlnew_devhandle(device_t *devp, intflthandle_t handle, uint_t phyiline)
{
//调用内核层中断框架接口函数
intserdsc_t *sdp = krladd_irqhandle(devp, handle, phyiline);
if (sdp == NULL)
{
return DFCERRSTUS;
}
cpuflg_t cpufg;
krlspinlock_cli(&devp->dev_lock, &cpufg);
//将中断服务描述符结构挂入这个设备结构中
list_add(&sdp->s_indevlst, &devp->dev_intserlst);
devp->dev_intlnenr++;
krlspinunlock_sti(&devp->dev_lock, &cpufg);
return DFCOKSTUS;
}
|
第三十讲 如何处理内核I/O
I/O 包
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
typedef struct s_OBJNODE
{
spinlock_t on_lock; //自旋锁
list_h_t on_list; //链表
sem_t on_complesem; //完成信号量
uint_t on_flgs; //标志
uint_t on_stus; //状态
sint_t on_opercode; //操作码
uint_t on_objtype; //对象类型
void* on_objadr; //对象地址
uint_t on_acsflgs; //访问设备、文件标志
uint_t on_acsstus; //访问设备、文件状态
uint_t on_currops; //对应于读写数据的当前位置
uint_t on_len; //对应于读写数据的长度
uint_t on_ioctrd; //IO控制码
buf_t on_buf; //对应于读写数据的缓冲区
uint_t on_bufcurops; //对应于读写数据的缓冲区的当前位置
size_t on_bufsz; //对应于读写数据的缓冲区的大小
uint_t on_count; //对应于对象节点的计数
void* on_safedsc; //对应于对象节点的安全描述符
void* on_fname; //对应于访问数据文件的名称
void* on_finode; //对应于访问数据文件的结点
void* on_extp; //用于扩展
}objnode_t;
## 创建和删除
```C
//建立objnode_t结构
objnode_t *krlnew_objnode()
{
objnode_t *ondp = (objnode_t *)krlnew((size_t)sizeof(objnode_t));//分配objnode_t结构的内存空间
if (ondp == NULL)
{
return NULL;
}
objnode_t_init(ondp);//初始化objnode_t结构
return ondp;
}
//删除objnode_t结构
bool_t krldel_objnode(objnode_t *onodep)
{
if (krldelete((adr_t)onodep, (size_t)sizeof(objnode_t)) == FALSE)//删除objnode_t结构的内存空间
{
hal_sysdie("krldel_objnode err");
return FALSE;
}
return TRUE;
}
|
发送 I/O 包
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
//发送设备IO
drvstus_t krldev_io(objnode_t *nodep)
{
//获取设备对象
device_t *devp = (device_t *)(nodep->on_objadr);
if ((nodep->on_objtype != OBJN_TY_DEV && nodep->on_objtype != OBJN_TY_FIL) || nodep->on_objadr == NULL)
{//检查操作对象类型是不是文件或者设备,对象地址是不是为空
return DFCERRSTUS;
}
if (nodep->on_opercode < 0 || nodep->on_opercode >= IOIF_CODE_MAX)
{//检查IO操作码是不是合乎要求
return DFCERRSTUS;
}
return krldev_call_driver(devp, nodep->on_opercode, 0, 0, NULL, nodep);//调用设备驱动
}
//调用设备驱动
drvstus_t krldev_call_driver(device_t *devp, uint_t iocode, uint_t val1, uint_t val2, void *p1, void *p2)
{
driver_t *drvp = NULL;
if (devp == NULL || iocode >= IOIF_CODE_MAX)
{//检查设备和IO操作码
return DFCERRSTUS;
}
drvp = devp->dev_drv;
if (drvp == NULL)//检查设备是否有驱动程序
{
return DFCERRSTUS;
}
//用IO操作码为索引调用驱动程序功能分派函数数组中的函数
return drvp->drv_dipfun[iocode](devp, p2);
}
|
实现systick设备驱动
systick 设备的主要功能是每各1ms产生一个中断,更新当前进程的运行时间
1
2
3
4
5
|
drvstus_t systick_handle(uint_t ift_nr, void *devp, void *sframe)
{
krlthd_inc_tick(krlsched_retn_currthread());//更新当前进程的tick
return DFCOKSTUS;
}
|
第三十一讲 Linux如何获取所有设备信息
Linux的设备信息
可以在 /sys/bus 目录下查看总线下所有设备
第三十二讲 如何组织文件
文件系统
文件系统设计
因为文件系统有各种格式,所以文件系统组件应该和内核分开,且可以动态加载和删除不同的文件系统组件
文件格式和存储块
逻辑上文件就是一个可以动态增减的线性字节数组,而存储设备都是以块为单位存储数据的,
不同的存储设的存储卡大小不同,我们先将字节数组整合成文件数据逻辑块,然后将这个逻辑块映射到
一个或多个物理储存块
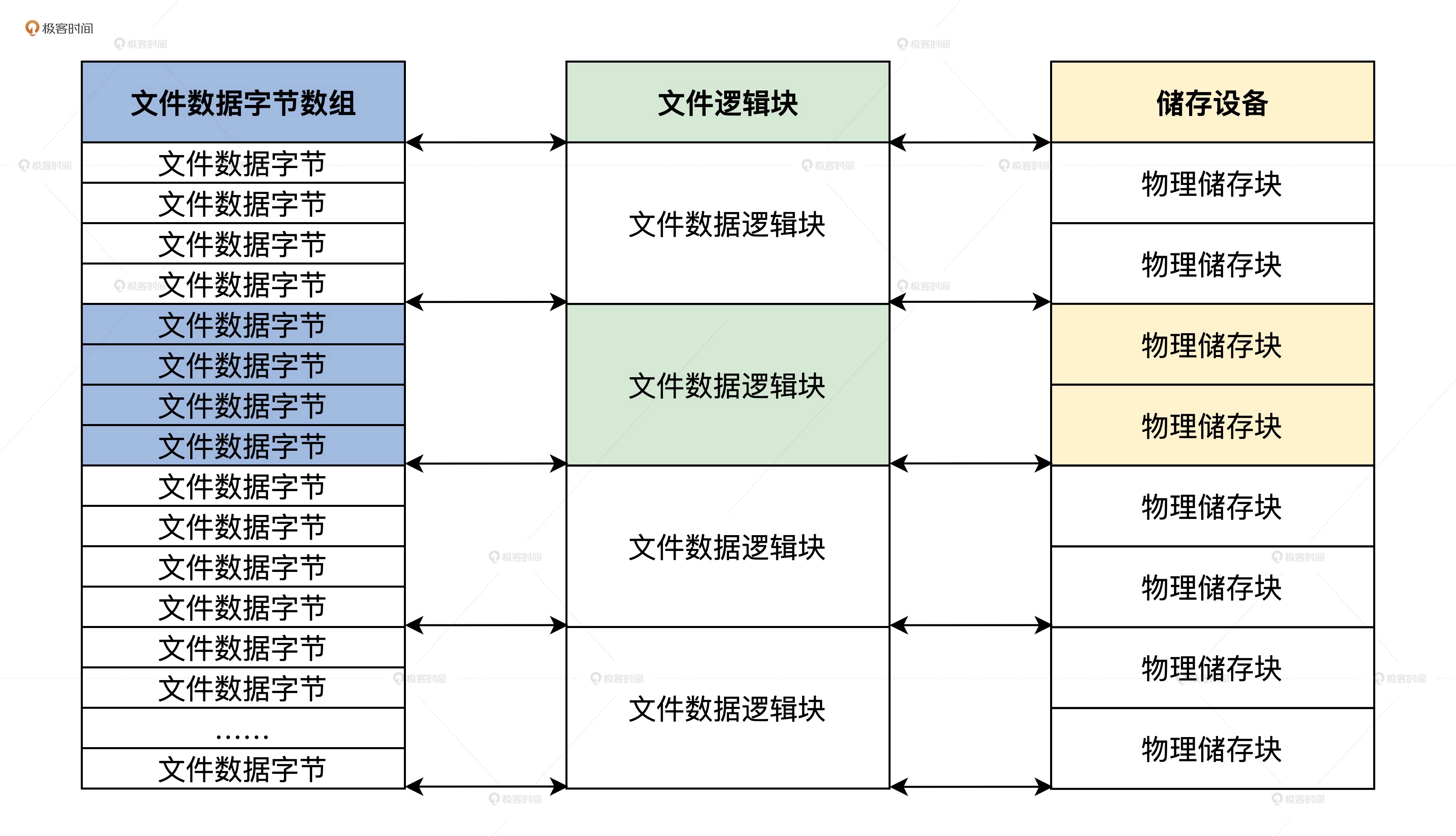
组织文件
整个文件层次结构就像一个倒挂的树
文件系统数据结构
超级块
包含文件系统标识、版本信息、逻辑存储块大小等新的数据结构叫做文件系统的
超级块或描述块
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
typedef struct s_RFSSUBLK
{
spinlock_t rsb_lock;//超级块在内存中使用的自旋锁
uint_t rsb_mgic;//文件系统标识
uint_t rsb_vec;//文件系统版本
uint_t rsb_flg;//标志
uint_t rsb_stus;//状态
size_t rsb_sz;//该数据结构本身的大小
size_t rsb_sblksz;//超级块大小
size_t rsb_dblksz;//文件系统逻辑储存块大小,我们这里用的是4KB
uint_t rsb_bmpbks;//位图的开始逻辑储存块
uint_t rsb_bmpbknr;//位图占用多少个逻辑储存块
uint_t rsb_fsysallblk;//文件系统有多少个逻辑储存块
rfsdir_t rsb_rootdir;//根目录,后面会看到这个数据结构的
}rfssublk_t;
|
超级块存储在设备的第一个逻辑存储块中
位图
我们使用位图来表示逻辑存储块的分配状态,如果某个位的值是0,那么对应的逻辑块是空闲的。
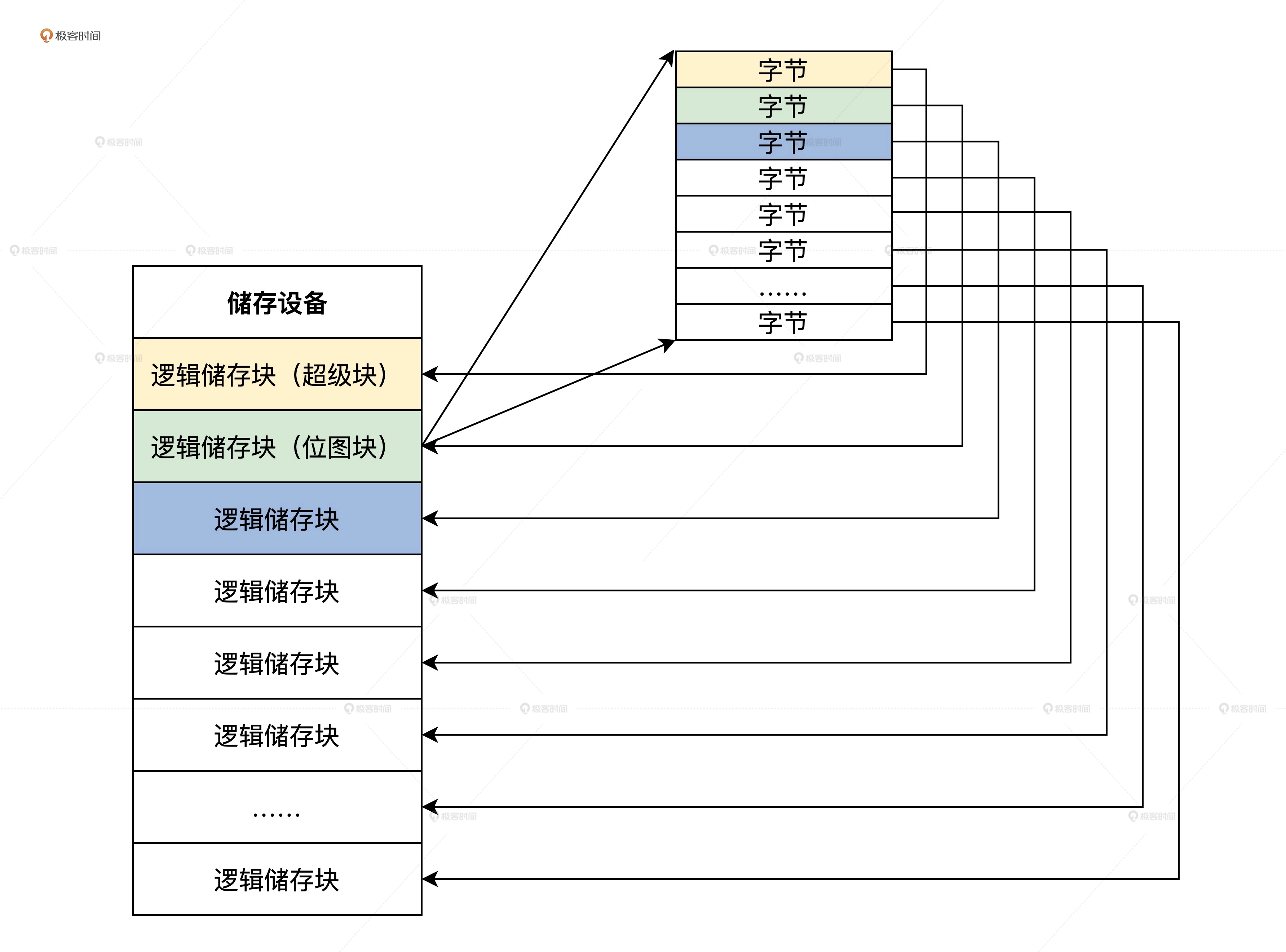
位图并不需要实际的数据结构,将位图块当做一个字节数组就可以
目录
目录也是一种数据,也包含了目录类型、状态、指向文件数据管理头的块号、名称等信息
1
2
3
4
5
6
7
8
9
10
11
12
|
#define DR_NM_MAX (128-(sizeof(uint_t)*3))
#define RDR_NUL_TYPE 0
#define RDR_DIR_TYPE 1
#define RDR_FIL_TYPE 2
#define RDR_DEL_TYPE 5
typedef struct s_RFSDIR
{
uint_t rdr_stus;//目录状态
uint_t rdr_type;//目录类型,可以是空类型、目录类型、文件类型、已删除的类型
uint_t rdr_blknr;//指向文件数据管理头的块号,不像内存可以用指针,只能按块访问
char_t rdr_name[DR_NM_MAX];//名称数组,大小为DR_NM_MAX
}rfsdir_t;
|
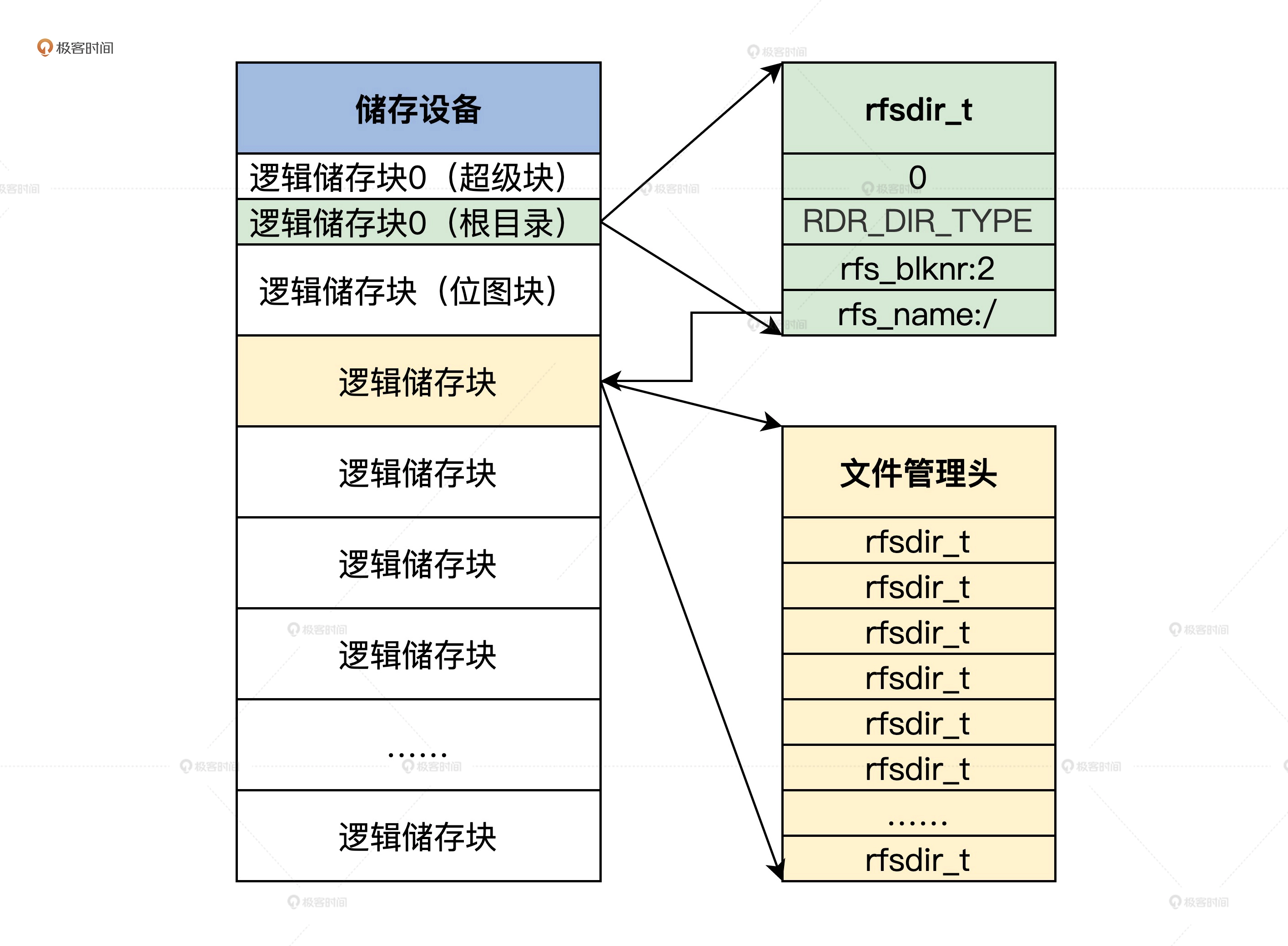
文件管理头
文件管理头记录了文件信息,如类型、创建时间、大小、占用哪些逻辑存储块等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
#define FBLKS_MAX 32
#define FMD_NUL_TYPE 0
#define FMD_DIR_TYPE 1
#define FMD_FIL_TYPE 2
#define FMD_DEL_TYPE 5//文件管理头也需要表明它管理的是目录文件还是普通文件
typedef struct s_FILBLKS
{
uint_t fb_blkstart;//开始的逻辑储存块号
uint_t fb_blknr;//逻辑储存块的块数,从blkstart开始的连续块数
}filblks_t;
typedef struct s_fimgrhd
{
uint_t fmd_stus;//文件状态
uint_t fmd_type;//文件类型:可以是目录文件、普通文件、空文件、已删除的文件
uint_t fmd_flg;//文件标志
uint_t fmd_sfblk;//文件管理头自身所在的逻辑储存块
uint_t fmd_acss;//文件访问权限
uint_t fmd_newtime;//文件的创建时间,换算成秒
uint_t fmd_acstime;//文件的访问时间,换算成秒
uint_t fmd_fileallbk;//文件一共占用多少个逻辑储存块
uint_t fmd_filesz;//文件大小
uint_t fmd_fileifstbkoff;//文件数据在第一块逻辑储存块中的偏移
uint_t fmd_fileiendbkoff;//文件数据在最后一块逻辑储存块中的偏移
uint_t fmd_curfwritebk;//文件数据当前将要写入的逻辑储存块
uint_t fmd_curfinwbkoff;//文件数据当前将要写入的逻辑储存块中的偏移
filblks_t fmd_fleblk[FBLKS_MAX];//文件占用逻辑储存块的数组,一共32个filblks_t结构
uint_t fmd_linkpblk;//指向文件的上一个文件管理头的逻辑储存块
uint_t fmd_linknblk;//指向文件的下一个文件管理头的逻辑储存块
}fimgrhd_t;
|
fmd_fleblk 数据存放的是逻辑块占用信息,比如一个文件占用 4~8、10~15、30~40 的逻辑存储块时,那么
fmd_fleblk[0] 保存 4 和 4,fmd_fleblk[1] 保存 10 和 5,fmd_fleblk[2] 保存 30 和 10 。
如果文件比较大,使用 fmd_linkpblk 和 fmd_linknblk 来扩展
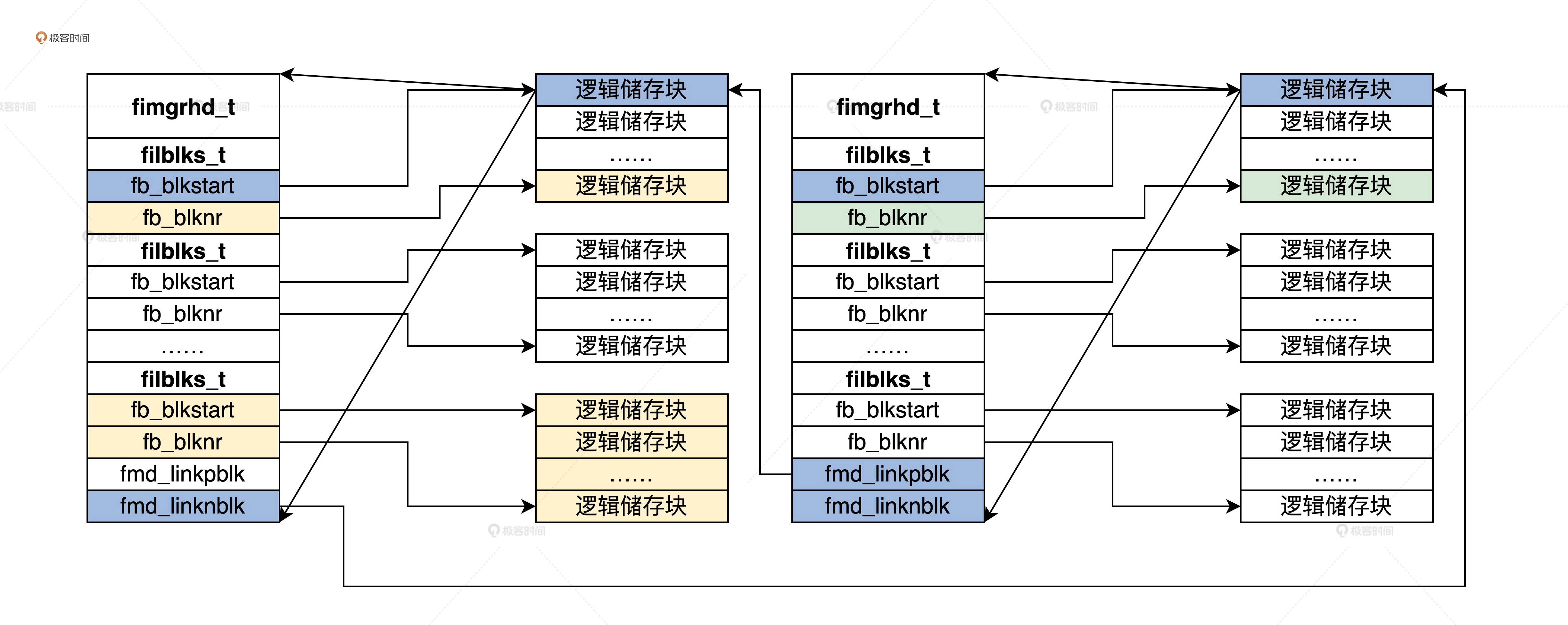
第三十三讲 文件系统格式化
文件系统设备
文件系统是 一个设备,需要编写相应的驱动程序
建立超级块
建立超级块就是初始化超级块的数据结构,然后写入存储设备的第一块逻辑存储块
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
void *new_buf(size_t bufsz)
{
return (void *)krlnew(bufsz);//分配缓冲区
}
void del_buf(void *buf, size_t bufsz)
{
krldelete((adr_t)buf, bufsz)//释放缓冲区
return;
}
void rfssublk_t_init(rfssublk_t* initp)
{
krlspinlock_init(&initp->rsb_lock);
initp->rsb_mgic = 0x142422;//标志就是一个数字而已,无其它意义
initp->rsb_vec = 1;//文件系统版本为1
initp->rsb_flg = 0;
initp->rsb_stus = 0;
initp->rsb_sz = sizeof(rfssublk_t);//超级块本身的大小
initp->rsb_sblksz = 1;//超级块占用多少个逻辑储存块
initp->rsb_dblksz = FSYS_ALCBLKSZ;//逻辑储存块的大小为4KB
//位图块从第1个逻辑储存块开始,超级块占用第0个逻辑储存块
initp->rsb_bmpbks = 1;
initp->rsb_bmpbknr = 0;
initp->rsb_fsysallblk = 0;
rfsdir_t_init(&initp->rsb_rootdir);//初始化根目录
return;
}
bool_t create_superblk(device_t *devp)
{
void *buf = new_buf(FSYS_ALCBLKSZ);//分配4KB大小的缓冲区,清零
hal_memset(buf, 0, FSYS_ALCBLKSZ);
//使rfssublk_t结构的指针指向缓冲区并进行初始化
rfssublk_t *sbp = (rfssublk_t *)buf;
rfssublk_t_init(sbp);
//获取储存设备的逻辑储存块数并保存到超级块中
sbp->rsb_fsysallblk = ret_rfsdevmaxblknr(devp);
//把缓冲区中超级块的数据写入到储存设备的第0个逻辑储存块中
if (write_rfsdevblk(devp, buf, 0) == DFCERRSTUS)
{
return FALSE;
}
del_buf(buf, FSYS_ALCBLKSZ);//释放缓冲区
return TRUE;
}
|
建立位图
我们使用一个逻辑存储块作为位图块记录所有存储块的状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
//把逻辑储存块中的数据,读取到4KB大小的缓冲区中
drvstus_t read_rfsdevblk(device_t* devp,void* rdadr,uint_t blknr)
{
//获取逻辑储存块地址
void* p=ret_rfsdevblk(devp,blknr);
//把逻辑储存块中的数据复制到缓冲区中
hal_memcpy(p,rdadr,FSYS_ALCBLKSZ);
return DFCOKSTUS;
}
//获取超级块
rfssublk_t* get_superblk(device_t* devp)
{
//分配4KB大小的缓冲区
void* buf=new_buf(FSYS_ALCBLKSZ);
//清零缓冲区
hal_memset(buf,FSYS_ALCBLKSZ,0);
//读取第0个逻辑储存块中的数据到缓冲区中,如果读取失败则释放缓冲区
read_rfsdevblk(devp,buf,0);
//返回超级块数据结构的地址,即缓冲区的首地址
return (rfssublk_t*)buf;
}
//释放超级块
void del_superblk(device_t* devp,rfssublk_t* sbp)
{
//回写超级块,因为超级块中的数据可能已经发生了改变,如果出错则死机
write_rfsdevblk(devp,(void*)sbp,0);//释放先前分配的4KB大小的缓冲区
del_buf((void*)sbp,FSYS_ALCBLKSZ);
return;
}
//建立位图
bool_t create_bitmap(device_t* devp)
{
bool_t rets=FALSE;
//获取超级块,失败则返回FALSE
rfssublk_t* sbp = get_superblk(devp);
//分配4KB大小的缓冲区
void* buf = new_buf(FSYS_ALCBLKSZ);
//获取超级块中位图块的开始块号
uint_t bitmapblk=sbp->rsb_bmpbks;
//获取超级块中储存介质的逻辑储存块总数
uint_t devmaxblk=sbp->rsb_fsysallblk;
//如果逻辑储存块总数大于4096,就认为出错了
if(devmaxblk>FSYS_ALCBLKSZ)
{
rets=FALSE;
goto errlable;
}
//把缓冲区中每个字节都置成1
hal_memset(buf,FSYS_ALCBLKSZ,1);
u8_t* bitmap=(u8_t*)buf;
//把缓冲区中的第3个字节到第devmaxblk个字节都置成0
//前面两个字节分别代表超级块和位图块
for(uint_t bi=2;bi<devmaxblk;bi++)
{
bitmap[bi]=0;
}
//把缓冲区中的数据写入到储存介质中的第bitmapblk个逻辑储存块中,即位图块中
if(write_rfsdevblk(devp,buf,bitmapblk)==DFCERRSTUS){
rets = FALSE;
goto errlable;
}
//设置返回状态
rets=TRUE;
errlable:
//释放超级块
del_superblk(devp,sbp);
//释放缓冲区
del_buf(buf,FSYS_ALCBLKSZ);
return rets;
}
|
建立根目录
一切目录和文件都是存放在根目录下。
根目录也是一种文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
//分配新的空闲逻辑储存块
uint_t rfs_new_blk(device_t* devp)
{
uint_t retblk=0;
//获取位图块
u8_t* bitmap = get_bitmapblk(devp);
if(bitmap == NULL)
{
return 0;
}
for(uint_t blknr = 2; blknr < FSYS_ALCBLKSZ; blknr++)
{
//找到一个为0的字节就置为1,并返回该字节对应的空闲块号
if(bitmap[blknr] == 0)
{
bitmap[blknr] = 1;
retblk = blknr;
goto retl;
}
}
//如果到这里就说明没有空闲块了,所以返回0
retblk=0;
retl:
//释放位图块
del_bitmapblk(devp,bitmap);
return retblk;
}
//建立根目录
bool_t create_rootdir(device_t* devp)
{
bool_t rets = FALSE;
//获取超级块
rfssublk_t* sbp = get_superblk(devp);
//分配4KB大小的缓冲区
void* buf = new_buf(FSYS_ALCBLKSZ);
//缓冲区清零
hal_memset(buf,FSYS_ALCBLKSZ,0);
//分配一个空闲的逻辑储存块
uint_t blk = rfs_new_blk(devp);
if(blk == 0) {
rets = FALSE;
goto errlable;
}
//设置超级块中的rfsdir_t结构中的名称为“/”
sbp->rsb_rootdir.rdr_name[0] = '/';
//设置超级块中的rfsdir_t结构中的类型为目录类型
sbp->rsb_rootdir.rdr_type = RDR_DIR_TYPE;
//设置超级块中的rfsdir_t结构中的块号为新分配的空闲逻辑储存块的块号
sbp->rsb_rootdir.rdr_blknr = blk;
fimgrhd_t* fmp = (fimgrhd_t*)buf;
//初始化fimgrhd_t结构
fimgrhd_t_init(fmp);
//因为这是目录文件所以fimgrhd_t结构的类型设置为目录类型
fmp->fmd_type = FMD_DIR_TYPE;
//fimgrhd_t结构自身所在的块设置为新分配的空闲逻辑储存块
fmp->fmd_sfblk = blk;
//fimgrhd_t结构中正在写入的块设置为新分配的空闲逻辑储存块
fmp->fmd_curfwritebk = blk;
//fimgrhd_t结构中正在写入的块的偏移设置为512字节
fmp->fmd_curfinwbkoff = 0x200;
//设置文件数据占有块数组的第0个元素
fmp->fmd_fleblk[0].fb_blkstart = blk;
fmp->fmd_fleblk[0].fb_blknr = 1;
//把缓冲区中的数据写入到新分配的空闲逻辑储存块中,其中包含已经设置好的 fimgrhd_t结构
if(write_rfsdevblk(devp, buf, blk) == DFCERRSTUS) {
rets = FALSE;
goto errlable;
}
rets = TRUE;
errlable:
//释放缓冲区
del_buf(buf, FSYS_ALCBLKSZ);
errlable1:
//释放超级块
del_superblk(devp, sbp);
return rets;
}
|
第三十四讲 实现文件的六大基本操作
辅助操作
文件操作需要大量辅助函数
操作根目录文件
在我们的文件系统中,一个文件的 rfsdir_t 结构存储在根目录文件中,所欲
首先需要获取和释放根目录文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
//获取根目录文件
void* get_rootdirfile_blk(device_t* devp)
{
void* retptr = NULL;
rfsdir_t* rtdir = get_rootdir(devp);//获取根目录文件的rfsdir_t结构
//分配4KB大小的缓冲区并清零
void* buf = new_buf(FSYS_ALCBLKSZ);
hal_memset(buf, FSYS_ALCBLKSZ, 0);
//读取根目录文件的逻辑储存块到缓冲区中
read_rfsdevblk(devp, buf, rtdir->rdr_blknr)
retptr = buf;//设置缓冲区的首地址为返回值
goto errl1;
errl:
del_buf(buf, FSYS_ALCBLKSZ);
errl1:
del_rootdir(devp, rtdir);//释放根目录文件的rfsdir_t结构
return retptr;
}
//释放根目录文件
void del_rootdirfile_blk(device_t* devp,void* blkp)
{
//因为逻辑储存块的头512字节的空间中,保存的就是fimgrhd_t结构
fimgrhd_t* fmp = (fimgrhd_t*)blkp;
//把根目录文件回写到储存设备中去,块号为fimgrhd_t结构自身所在的块号
write_rfsdevblk(devp, blkp, fmp->fmd_sfblk)
//释放缓冲区
del_buf(blkp, FSYS_ALCBLKSZ);
return;
}
|
获取文件名
简单起见,我们以 “/xxx” 格式举例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
//检查文件路径名
sint_t rfs_chkfilepath(char_t* fname)
{
char_t* chp = fname;
//检查文件路径名的第一个字符是否为“/”,不是则返回2
if(chp[0] != '/') { return 2; }
for(uint_t i = 1; ; i++)
{
//检查除第1个字符外其它字符中还有没有为“/”的,有就返回3
if(chp[i] == '/') { return 3; }
//如果这里i大于等于文件名称的最大长度,就返回4
if(i >= DR_NM_MAX) { return 4; }
//到文件路径字符串的末尾就跳出循环
if(chp[i] == 0 && i > 1) { break; }
}
//返回0表示正确
return 0;
}
//提取纯文件名
sint_t rfs_ret_fname(char_t* buf,char_t* fpath)
{
//检查文件路径名是不是“/xxxx”的形式
sint_t stus = rfs_chkfilepath(fpath);
//如果不为0就直接返回这个状态值表示错误
if(stus != 0) { return stus; }
//从路径名字符串的第2个字符开始复制字符到buf中
rfs_strcpy(&fpath[1], buf);
return 0;
}
|
判断文件是否存在
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
sint_t rfs_chkfileisindev(device_t* devp,char_t* fname)
{
sint_t rets = 6;
sint_t ch = rfs_strlen(fname);//获取文件名的长度,注意不是文件路径名
//检查文件名的长度是不是合乎要求
if(ch < 1 || ch >= (sint_t)DR_NM_MAX) { return 4; }
void* rdblkp = get_rootdirfile_blk(devp);
fimgrhd_t* fmp = (fimgrhd_t*)rdblkp;
//检查该fimgrhd_t结构的类型是不是FMD_DIR_TYPE,即这个文件是不是目录文件
if(fmp->fmd_type != FMD_DIR_TYPE) { rets = 3; goto err; }
//检查根目录文件是不是为空,即没有写入任何数据,所以返回0,表示根目录下没有对应的文件
if(fmp->fmd_curfwritebk == fmp->fmd_fleblk[0].fb_blkstart &&
fmp->fmd_curfinwbkoff == fmp->fmd_fileifstbkoff) {
rets = 0; goto err;
}
rfsdir_t* dirp = (rfsdir_t*)((uint_t)(fmp) + fmp->fmd_fileifstbkoff);//指向根目录文件的第一个字节
//指向根目录文件的结束地址
void* maxchkp = (void*)((uint_t)rdblkp + FSYS_ALCBLKSZ - 1);
//当前的rfsdir_t结构的指针比根目录文件的结束地址小,就继续循环
for(;(void*)dirp < maxchkp;) {
//如果这个rfsdir_t结构的类型是RDR_FIL_TYPE,说明它对应的是文件而不是目录,所以下面就继续比较其文件名
if(dirp->rdr_type == RDR_FIL_TYPE) {
if(rfs_strcmp(dirp->rdr_name,fname) == 1) {//比较其文件名
rets = 1; goto err;
}
}
dirp++;
}
rets = 0; //到了这里说明没有找到相同的文件
err:
del_rootdirfile_blk(devp,rdblkp);//释放根目录文件
return rets;
}
|
文件相关操作
新建文件
新建文件分成4步:
- 提取纯文件名,检查文件是否已存在
- 分配一个空间的逻辑存储块,并在根目录末尾写入这个文件对应的 rfsdir_t 结构
- 在一个新的 4KB 的缓冲区初始化文件对应的 fimgrhd_t 结构
- 把第 3 步对应的缓冲区数据写入到第 2 步分配的空间逻辑块中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
//新建文件的接口函数
drvstus_t rfs_new_file(device_t* devp, char_t* fname, uint_t flg)
{
//在栈中分配一个字符缓冲区并清零
char_t fne[DR_NM_MAX];
hal_memset((void*)fne, DR_NM_MAX, 0);
//从文件路径名中提取出纯文件名
if(rfs_ret_fname(fne, fname) != 0) { return DFCERRSTUS; }
//检查储存介质上是否已经存在这个新建的文件,如果是则返回错误
if(rfs_chkfileisindev(devp, fne) != 0) {return DFCERRSTUS; }
//调用实际建立文件的函数
return rfs_new_dirfileblk(devp, fne, RDR_FIL_TYPE, 0);
}
drvstus_t rfs_new_dirfileblk(device_t* devp,char_t* fname,uint_t flgtype,uint_t val)
{
drvstus_t rets = DFCERRSTUS;
void* buf = new_buf(FSYS_ALCBLKSZ);//分配一个4KB大小的缓冲区
hal_memset(buf, FSYS_ALCBLKSZ, 0);//清零该缓冲区
uint_t fblk = rfs_new_blk(devp);//分配一个新的空闲逻辑储存块
void* rdirblk = get_rootdirfile_blk(devp);//获取根目录文件
fimgrhd_t* fmp = (fimgrhd_t*)rdirblk;
//指向文件当前的写入地址,因为根目录文件已经被读取到内存中了
rfsdir_t* wrdirp = (rfsdir_t*)((uint_t)rdirblk + fmp->fmd_curfinwbkoff);
//对文件当前的写入地址进行检查
if(((uint_t)wrdirp) >= ((uint_t)rdirblk + FSYS_ALCBLKSZ)) {
rets=DFCERRSTUS; goto err;
}
wrdirp->rdr_stus = 0;
wrdirp->rdr_type = flgtype;//设为文件类型
wrdirp->rdr_blknr = fblk;//设为刚刚分配的空闲逻辑储存块
rfs_strcpy(fname, wrdirp->rdr_name);//把文件名复制到rfsdir_t结构
fmp->fmd_filesz += (uint_t)(sizeof(rfsdir_t));//增加根目录文件的大小
//增加根目录文件当前的写入地址,保证下次不被覆盖
fmp->fmd_curfinwbkoff += (uint_t)(sizeof(rfsdir_t));
fimgrhd_t* ffmp = (fimgrhd_t*)buf;//指向新分配的缓冲区
fimgrhd_t_init(ffmp);//调用fimgrhd_t结构默认的初始化函数
ffmp->fmd_type = FMD_FIL_TYPE;//因为建立的是文件,所以设为文件类型
ffmp->fmd_sfblk = fblk;//把自身所在的块,设为分配的逻辑储存块
ffmp->fmd_curfwritebk = fblk;//把当前写入的块,设为分配的逻辑储存块
ffmp->fmd_curfinwbkoff = 0x200;//把当前写入块的写入偏移量设为512
//把文件储存块数组的第1个元素的开始块,设为刚刚分配的空闲逻辑储存块
ffmp->fmd_fleblk[0].fb_blkstart = fblk;
//因为只分配了一个逻辑储存块,所以设为1
ffmp->fmd_fleblk[0].fb_blknr = 1;
//把缓冲区中的数据写入到刚刚分配的空闲逻辑储存块中
if(write_rfsdevblk(devp, buf, fblk) == DFCERRSTUS) {
rets = DFCERRSTUS; goto err;
}
rets = DFCOKSTUS;
err:
del_rootdirfile_blk(devp, rdirblk);//释放根目录文件
err1:
del_buf(buf, FSYS_ALCBLKSZ);//释放缓冲区
return rets;
}
|
删除文件
删除文件分成4步:
- 提取纯文件名
- 获取根目录文件,在根目录文件中查找待删除文件的 rfsdir_t 结构,然后释放该文件占用的逻辑存储块
- 将 rfsdir_t结构的类型设置为 RDR_DEL_TYPE
- 释放根目录文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
//文件删除的接口函数
drvstus_t rfs_del_file(device_t* devp, char_t* fname, uint_t flg)
{
if(flg != 0) {
return DFCERRSTUS;
}
return rfs_del_dirfileblk(devp, fname, RDR_FIL_TYPE, 0);
}
drvstus_t rfs_del_dirfileblk(device_t* devp, char_t* fname, uint_t flgtype, uint_t val)
{
if(flgtype != RDR_FIL_TYPE || val != 0) { return DFCERRSTUS; }
char_t fne[DR_NM_MAX];
hal_memset((void*)fne, DR_NM_MAX, 0);
//提取纯文件名
if(rfs_ret_fname(fne,fname) != 0) { return DFCERRSTUS; }
//调用删除文件的核心函数
if(del_dirfileblk_core(devp, fne) != 0) { return DFCERRSTUS; }
return DFCOKSTUS;
}
//删除文件的核心函数
sint_t del_dirfileblk_core(device_t* devp, char_t* fname)
{
sint_t rets = 6;
void* rblkp=get_rootdirfile_blk(devp);//获取根目录文件
fimgrhd_t* fmp = (fimgrhd_t*)rblkp;
if(fmp->fmd_type!=FMD_DIR_TYPE) { //检查根目录文件的类型
rets=4; goto err;
}
if(fmp->fmd_curfwritebk == fmp->fmd_fleblk[0].fb_blkstart && fmp->fmd_curfinwbkoff == fmp->fmd_fileifstbkoff) { //检查根目录文件中有没有数据
rets = 3; goto err;
}
rfsdir_t* dirp = (rfsdir_t*)((uint_t)(fmp) + fmp->fmd_fileifstbkoff);
void* maxchkp = (void*)((uint_t)rblkp + FSYS_ALCBLKSZ-1);
for(;(void*)dirp < maxchkp;) {
if(dirp->rdr_type == RDR_FIL_TYPE) {//检查其类型是否为文件类型
//如果文件名相同,就执行以下删除动作
if(rfs_strcmp(dirp->rdr_name, fname) == 1) {
//释放rfsdir_t结构的rdr_blknr中指向的逻辑储存块
rfs_del_blk(devp, dirp->rdr_blknr);
//初始化rfsdir_t结构,实际上是清除其中的数据
rfsdir_t_init(dirp);
//设置rfsdir_t结构的类型为删除类型,表示它已经删除
dirp->rdr_type = RDR_DEL_TYPE;
rets = 0; goto err;
}
}
dirp++;//下一个rfsdir_t
}
rets=1;
err:
del_rootdirfile_blk(devp,rblkp);//释放根目录文件
return rets;
}
|
打开文件
打开的文件会记录到 objnode_t 结构中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#define OBJN_TY_DEV 1//设备类型
#define OBJN_TY_FIL 2//文件类型
#define OBJN_TY_NUL 0//默认类型
typedef struct s_OBJNODE
{
spinlock_t on_lock;
list_h_t on_list;
sem_t on_complesem;
uint_t on_flgs;
uint_t on_stus;
//……
void* on_fname;//文件路径名指针
void* on_finode;//文件对应的fimgrhd_t结构指针
void* on_extp;//扩展所用
}objnode_t;
|
打开文件分成4步:
- 从 objnode_t 结构的文件路径中提取纯文件名
- 获取根目录文件,在根目录文件中查找对应的 rfsdir_t 结构, 看文件是否存在
- 分配一个 4KB 缓存区,把该文件对应的 rfsdir_t 结构中指向的逻辑存储块读取到缓存区
- 把缓存区中的 fimgrhd_t 结构的地址保存到 objnode_t 结构的 on_finode 属性中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
//打开文件的接口函数
drvstus_t rfs_open_file(device_t* devp, void* iopack)
{
objnode_t* obp = (objnode_t*)iopack;
//检查objnode_t中的文件路径名
if(obp->on_fname == NULL) {
return DFCERRSTUS;
}
//调用打开文件的核心函数
void* fmdp = rfs_openfileblk(devp, (char_t*)obp->on_fname);
if(fmdp == NULL) {
return DFCERRSTUS;
}
//把返回的fimgrhd_t结构的地址保存到objnode_t中的on_finode字段中
obp->on_finode = fmdp;
return DFCOKSTUS;
}
//打开文件的核心函数
void* rfs_openfileblk(device_t *devp, char_t* fname)
{
char_t fne[DR_NM_MAX]; void* rets = NULL,*buf = NULL;
hal_memset((void*)fne,DR_NM_MAX,0);
if(rfs_ret_fname(fne, fname) != 0) {//从文件路径名中提取纯文件名
return NULL;
}
void* rblkp = get_rootdirfile_blk(devp); //获取根目录文件
fimgrhd_t* fmp = (fimgrhd_t*)rblkp;
if(fmp->fmd_type != FMD_DIR_TYPE) {//判断根目录文件的类型是否合理
rets = NULL; goto err;
}
//判断根目录文件里有没有数据
if(fmp->fmd_curfwritebk == fmp->fmd_fleblk[0].fb_blkstart &&
fmp->fmd_curfinwbkoff == fmp->fmd_fileifstbkoff) {
rets = NULL; goto err;
}
rfsdir_t* dirp = (rfsdir_t*)((uint_t)(fmp) + fmp->fmd_fileifstbkoff);
void* maxchkp = (void*)((uint_t)rblkp + FSYS_ALCBLKSZ - 1);
for(;(void*)dirp < maxchkp;) {//开始遍历文件对应的rfsdir_t结构
if(dirp->rdr_type == RDR_FIL_TYPE) {
//如果文件名相同就跳转到opfblk标号处运行
if(rfs_strcmp(dirp->rdr_name, fne) == 1) {
goto opfblk;
}
}
dirp++;
}
//如果到这里说明没有找到该文件对应的rfsdir_t结构,所以设置返回值为NULL
rets = NULL; goto err;
opfblk:
buf = new_buf(FSYS_ALCBLKSZ);//分配4KB大小的缓冲区
//读取该文件占用的逻辑储存块
if(read_rfsdevblk(devp, buf, dirp->rdr_blknr) == DFCERRSTUS) {
rets = NULL; goto err1;
}
fimgrhd_t* ffmp = (fimgrhd_t*)buf;
if(ffmp->fmd_type == FMD_NUL_TYPE || ffmp->fmd_fileifstbkoff != 0x200) {//判断将要打开的文件是否合法
rets = NULL; goto err1;
}
rets = buf; goto err;//设置缓冲区首地址为返回值
err1:
del_buf(buf, FSYS_ALCBLKSZ); //上面的步骤若出现问题就要释放缓冲区
err:
del_rootdirfile_blk(devp, rblkp); //释放根目录文件
return rets;
}
|
读写文件
读文件的大致流程如下 :
- 检查 objnode_t 结构中用于存放文件数据的缓冲区及其大小
- 检查 imgrhd_t 结构中文件相关信息
- 把文件的数据读取到 objnode_t 结构中指向的缓冲区中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
//读取文件数据的接口函数
drvstus_t rfs_read_file(device_t* devp,void* iopack)
{
objnode_t* obp = (objnode_t*)iopack;
//检查文件是否已经打开,以及用于存放文件数据的缓冲区和它的大小是否合理
if(obp->on_finode == NULL || obp->on_buf == NULL || obp->on_bufsz != FSYS_ALCBLKSZ) {
return DFCERRSTUS;
}
return rfs_readfileblk(devp, (fimgrhd_t*)obp->on_finode, obp->on_buf, obp->on_len);
}
//实际读取文件数据的函数
drvstus_t rfs_readfileblk(device_t* devp, fimgrhd_t* fmp, void* buf, uint_t len)
{
//检查文件的相关信息是否合理
if(fmp->fmd_sfblk != fmp->fmd_curfwritebk || fmp->fmd_curfwritebk != fmp->fmd_fleblk[0].fb_blkstart) {
return DFCERRSTUS;
}
//检查读取文件数据的长度是否大于(4096-512)
if(len > (FSYS_ALCBLKSZ - fmp->fmd_fileifstbkoff)) {
return DFCERRSTUS;
}
//指向文件数据的开始地址
void* wrp = (void*)((uint_t)fmp + fmp->fmd_fileifstbkoff);
//把文件开始处的数据复制len个字节到buf指向的缓冲区中
hal_memcpy(wrp, buf, len);
return DFCOKSTUS;
}
|
写文件逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
//写入文件数据的接口函数
drvstus_t rfs_write_file(device_t* devp, void* iopack)
{
objnode_t* obp = (objnode_t*)iopack;
//检查文件是否已经打开,以及用于存放文件数据的缓冲区和它的大小是否合理
if(obp->on_finode == NULL || obp->on_buf == NULL || obp->on_bufsz != FSYS_ALCBLKSZ) {
return DFCERRSTUS;
}
return rfs_writefileblk(devp, (fimgrhd_t*)obp->on_finode, obp->on_buf, obp->on_len);
}
//实际写入文件数据的函数
drvstus_t rfs_writefileblk(device_t* devp, fimgrhd_t* fmp, void* buf, uint_t len)
{
//检查文件的相关信息是否合理
if(fmp->fmd_sfblk != fmp->fmd_curfwritebk || fmp->fmd_curfwritebk != fmp->fmd_fleblk[0].fb_blkstart) {
return DFCERRSTUS;
}
//检查当前将要写入数据的偏移量加上写入数据的长度,是否大于等于4KB
if((fmp->fmd_curfinwbkoff + len) >= FSYS_ALCBLKSZ) {
return DFCERRSTUS;
}
//指向将要写入数据的内存空间
void* wrp = (void*)((uint_t)fmp + fmp->fmd_curfinwbkoff);
//把buf缓冲区中的数据复制len个字节到wrp指向的内存空间中去
hal_memcpy(buf, wrp, len);
fmp->fmd_filesz += len;//增加文件大小
//使fmd_curfinwbkoff指向下一次将要写入数据的位置
fmp->fmd_curfinwbkoff += len;
//把文件数据写入到相应的逻辑储存块中,完成数据同步
write_rfsdevblk(devp, (void*)fmp, fmp->fmd_curfwritebk);
return DFCOKSTUS;
}
|
关闭文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
//关闭文件的接口函数
drvstus_t rfs_close_file(device_t* devp, void* iopack)
{
objnode_t* obp = (objnode_t*)iopack;
//检查文件是否已经打开了
if(obp->on_finode == NULL) {
return DFCERRSTUS;
}
return rfs_closefileblk(devp, obp->on_finode);
}
//关闭文件的核心函数
drvstus_t rfs_closefileblk(device_t *devp, void* fblkp)
{
//指向文件的fimgrhd_t结构
fimgrhd_t* fmp = (fimgrhd_t*)fblkp;
//完成文件数据的同步
write_rfsdevblk(devp, fblkp, fmp->fmd_sfblk);
//释放缓冲区
del_buf(fblkp, FSYS_ALCBLKSZ);
return DFCOKSTUS;
}
|
第三十五讲 Linux如何管理文件
VFS 虚拟文件系统
VFS(Virtual Filesystem)可以理解问通用文件系统的抽象层,
不管存储设备使用什么文件系统,都可以统一使用一套接口
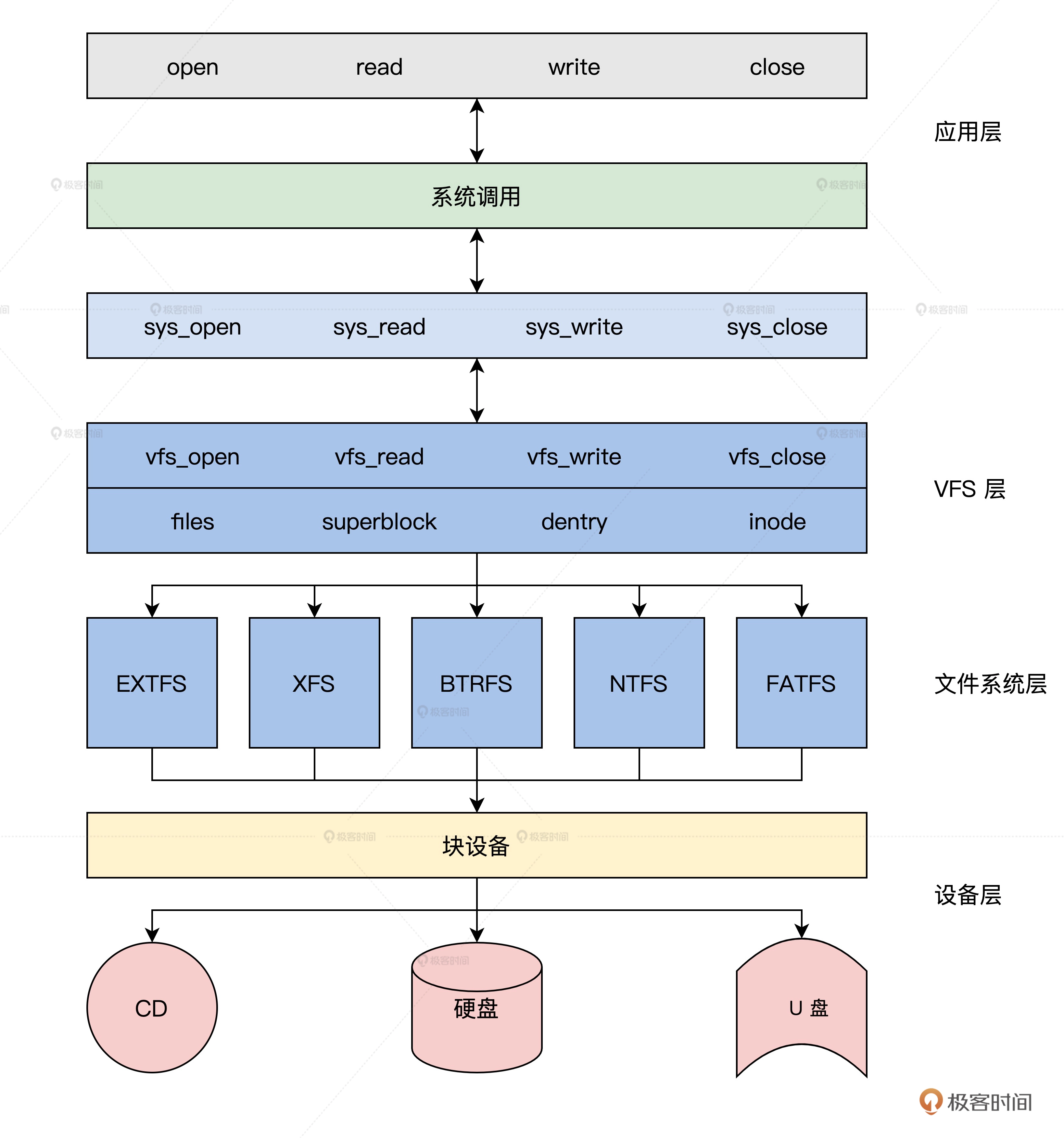
VFS 数据结构
VFS为了屏蔽各个文件系统的差异,必须定义一组统一的数据结构,规范
各个文件系统的实现,每种结构都对应一套回调函数集合。
超级块结构
超级块结构是一个文件系统安装在 VFS 中的标识,其中包含了规定的标准信息,也有具体文件系统的特有信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
struct super_block {
struct list_head s_list; //超级块链表
dev_t s_dev; //设备标识
unsigned char s_blocksize_bits;//以位为单位的块大小
unsigned long s_blocksize;//以字节为单位的块大小
loff_t s_maxbytes; //一个文件最大多少字节
struct file_system_type *s_type; //文件系统类型
const struct super_operations *s_op;//超级块函数集合
const struct dquot_operations *dq_op;//磁盘限额函数集合
unsigned long s_flags;//挂载标志
unsigned long s_magic;//文件系统魔数
struct dentry *s_root;//挂载目录
struct rw_semaphore s_umount;//卸载信号量
int s_count;//引用计数
atomic_t s_active;//活动计数
struct block_device *s_bdev;//块设备
void *s_fs_info;//文件系统信息
time64_t s_time_min;//最小时间限制
time64_t s_time_max;//最大时间限制
char s_id[32]; //标识名称
uuid_t s_uuid; //文件系统的UUID
struct list_lru s_dentry_lru;//LRU方式挂载的目录
struct list_lru s_inode_lru;//LRU方式挂载的索引结点
struct mutex s_sync_lock;//同步锁
struct list_head s_inodes; //所有的索引节点
spinlock_t s_inode_wblist_lock;//回写索引节点的锁
struct list_head s_inodes_wb; //挂载所有要回写的索引节点
} __randomize_layout;
struct super_operations {
//分配一个新的索引结点结构
struct inode *(*alloc_inode)(struct super_block *sb);
//销毁给定的索引节点
void (*destroy_inode)(struct inode *);
//释放给定的索引节点
void (*free_inode)(struct inode *);
//VFS在索引节点为脏(改变)时,会调用此函数
void (*dirty_inode) (struct inode *, int flags);
//该函数用于将给定的索引节点写入磁盘
int (*write_inode) (struct inode *, struct writeback_control *wbc);
//在最后一个指向索引节点的引用被释放后,VFS会调用该函数
int (*drop_inode) (struct inode *);
void (*evict_inode) (struct inode *);
//减少超级块计数调用
void (*put_super) (struct super_block *);
//同步文件系统调用
int (*sync_fs)(struct super_block *sb, int wait);
//释放超级块调用
int (*freeze_super) (struct super_block *);
//释放文件系统调用
int (*freeze_fs) (struct super_block *);
int (*thaw_super) (struct super_block *);
int (*unfreeze_fs) (struct super_block *);
//VFS通过调用该函数,获取文件系统状态
int (*statfs) (struct dentry *, struct kstatfs *);
//当指定新的安装选项重新安装文件系统时,VFS会调用此函数
int (*remount_fs) (struct super_block *, int *, char *);
//VFS调用该函数中断安装操作。该函数被网络文件系统使用,如NFS
void (*umount_begin) (struct super_block *);
};
|
目录结构
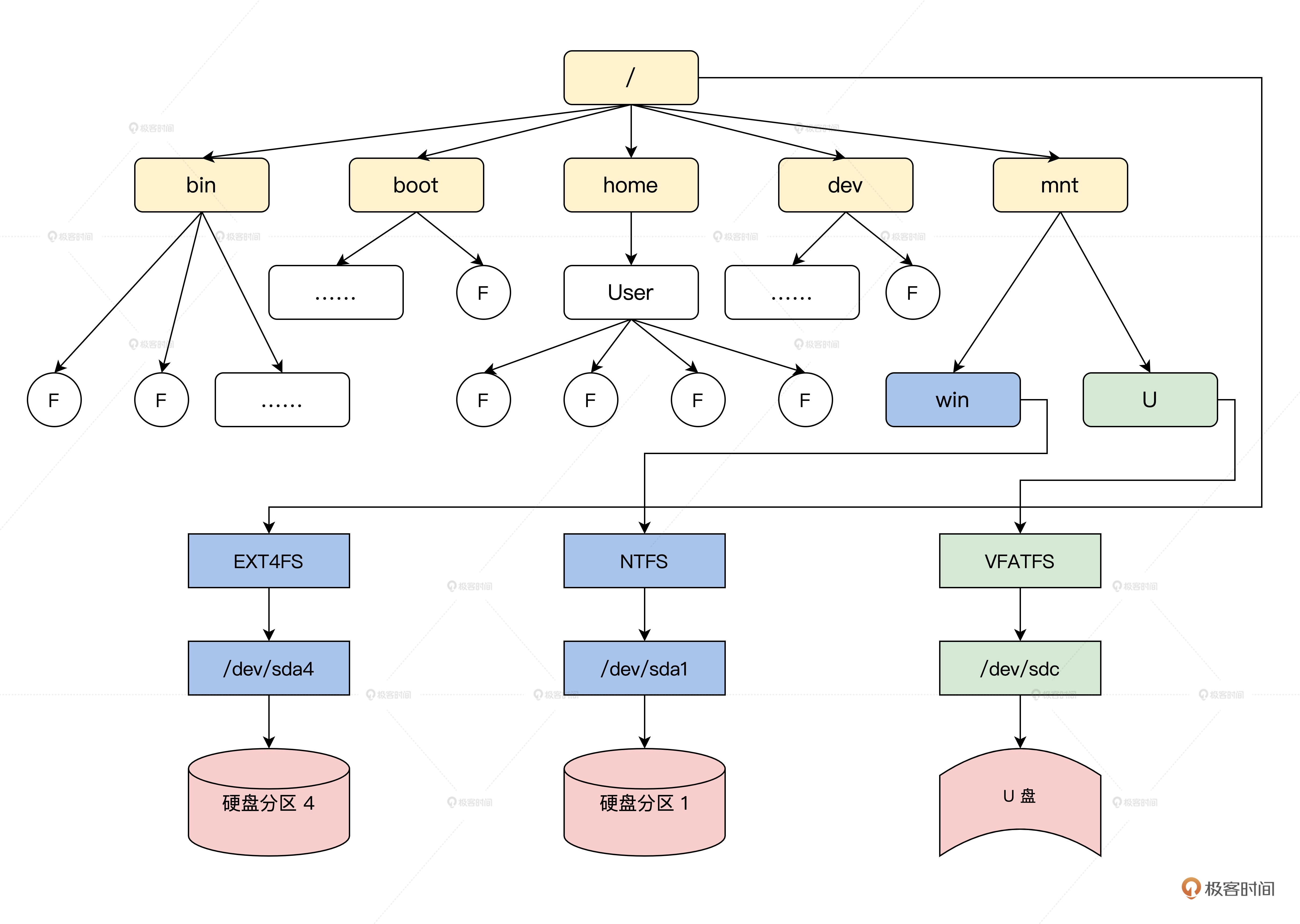
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
//快速字符串保存关于字符串的 "元数据"(即长度和哈希值)
struct qstr {
union {
struct {
HASH_LEN_DECLARE;
};
u64 hash_len;
};
const unsigned char *name;//指向名称字符串
};
struct dentry {
unsigned int d_flags; //目录标志
seqcount_spinlock_t d_seq; //锁
struct hlist_bl_node d_hash;//目录的哈希链表
struct dentry *d_parent; //指向父目录
struct qstr d_name; //目录名称
struct inode *d_inode; //指向目录文件的索引节点
unsigned char d_iname[DNAME_INLINE_LEN]; //短目录名
struct lockref d_lockref; //目录锁与计数
const struct dentry_operations *d_op;//目录的函数集
struct super_block *d_sb; //指向超级块
unsigned long d_time; //时间
void *d_fsdata; //指向具体文件系统的数据
union {
struct list_head d_lru; //LRU链表
wait_queue_head_t *d_wait;
};
struct list_head d_child; //挂入父目录的链表节点
struct list_head d_subdirs; //挂载所有子目录的链表
} __randomize_layout;
//快速字符串保存关于字符串的 "元数据"(即长度和哈希值)
struct qstr {
union {
struct {
HASH_LEN_DECLARE;
};
u64 hash_len;
};
const unsigned char *name;//指向名称字符串
};
struct dentry {
unsigned int d_flags; //目录标志
seqcount_spinlock_t d_seq; //锁
struct hlist_bl_node d_hash;//目录的哈希链表
struct dentry *d_parent; //指向父目录
struct qstr d_name; //目录名称
struct inode *d_inode; //指向目录文件的索引节点
unsigned char d_iname[DNAME_INLINE_LEN]; //短目录名
struct lockref d_lockref; //目录锁与计数
const struct dentry_operations *d_op;//目录的函数集
struct super_block *d_sb; //指向超级块
unsigned long d_time; //时间
void *d_fsdata; //指向具体文件系统的数据
union {
struct list_head d_lru; //LRU链表
wait_queue_head_t *d_wait;
};
struct list_head d_child; //挂入父目录的链表节点
struct list_head d_subdirs; //挂载所有子目录的链表
} __randomize_layout;
|
文件索引节点
inode结构表示一个文件索引节点,里面包含文件权限、文件所属用户、文件访问和修改时间、
文件数据块号等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
struct inode {
umode_t i_mode;//文件访问权限
unsigned short i_opflags;//打开文件时的标志
kuid_t i_uid;//文件所属的用户id
kgid_t i_gid;//文件所属的用户组id
unsigned int i_flags;//标志
const struct inode_operations *i_op;//inode函数集
struct super_block *i_sb;//指向所属超级块
struct address_space *i_mapping;//文件数据在内存中的页缓存
unsigned long i_ino;//inode号
dev_t i_rdev;//实际设备标志符
loff_t i_size;//文件大小,以字节为单位
struct timespec64 i_atime;//文件访问时间
struct timespec64 i_mtime;//文件修改时间
struct timespec64 i_ctime;//最后修改时间
spinlock_t i_lock; //保护inode的自旋锁
unsigned short i_bytes;//使用的字节数
u8 i_blkbits;//以位为单位的块大小;
u8 i_write_hint;
blkcnt_t i_blocks;
struct list_head i_io_list;
struct list_head i_lru; //在缓存LRU中的链表节点
struct list_head i_sb_list;//在超级块中的链表节点
struct list_head i_wb_list;
atomic64_t i_version;//版本号
atomic64_t i_sequence;
atomic_t i_count;//计数
atomic_t i_dio_count;//直接io进程计数
atomic_t i_writecount;//写进程计数
union {
const struct file_operations *i_fop;//文件函数集合
void (*free_inode)(struct inode *);
};
struct file_lock_context *i_flctx;
struct address_space i_data;
void *i_private; //私有数据指针
} __randomize_layout;
struct inode_operations {
//VFS通过系统create()和open()接口来调用该函数,从而为dentry对象创建一个新的索引节点
int (*create) (struct inode *, struct dentry *,int);
//该函数在特定目录中寻找索引节点,该索引节点要对应于dentry中给出的文件名
struct dentry * (*lookup) (struct inode *, struct dentry *);
//被系统link()接口调用,用来创建硬连接。硬链接名称由dentry参数指定
int (*link) (struct dentry *, struct inode *, struct dentry *);
//被系统unlink()接口调用,删除由目录项dentry链接的索引节点对象
int (*unlink) (struct inode *, struct dentry *);
//被系统symlik()接口调用,创建符号连接,该符号连接名称由symname指定,连接对象是dir目录中的dentry目录项
int (*symlink) (struct inode *, struct dentry *, const char *);
//被mkdir()接口调用,创建一个新目录。
int (*mkdir) (struct inode *, struct dentry *, int);
//被rmdir()接口调用,删除dentry目录项代表的文件
int (*rmdir) (struct inode *, struct dentry *);
//被mknod()接口调用,创建特殊文件(设备文件、命名管道或套接字)。
int (*mknod) (struct inode *, struct dentry *, int, dev_t);
//VFS调用该函数来移动文件。文件源路径在old_dir目录中,源文件由old_dentry目录项所指定,目标路径在new_dir目录中,目标文件由new_dentry指定
int (*rename) (struct inode *, struct dentry *, struct inode *, struct dentry *);
//被系统readlink()接口调用,拷贝数据到特定的缓冲buffer中。拷贝的数据来自dentry指定的符号链接
int (*readlink) (struct dentry *, char *, int);
//被VFS调用,从一个符号连接查找他指向的索引节点
int (*follow_link) (struct dentry *, struct nameidata *);
//在follow_link()调用之后,该函数由vfs调用进行清除工作
int (*put_link) (struct dentry *, struct nameidata *);
//被VFS调用,修改文件的大小,在调用之前,索引节点的i_size项必须被设置成预期的大小
void (*truncate) (struct inode *);
//该函数用来检查给定的inode所代表的文件是否允许特定的访问模式,如果允许特定的访问模式,返回0,否则返回负值的错误码
int (*permission) (struct inode *, int);
//被notify_change接口调用,在修改索引节点之后,通知发生了改变事件
int (*setattr) (struct dentry *, struct iattr *);
//在通知索引节点需要从磁盘中更新时,VFS会调用该函数
int (*getattr) (struct vfsmount *, struct dentry *, struct kstat *);
//被VFS调用,向dentry指定的文件设置扩展属性
int (*setxattr) (struct dentry *, const char *, const void *, size_t, int);
//被VFS调用,拷贝给定文件的扩展属性name对应的数值
ssize_t (*getxattr) (struct dentry *, const char *, void *, size_t);
//该函数将特定文件所有属性列表拷贝到一个缓冲列表中
ssize_t (*listxattr) (struct dentry *, char *, size_t);
//该函数从给定文件中删除指定的属性
int (*removexattr) (struct dentry *, const char *);
};
|
实例结构
进程打开的文件使用 file 结构表示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
struct file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path; //文件路径
struct inode *f_inode; //文件对应的inode
const struct file_operations *f_op;//文件函数集合
spinlock_t f_lock; //自旋锁
enum rw_hint f_write_hint;
atomic_long_t f_count;//文件对象计数据。
unsigned int f_flags;//文件标志
fmode_t f_mode;//文件权限
struct mutex f_pos_lock;//文件读写位置锁
loff_t f_pos;//进程读写文件的当前位置
u64 f_version;//文件版本
void *private_data;//私有数据
} __randomize_layout
struct file_operations {
struct module *owner;//所在的模块
loff_t (*llseek) (struct file *, loff_t, int);//调整读写偏移
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);//读
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);//写
int (*mmap) (struct file *, struct vm_area_struct *);//映射
int (*open) (struct inode *, struct file *);//打开
int (*flush) (struct file *, fl_owner_t id);//刷新
int (*release) (struct inode *, struct file *);//关闭
} __randomize_layout;
|
进程结构中有个文件表,这个表其实就是 file 结构的指针数组,进程每打开一个文件就会建立一个 file 结构实例,并将其地址放入数组中,最后
返回对应的数组下标,就是调用 open 函数返回的那个整数。
四大对象结构的关系
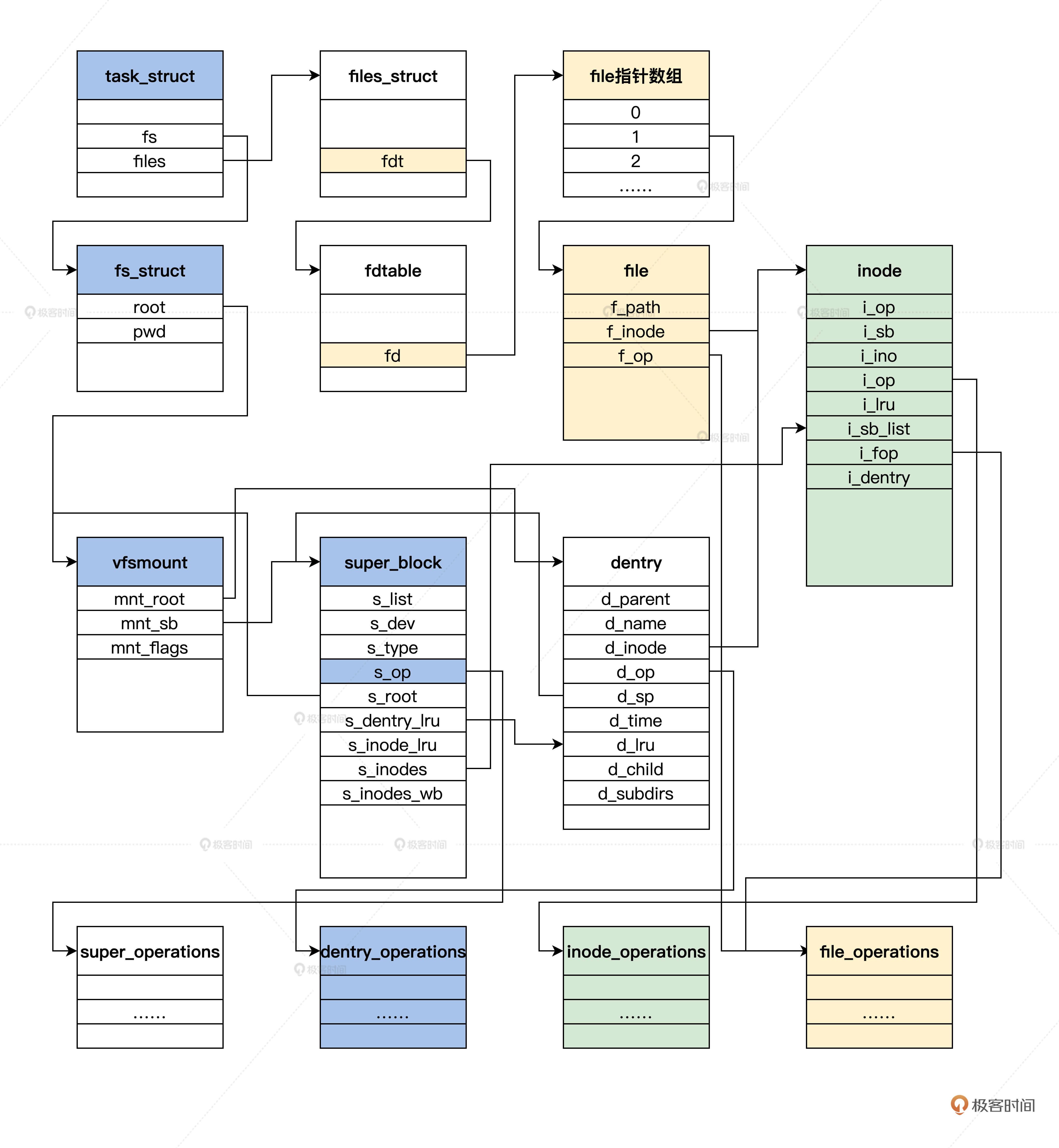
文件操作
打开文件
读写文件
打开一个文件后,就可以进行读写操作了。读操作是数据从文件经由内核流向进程,
而写操作是数据从进程经由内核流向文件。读文件的流程如下:
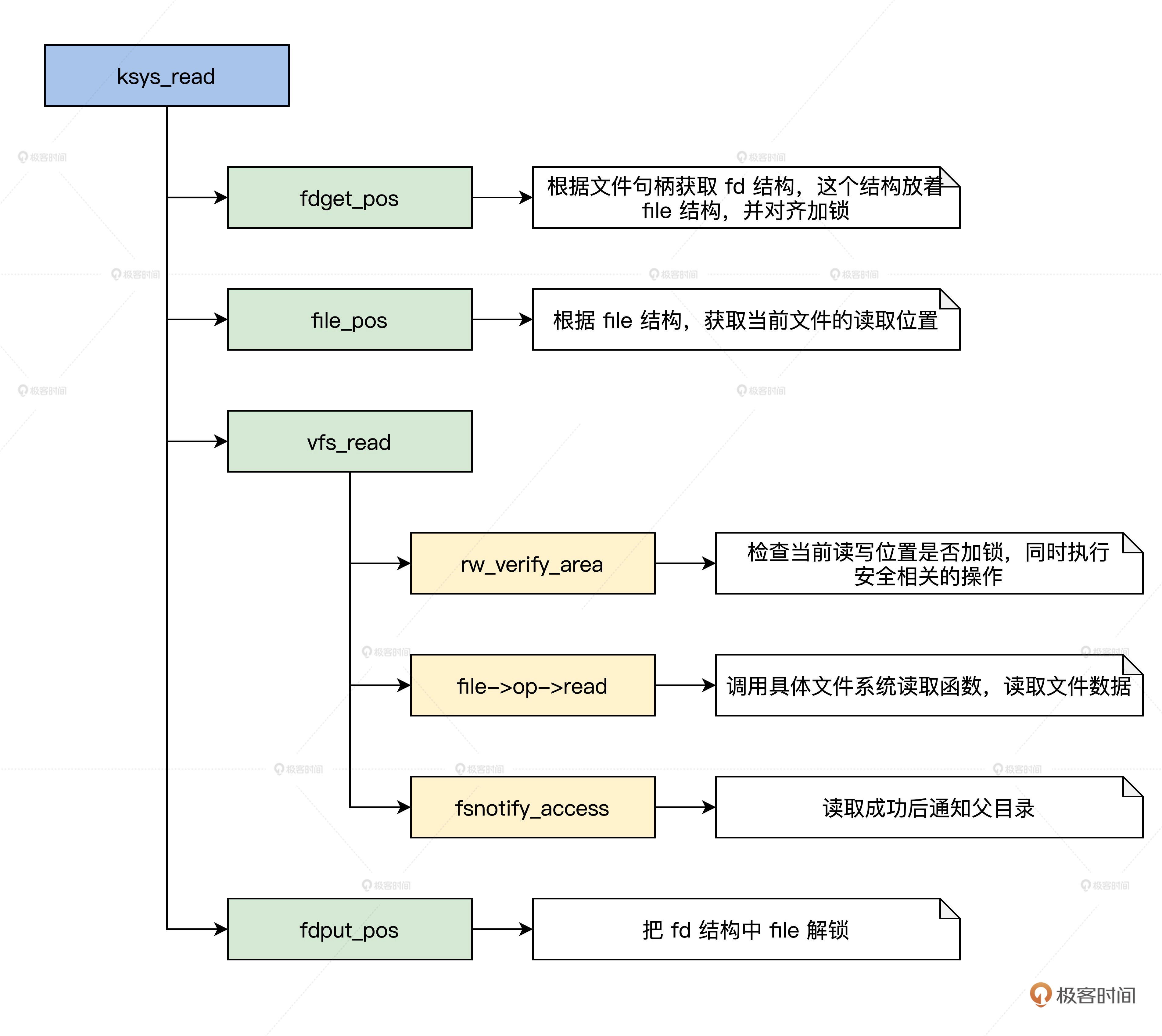
关闭文件
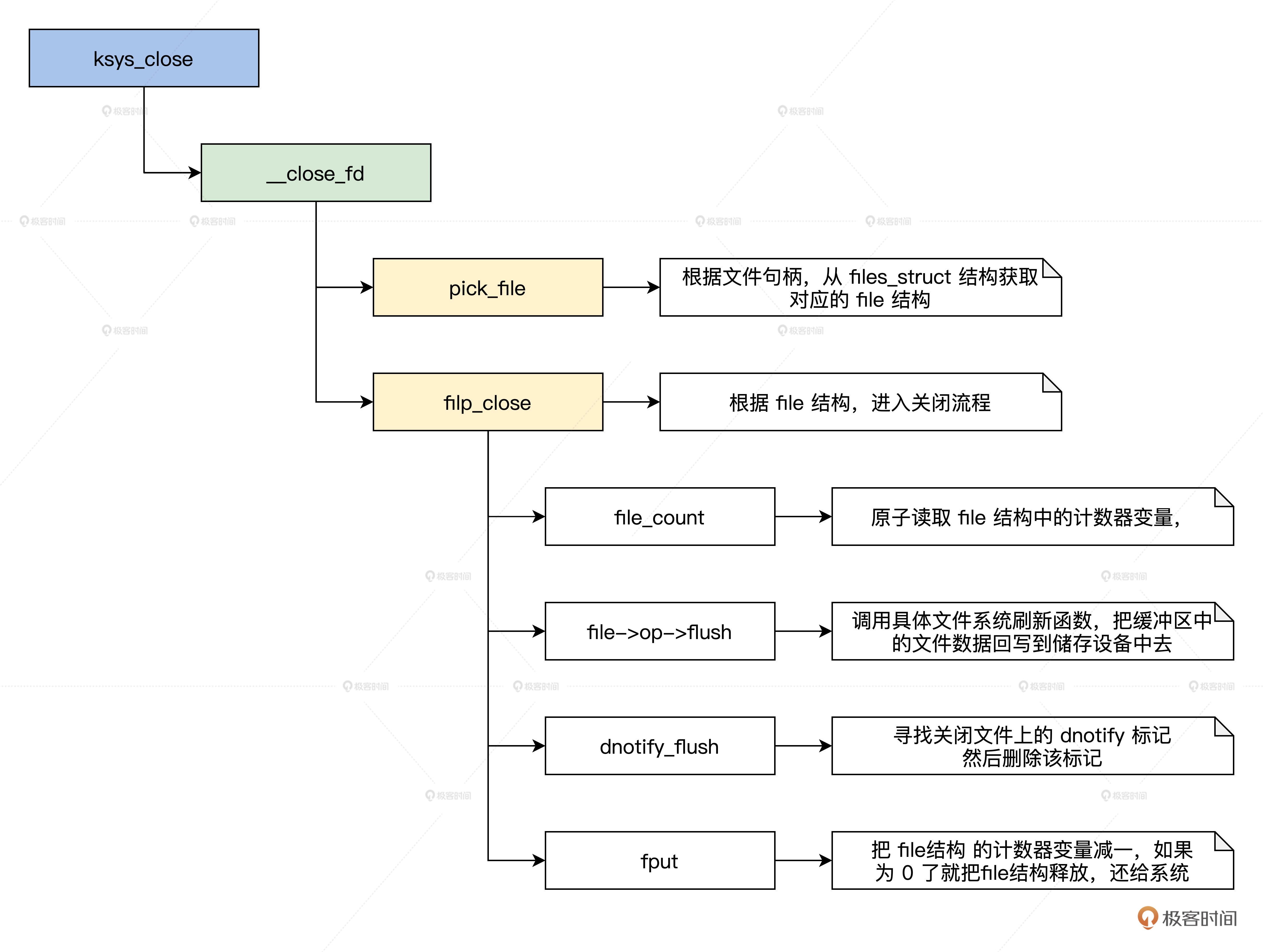
第三十六讲 从 URL 到网卡
前置知识:网络分层和网络协议
当前网络主要遵循 IEEE 802.3标准,基于 OSI 模型。
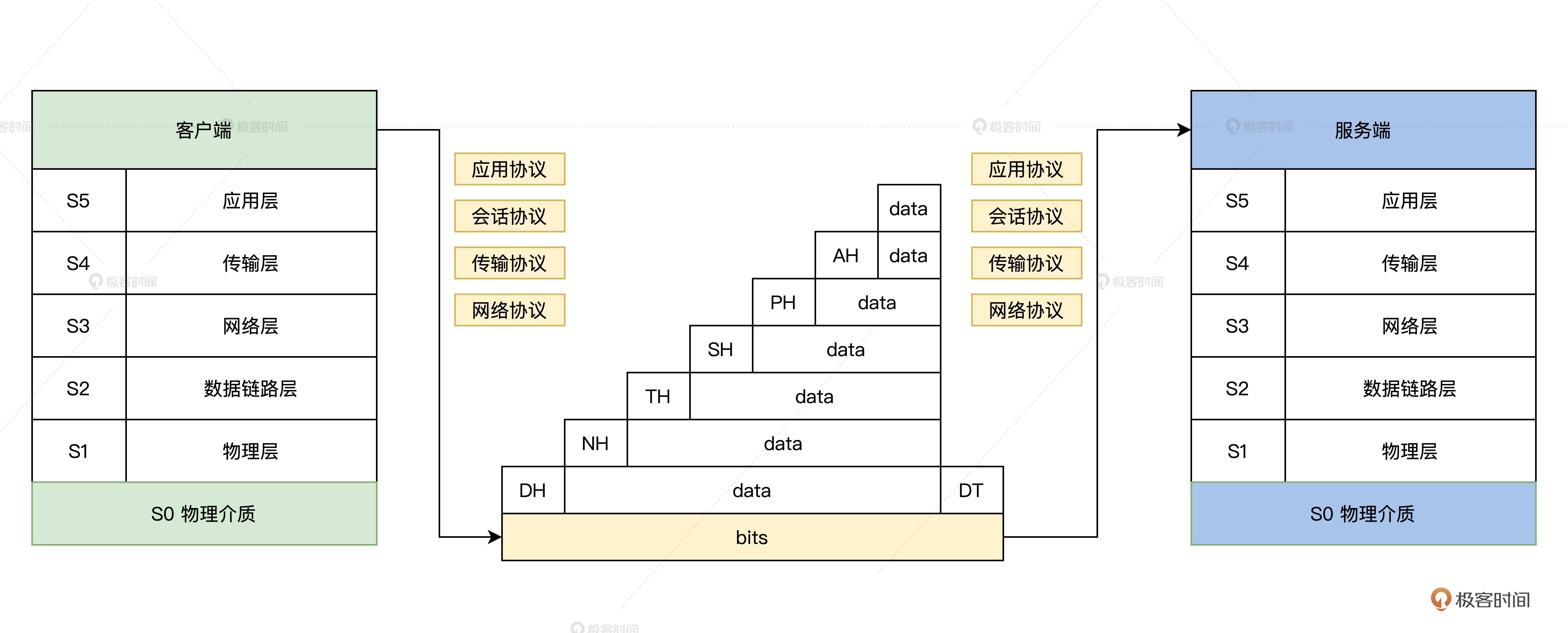
发起请求阶段(应用层)
用户输入:浏览器中输入 URL
用户输入 baidu.com后,浏览器会进行地址补全: https://baidu.com,
然后根据 URL 进行解析,生成 HTTP 请求报文。
网络请求前:查看浏览器缓存
请求发送前,浏览器会检查浏览器缓存和系统缓存,看是否有域名定义的 IP 地址
域名解析:DNS
如果没有缓存,则向 DNS 服务器请求域名对应的 IP 信息
操作系统协议栈 (传输层和网络层)
操作系统支持多个协议栈,TCP/IP 协议栈是现在使用最广泛的网络协议栈。
协议栈的上半部分通过套接字 Socket 和应用层进行交互,应用层委托协议栈上半部分完成数据收发工作;
协议栈的下半部分负责将数据发送到指定的 IP 地址,由 IP 协议连接更下层的网卡驱动。
可靠性传输:建立 TCP 连接
获得 IP 地址后,随机向对应的 IP 发起 TCP 连接。
为了确保通信的可靠性,建立 TCP 会首先进行三次握手的操作
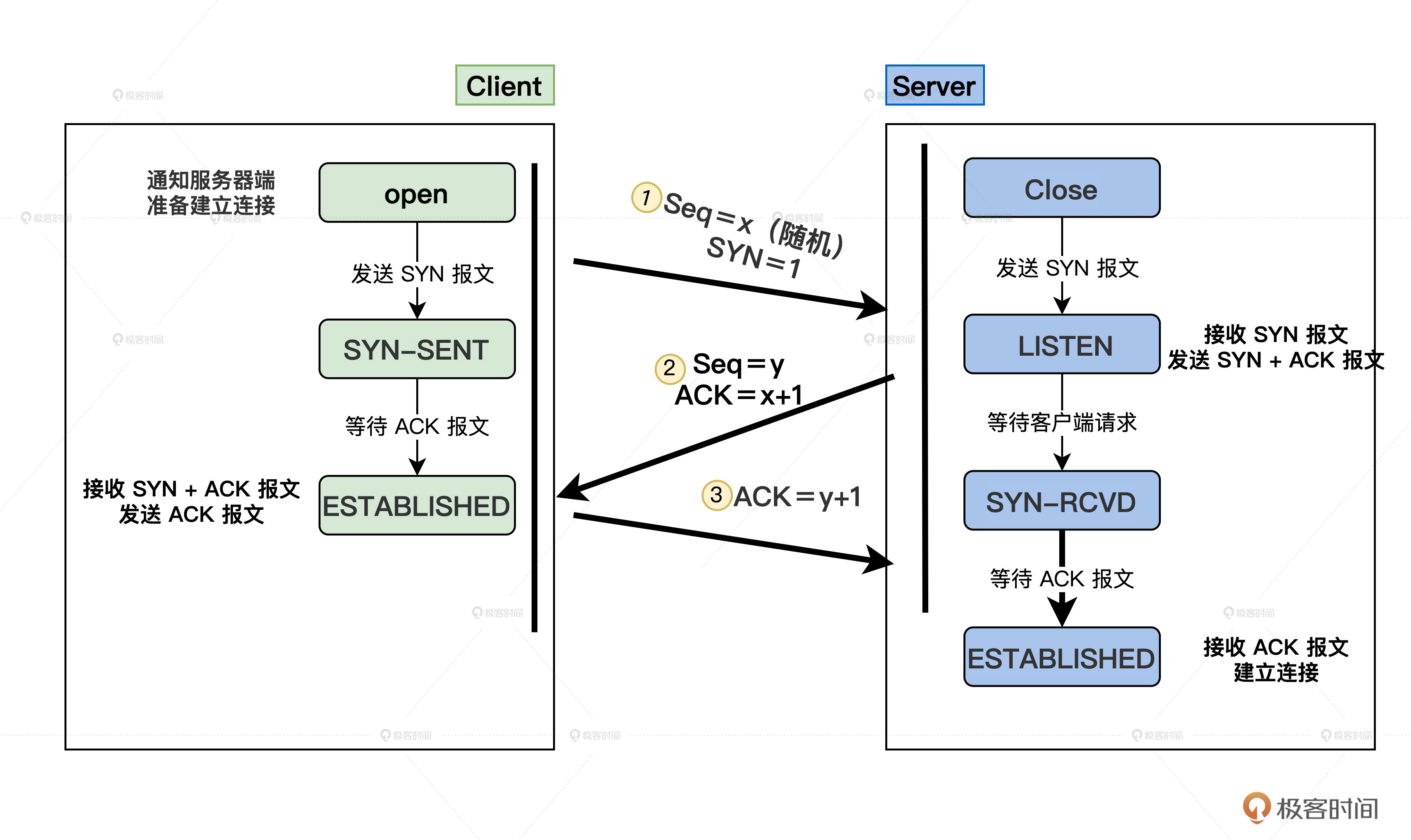

目的地定位:IP 层
IP 协议主要分成三个部分:IP寻址、路由和分包组包
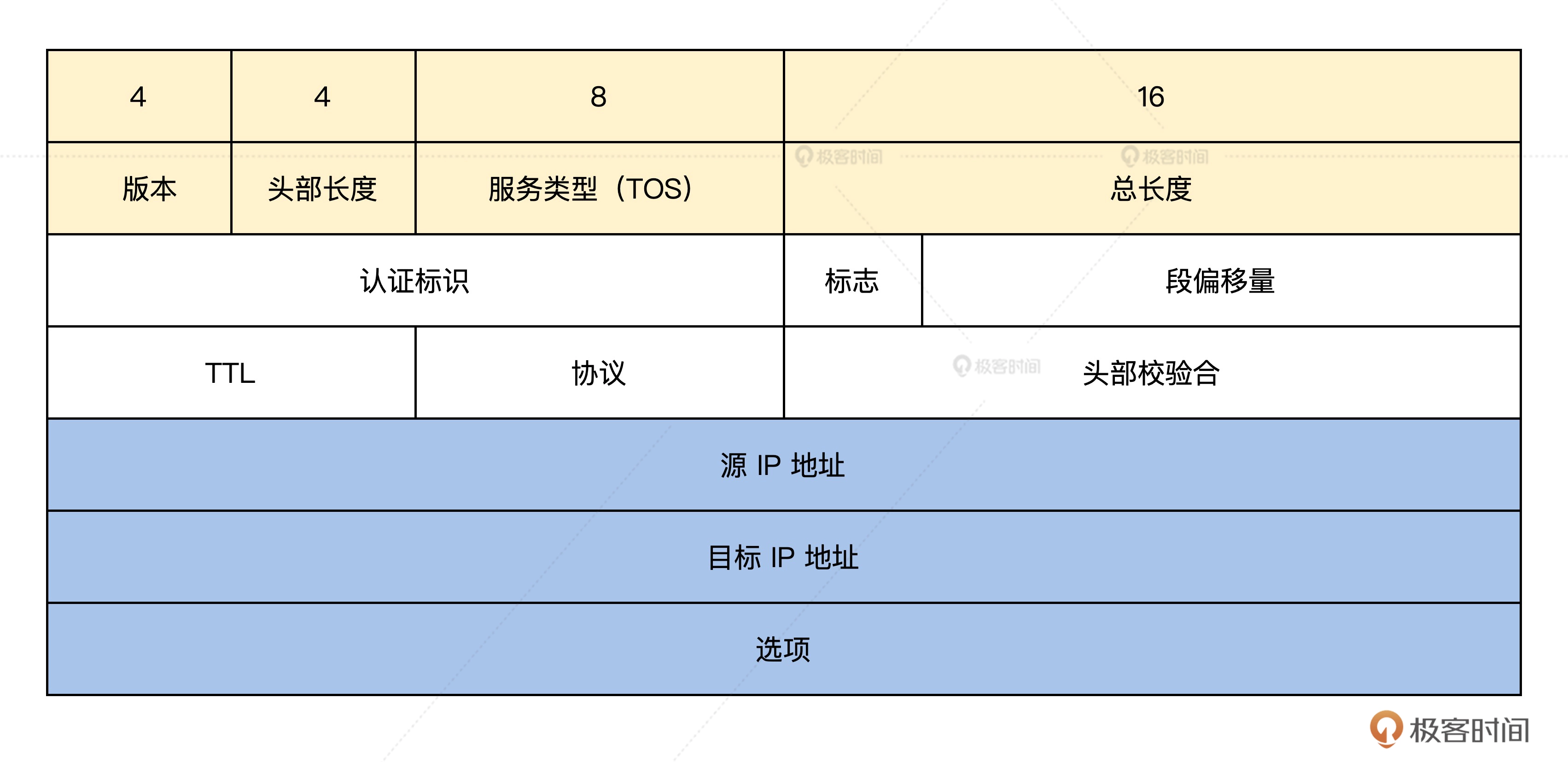
点对点传输:MAC (链路层)
MAC地址是唯一的,固化在网卡中。
接收方的 MAC 地址可以通过 ARP 协议获取

电信号出口:网卡(物理层)
MAC 数据包会被网卡驱动程序写入网卡缓冲区,然后网卡会
在 MAC 数据包的起止位置加入起止帧和校验序列,最后将其转为电信号发送出去
两端数据交换过程
第三十七讲 网络数据如何在内核中流转
网络收发过程
发送
应用程序调用系统API进入内核态
在内核态,复制数据到内核内存空间,然后将数据移交给网络协议栈,
在网络协议栈中将数据层层打包,最后将包装好的数据发送给网卡
接收
网卡接收到数据,通过 DMA 复制到指定内存,接着发送中断,以便
通知网卡驱动,由网卡驱动处理中断复制数据。
然后网络协议收到驱动传过来的数据,层层解包,将有效数据发送给应用进程
IwIP
IwIP 是一个轻量级的开源的TCP/IP网络协议项目
第三十八讲 详解操作系统宏观网络架构
传统网络架构
传统网络架构分为三层:核心层、汇聚层和接入层
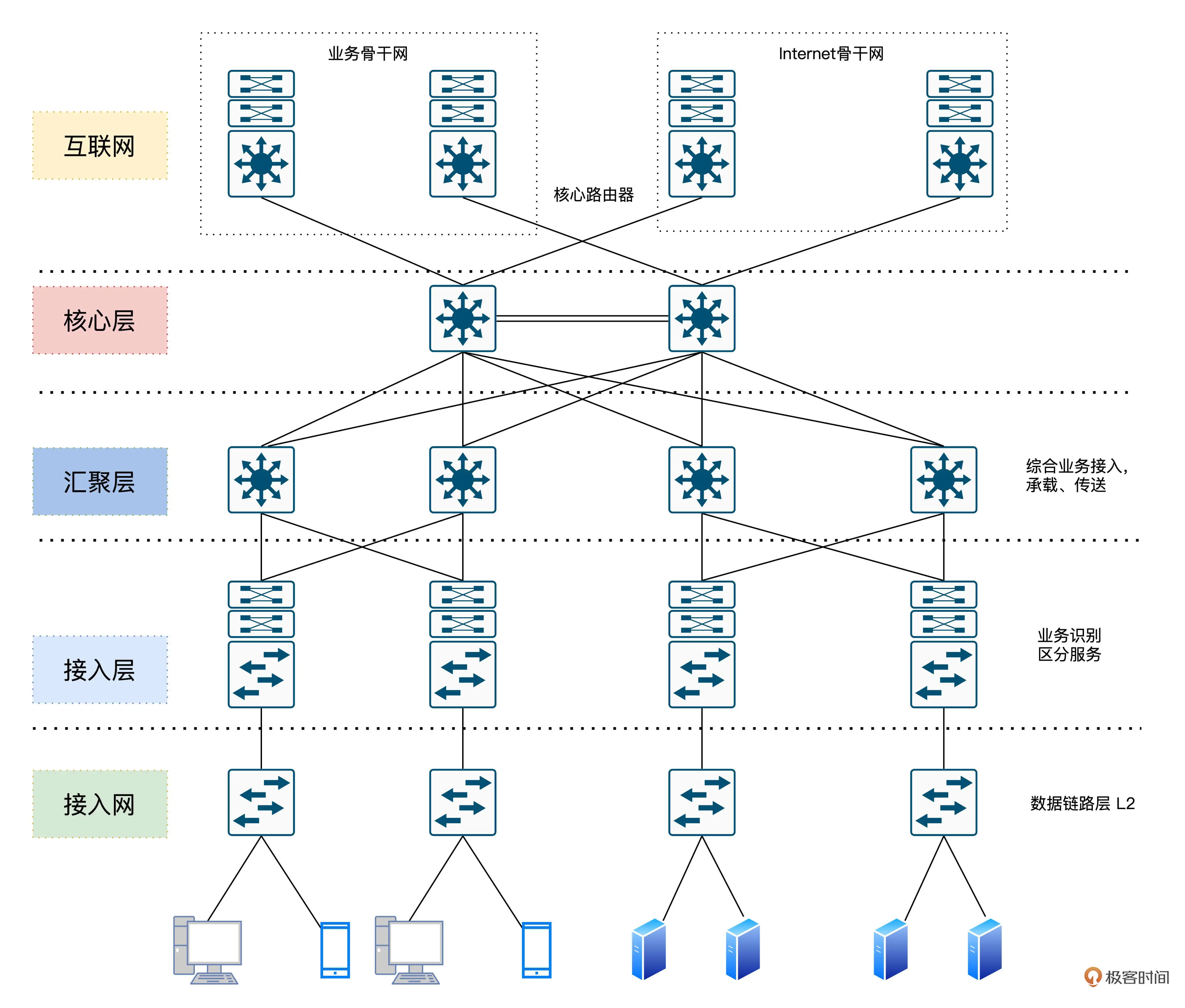
核心层:交换机为进出数据中心的数据包提供高速转发的功能,为多个
汇聚层提供连通性,同时也为整个网络提供灵活的 L3 路由网络。
汇聚层:提供防火墙、SSL卸载、入侵检测、网络分析等功能
接入层:与服务器物理连接
多协议标签交换 MPLS
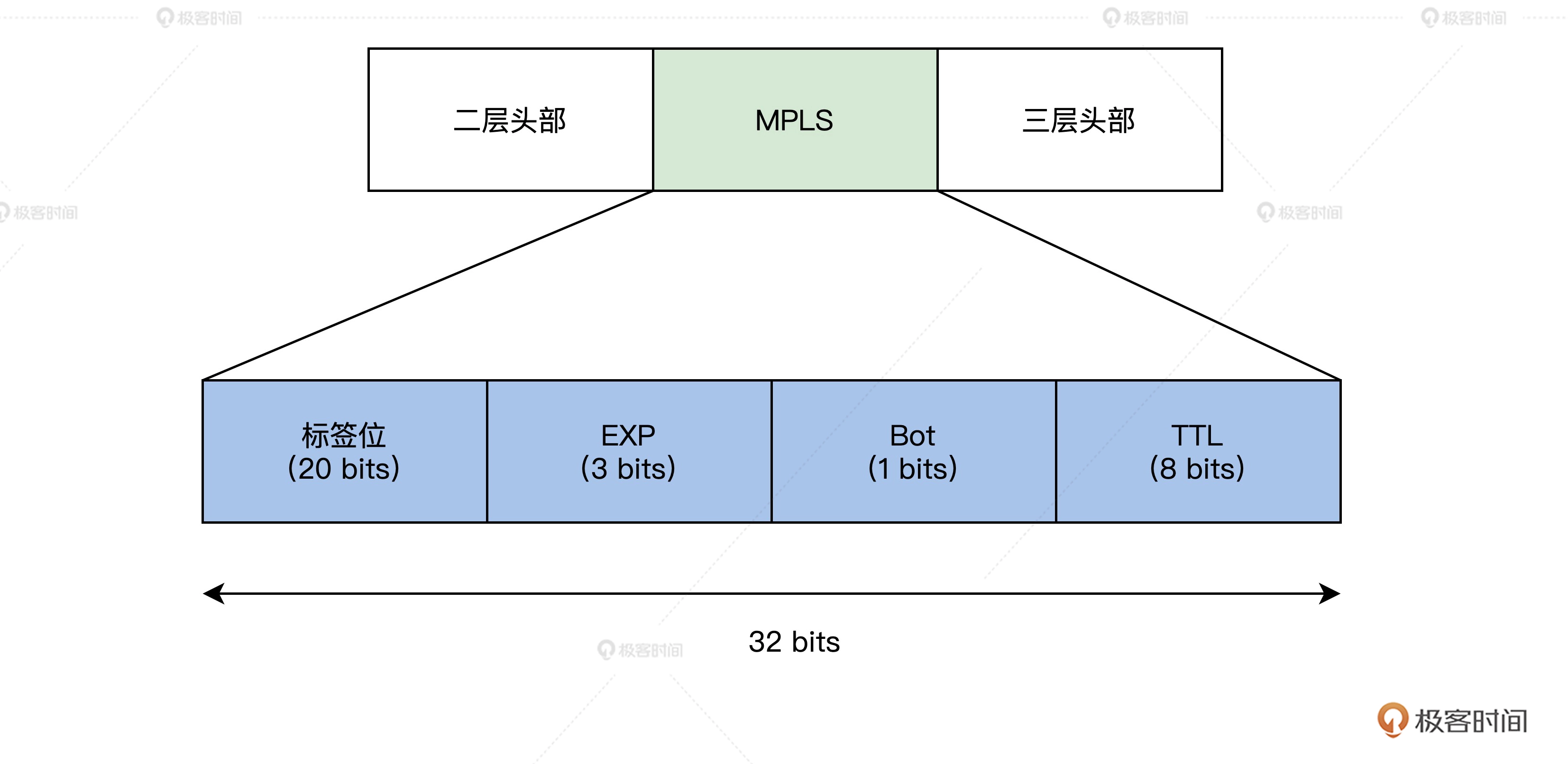
MPLS 通过 LDP 标签分发协议,相当于给快递贴了标签,后续只需只要读标签而不用打开快递来确认目的地
Google B4
SDN
ONOS
总结
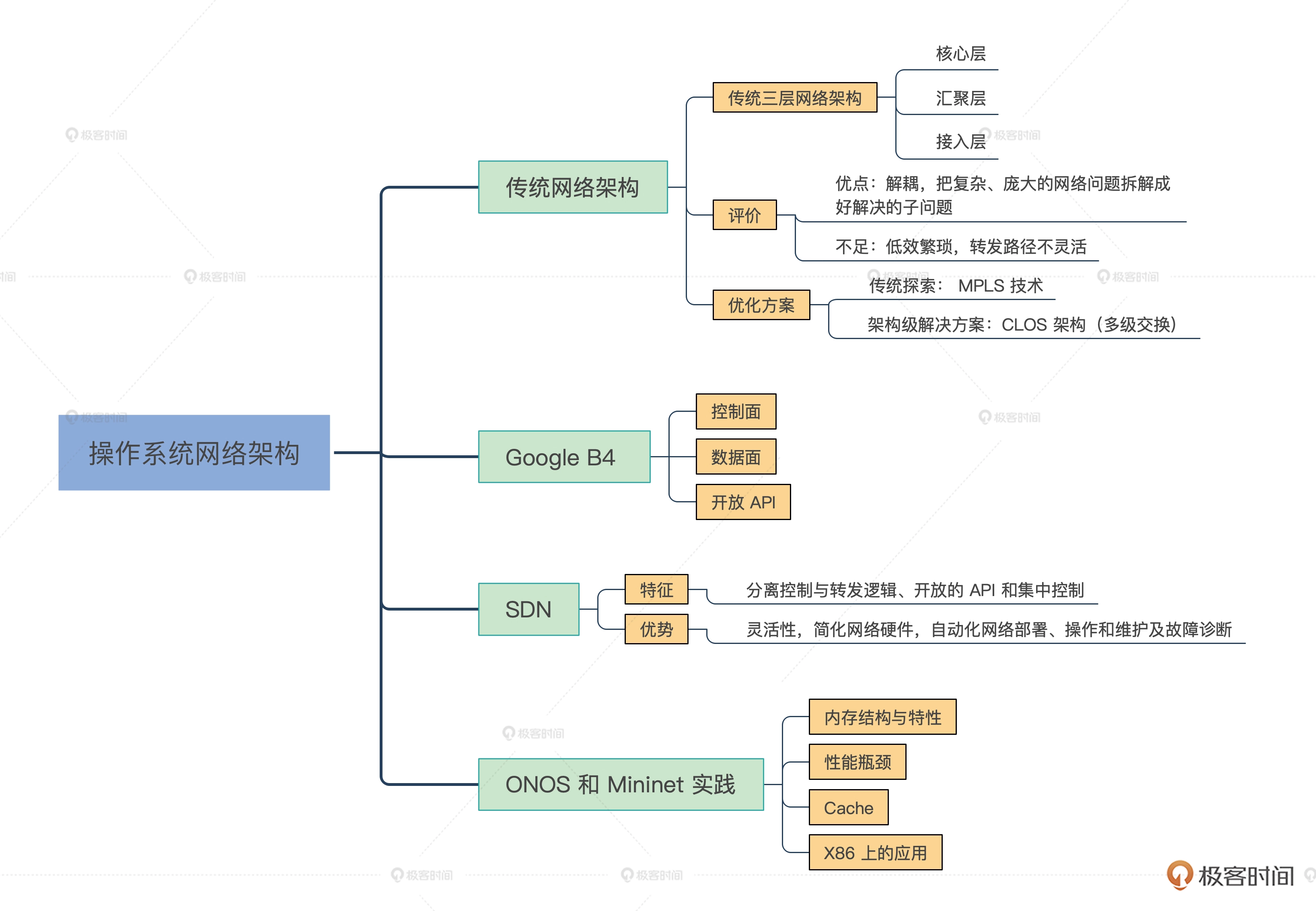
第三十九讲 Linux socket 接口
套接字
网络套接字是 TCP/IP 协议栈中传输层协议的接口,也是 传输层以上所有协议的实现。
同时,套接字接口在网络程序功能中是内核与应用层之间的接口。
套接字的数据结构
struct socket
1
2
3
4
5
6
7
8
9
10
|
struct socket {
socket_state state; // 套接字的状态
unsigned long flags; // 套接字的设置标志。存放套接字等待缓冲区的状态信息,其值的形式如SOCK_ASYNC_NOSPACE等
struct fasync_struct *fasync_list; // 等待被唤醒的套接字列表,该链表用于异步文件调用
struct file *file; // 套接字所属的文件描述符
struct sock *sk; // 指向存放套接字属性的结构指针
wait_queue_head_t wait; //套接字的等待队列
short type; // 套接字的类型。其取值为SOCK_XXXX形式
const struct proto_ops *ops; // 套接字层的操作函数块
}
|
struct sock
struct sock 数据结构包含了大量内核管理套接字的信息,内核把最重要的成员存放在 struct sock_common 数据结构中。
1
2
3
4
5
6
7
8
9
|
struct sock_common {
unsigned short skc_family; /*地址族*/
volatile unsigned char skc_state; /*连接状态*/
unsigned char skc_reuse; /*SO_REUSEADDR设置*/
int skc_bound_dev_if;
struct hlist_node skc_node;
struct hlist_node skc_bind_node; /*哈希表相关*/
atomic_t skc_refcnt; /*引用计数*/
};
|
套接字与文件
每个套接字都分配了一个 VFS inode,通过 inode 可以用文件操作来访问套接字
1
2
3
4
5
6
7
8
|
struct inode{
struct file_operation *i_fop // 指向默认文件操作函数块
}
struct socket_slloc {
struct socket socket;
struct inode vfs_inode;
}
|
套接字与缓存 Socket Buffer
套接字缓存代表了一个要发送或者处理的报文,是网络数据包在内核中的对象实例。
缓存主要包含两部分:
- 数据包:存放网络中实际流通的数据
- 管理数据结构 struct sk_buff: 包含协议交换信息、数据状态等
套接字初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
static int __init sock_init(void) {
int err;
/*
* 初始化.sock缓存
*/
sk_init();
/*
* 初始化sk_buff缓存
skb_init();
/* 初始化协议模块缓存
init_inodecache();
/* 注册文件系统类型 */
err = register_filesystem(&sock_fs_type);
if (err) goto out_fs;
sock_mnt = kern_mount(&sock_fs_type);
if (IS_ERR(sock_mnt)) {
err = PTR_ERR(sock_mnt);
goto out_mount;
}
}
|
地址族的值和协议交换表
套接字是一个通用接口,可以与多个协议组建立接口。
struct inet_protosw 实现了协议交换表,将应用程序通过 socketcall 系统
调用的指定套接字操作转换成对某个协议实现的套接字操作函数的调用
1
2
3
4
5
6
7
8
9
10
11
|
struct inet_protosw {
struct list_head list;
unsigned short type; /* AF_INET协议族套接字的类型,如TCP为SOCK_STREAM*/
unsigned short protocol; /* 协议族中某个协议实例的编号。如TCP协议的编码为IPPROTO_TCP */
struct proto *prot;
const struct proto_ops *ops;
unsigned char flags; /* 该套接字属性的相关标志 */
}
|
第四十讲 socket 接口实现
套接字创建
一个新的 struct socket 数据结构起始由 sock_create 函数创建,该函数直接调用 __sock_create 函数,__sock_create 函数的任务是为套接字预留需要的内存空间,由 sock_alloc 函数完成这项功能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
static int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern)
{
int err;
struct socket *sock;
const struct net_proto_family *pf;
// 首先检验是否支持协议族
/*
* 检查是否在内核支持的socket范围内
*/
if (family < 0 || family >= NPROTO)
return -EAFNOSUPPORT;
if (type < 0 || type >= SOCK_MAX)
return -EINVAL;
/*
* 为新的套接字分配内存空间,分配成功后返回新的指针
*/
sock = sock_alloc();
}
static struct socket *sock_alloc(void) {
struct inode *inode;
struct socket *sock;
// 初始化一个可用的inode节点, 在fs/inode.c中
inode = new_inode(sock_mnt->mnt_sb);
if (!inode)
return NULL;
// 实际创建的是socket_alloc复合对象,因此要使用SOCKET_I宏从inode中取出关联的socket对象用于返回
sock = SOCKET_I(inode);
kmemcheck_annotate_bitfield(sock, type);
// 文件类型为套接字
inode->i_mode = S_IFSOCK | S_IRWXUGO;
inode->i_uid = current_fsuid();
inode->i_gid = current_fsgid();
percpu_add(sockets_in_use, 1);
return sock;
}
|
套接字的绑定
创建完套接字后,需要将套接字和地址绑定起来
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
|
asmlinkage long sysbind (bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen)
{
struct socket *sock;
struct sockaddr_storage address;
int err, fput_needed;
/*
* 获取socket实例。
*/
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
err = move_addr_to_kernel(umyaddr, addrlen, (struct sockaddr *)&address);
if (err >= 0) {
err = security_socket_bind(sock,
(struct sockaddr *)&address,
addrlen);
/*
* 如果是TCP套接字,sock->ops指向的是inet_stream_ops,
* sock->ops是在inet_create()函数中初始化,所以bind接口
* 调用的是inet_bind()函数。
*/
if (!err)
err = sock->ops->bind(sock,
(struct sockaddr *)
&address, addrlen);
}
fput_light(sock->file, fput_needed);
}
return err;
}
int inet_bind(struct socket *sock, struct sockaddr *uaddr, int addr_len)
{
struct sockaddr_in *addr = (struct sockaddr_in *)uaddr;
struct sock *sk = sock->sk;
struct inet_sock *inet = inet_sk(sk);
unsigned short snum;
int chk_addr_ret;
int err;
if (sk->sk_prot->bind) {/* 如果传输层接口上实现了bind调用,则回调它。目前只有SOCK_RAW类型的传输层实现了该接口raw_bind */
err = sk->sk_prot->bind(sk, uaddr, addr_len);
goto out;
}
err = -EINVAL;
if (addr_len < sizeof(struct sockaddr_in))
goto out;
err = -EADDRNOTAVAIL;
if (!sysctl_ip_nonlocal_bind &&/* 必须绑定到本地接口的地址 */
!inet->freebind &&
addr->sin_addr.s_addr != INADDR_ANY &&/* 绑定地址不合法 */
chk_addr_ret != RTN_LOCAL &&
chk_addr_ret != RTN_MULTICAST &&
chk_addr_ret != RTN_BROADCAST)
goto out;
snum = ntohs(addr->sin_port);
err = -EACCES;
if (snum && snum < PROT_SOCK && !capable(CAP_NET_BIND_SERVICE))
goto out;
lock_sock(sk);/* 对套接口进行加锁,因为后面要对其状态进行判断 */
/* Check these errors (active socket, double bind). */
err = -EINVAL;
/**
* 如果状态不为CLOSE,表示套接口已经处于活动状态,不能再绑定
* 或者已经指定了本地端口号,也不能再绑定
*/
if (sk->sk_state != TCP_CLOSE || inet->num)
goto out_release_sock;
/* 设置地址到传输控制块中 */
inet->rcv_saddr = inet->saddr = addr->sin_addr.s_addr;
/* 如果是广播或者多播地址,则源地址使用设备地址。 */
if (chk_addr_ret == RTN_MULTICAST || chk_addr_ret == RTN_BROADCAST)
inet->saddr = 0; /* Use device */
/* 调用传输层的get_port来进行地址绑定。如tcp_v4_get_port或udp_v4_get_port */
if (sk->sk_prot->get_port(sk, snum)) {
…
}
/* 设置标志,表示已经绑定了本地地址和端口 */
if (inet->rcv_saddr)
sk->sk_userlocks |= SOCK_BINDADDR_LOCK;
if (snum)
sk->sk_userlocks |= SOCK_BINDPORT_LOCK;
inet->sport = htons(inet->num);
/* 还没有连接到对方,清除远端地址和端口 */
inet->daddr = 0;
inet->dport = 0;
/* 清除路由缓存 */
sk_dst_reset(sk);
err = 0;
out_release_sock:
release_sock(sk);
out:
return err;
}
|
主动连接
当应用程序调用 connect 函数发出连接请求时,内核会启动 函数 sys_connect
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
int __sys_connect(int fd, struct sockaddr __user *uservaddr, int addrlen)
{
int ret = -EBADF;
struct fd f;
f = fdget(fd);
if (f.file) {
struct sockaddr_storage address;
ret = move_addr_to_kernel(uservaddr, addrlen, &address);
if (!ret)
// 调用__sys_connect_file
ret = __sys_connect_file(f.file, &address, addrlen, 0);
fdput(f);
}
return ret;
}
|
监听套接字
调用 listen 函数后,对应的套接字设为监听模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
int __sys_listen(int fd, int backlog)
{
struct socket *sock;
int err, fput_needed;
int somaxconn;
// 通过套接字描述符�找到struct socket
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
if ((unsigned int)backlog > somaxconn)
backlog = somaxconn;
err = security_socket_listen(sock, backlog);
if (!err)
// 根据套接字类型调用监听函数
err = sock->ops->listen(sock, backlog);
fput_light(sock->file, fput_needed);
}
return err;
}
|
被动接收连接
调用 accept 函数后,会触发内核函数 sys_accept,等待接受连接请求,如果允许连接,
则重新创建一个代表该连接的套接字。
新的套接字和原套接字使用的类型、协议一样,原套接字不与连接关联,继续监听接收新的连接请求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
int __sys_accept4_file(struct file *file, unsigned file_flags,
struct sockaddr __user *upeer_sockaddr,
int __user *upeer_addrlen, int flags,
unsigned long nofile)
{
struct socket *sock, *newsock;
struct file *newfile;
int err, len, newfd;
struct sockaddr_storage address;
if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK))
return -EINVAL;
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
sock = sock_from_file(file, &err);
if (!sock)
goto out;
err = -ENFILE;
// 创建一个新套接字
newsock = sock_alloc();
if (!newsock)
goto out;
newsock->type = sock->type;
newsock->ops = sock->ops;
__module_get(newsock->ops->owner);
newfd = __get_unused_fd_flags(flags, nofile);
if (unlikely(newfd < 0)) {
err = newfd;
sock_release(newsock);
goto out;
}
newfile = sock_alloc_file(newsock, flags, sock->sk->sk_prot_creator->name);
if (IS_ERR(newfile)) {
err = PTR_ERR(newfile);
put_unused_fd(newfd);
goto out;
}
err = security_socket_accept(sock, newsock);
if (err)
goto out_fd;
// 根据套接字类型调用不同的函数inet_accept
err = sock->ops->accept(sock, newsock, sock->file->f_flags | file_flags,
false);
if (err < 0)
goto out_fd;
if (upeer_sockaddr) {
len = newsock->ops->getname(newsock,
(struct sockaddr *)&address, 2);
if (len < 0) {
err = -ECONNABORTED;
goto out_fd;
}
// 从内核复制到用户空间
err = move_addr_to_user(&address,
len, upeer_sockaddr, upeer_addrlen);
if (err < 0)
goto out_fd;
}
/* File flags are not inherited via accept() unlike another OSes. */
fd_install(newfd, newfile);
err = newfd;
out:
return err;
out_fd:
fput(newfile);
put_unused_fd(newfd);
goto out;
}
|
发送数据
调用 send 函数时,会触发内核的 sys_send 函数,sys_send 函数调用流程如下:
- 应用程序的数据被复制到内核后,sys_send 函数调用 sock_sendmsg,依据协议族类型来执行发送操作
- 如采用 TCP 协议,将调用 tcp_sendmsg, 按照 TCP 协议发送数据包到网卡
接收数据
调用 recv 函数时,会触发内核的 sys_recv 函数,为把内核的网络数据转入到应用程序的接收缓冲区,
sys_recv 函数会依次调用 sys_recvfrom、sock_recvfrom 和 __sock_recvmsg,
并依据协议族类型来执行具体的接收操作。
关闭连接
调用 shutdown 函数时,内核器 启动 sys_shutdown 函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
int __sys_shutdown(int fd, int how)
{
int err, fput_needed;
struct socket *sock;
sock = sockfd_lookup_light(fd, &err, &fput_needed);/* 通过套接字,描述符找到对应的结构*/
if (sock != NULL) {
err = security_socket_shutdown(sock, how);
if (!err)
/* 根据套接字协议族调用关闭函数*/
err = sock->ops->shutdown(sock, how);
fput_light(sock->file, fput_needed);
}
return err;
}
|
第四十一讲 服务接口
系统服务函数的执行过程
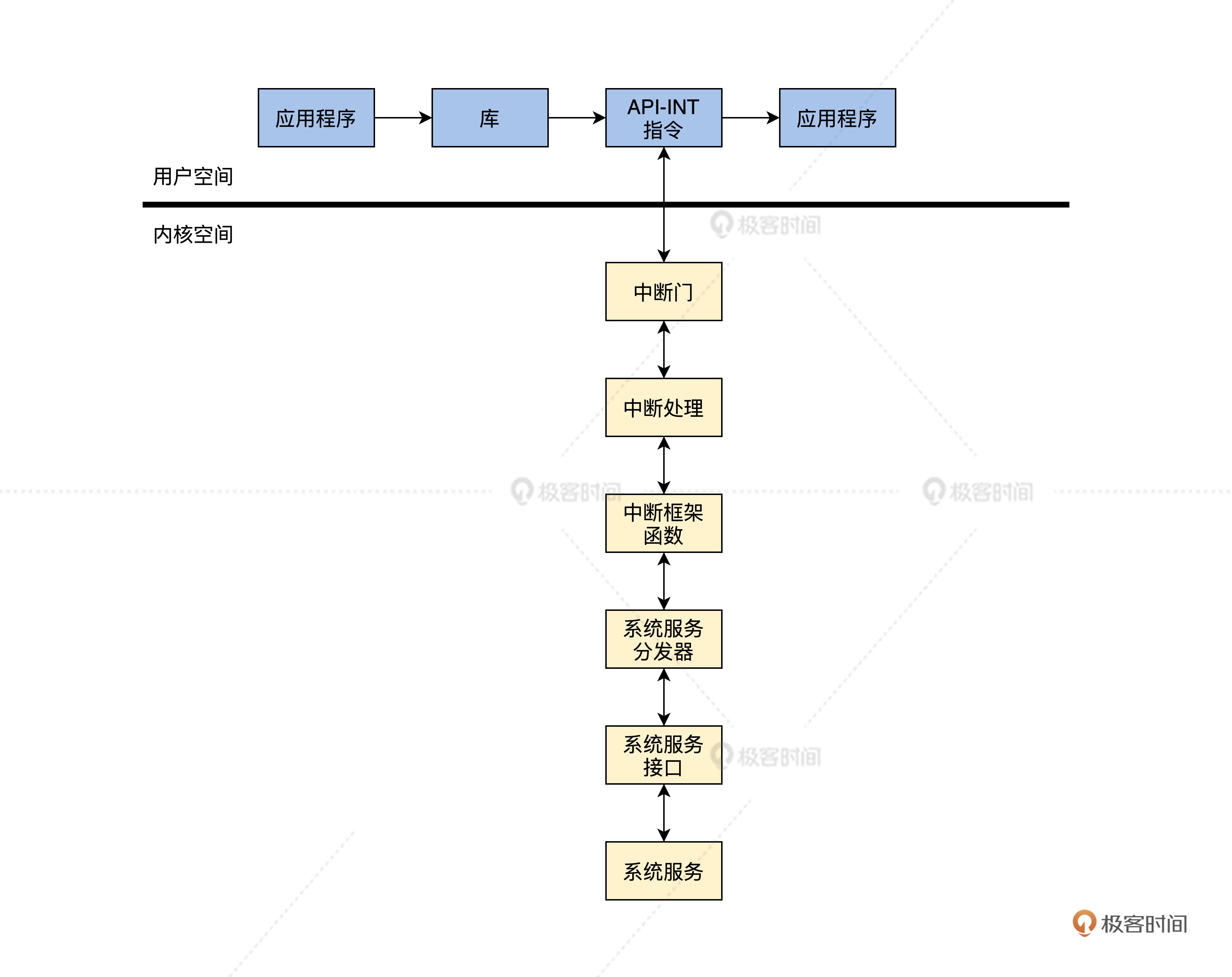
第四十二讲 Linux 如何实现系统 API
内核API接口架构
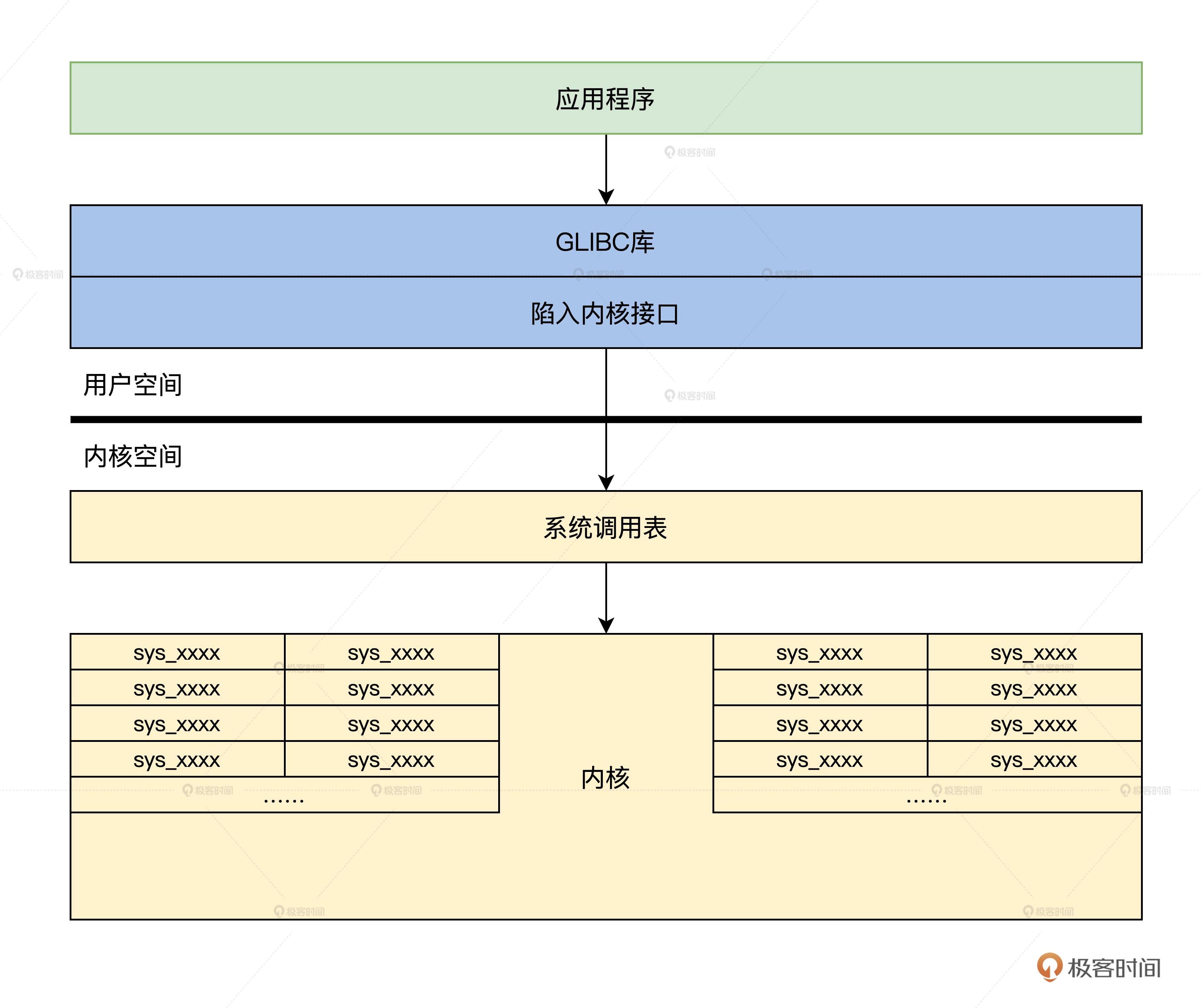
应用程序调用库函数,在库函数中调用 API 入口函数,触发中断进入内核执行系统调用。
linux 最广泛使用的 C 库是 glibc,其中 open 函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
//glibc/intl/loadmsgcat.c
#ifdef _LIBC
# define open(name, flags) __open_nocancel (name, flags)
# define close(fd) __close_nocancel_nostatus (fd)
#endif
//glibc/sysdeps/unix/sysv/linux/open_nocancel.c
int __open_nocancel (const char *file, int oflag, ...)
{
int mode = 0;
if (__OPEN_NEEDS_MODE (oflag))
{
va_list arg;
va_start (arg, oflag);//解决可变参数
mode = va_arg (arg, int);
va_end (arg);
}
return INLINE_SYSCALL_CALL (openat, AT_FDCWD, file, oflag, mode);
}
//glibc/sysdeps/unix/sysdep.h
//这是为了解决不同参数数量的问题
#define __INLINE_SYSCALL0(name) \
INLINE_SYSCALL (name, 0)
#define __INLINE_SYSCALL1(name, a1) \
INLINE_SYSCALL (name, 1, a1)
#define __INLINE_SYSCALL2(name, a1, a2) \
INLINE_SYSCALL (name, 2, a1, a2)
#define __INLINE_SYSCALL3(name, a1, a2, a3) \
INLINE_SYSCALL (name, 3, a1, a2, a3)
#define __INLINE_SYSCALL_NARGS_X(a,b,c,d,e,f,g,h,n,...) n
#define __INLINE_SYSCALL_NARGS(...) \
__INLINE_SYSCALL_NARGS_X (__VA_ARGS__,7,6,5,4,3,2,1,0,)
#define __INLINE_SYSCALL_DISP(b,...) \
__SYSCALL_CONCAT (b,__INLINE_SYSCALL_NARGS(__VA_ARGS__))(__VA_ARGS__)
#define INLINE_SYSCALL_CALL(...) \
__INLINE_SYSCALL_DISP (__INLINE_SYSCALL, __VA_ARGS__)
//glibc/sysdeps/unix/sysv/linux/sysdep.h
//关键是这个宏
#define INLINE_SYSCALL(name, nr, args...) \
({ \
long int sc_ret = INTERNAL_SYSCALL (name, nr, args); \
__glibc_unlikely (INTERNAL_SYSCALL_ERROR_P (sc_ret)) \
? SYSCALL_ERROR_LABEL (INTERNAL_SYSCALL_ERRNO (sc_ret)) \
: sc_ret; \
})
#define INTERNAL_SYSCALL(name, nr, args...) \
internal_syscall##nr (SYS_ify (name), args)
#define INTERNAL_SYSCALL_NCS(number, nr, args...) \
internal_syscall##nr (number, args)
//这是需要6个参数的宏
#define internal_syscall6(number, arg1, arg2, arg3, arg4, arg5, arg6) \
({ \
unsigned long int resultvar; \
TYPEFY (arg6, __arg6) = ARGIFY (arg6); \
TYPEFY (arg5, __arg5) = ARGIFY (arg5); \
TYPEFY (arg4, __arg4) = ARGIFY (arg4); \
TYPEFY (arg3, __arg3) = ARGIFY (arg3); \
TYPEFY (arg2, __arg2) = ARGIFY (arg2); \
TYPEFY (arg1, __arg1) = ARGIFY (arg1); \
register TYPEFY (arg6, _a6) asm ("r9") = __arg6; \
register TYPEFY (arg5, _a5) asm ("r8") = __arg5; \
register TYPEFY (arg4, _a4) asm ("r10") = __arg4; \
register TYPEFY (arg3, _a3) asm ("rdx") = __arg3; \
register TYPEFY (arg2, _a2) asm ("rsi") = __arg2; \
register TYPEFY (arg1, _a1) asm ("rdi") = __arg1; \
asm volatile ( \
"syscall\n\t" \
: "=a" (resultvar) \
: "0" (number), "r" (_a1), "r" (_a2), "r" (_a3), "r" (_a4), \
"r" (_a5), "r" (_a6) \
: "memory", REGISTERS_CLOBBERED_BY_SYSCALL); \
(long int) resultvar; \
})
|
API接口
在 syscalls_64.h 文件我们可以看到 Linux API 的系统调用号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
//linux/arch/x86/include/generated/asm/syscalls_64.h
__SYSCALL_COMMON(0, sys_read)
__SYSCALL_COMMON(1, sys_write)
__SYSCALL_COMMON(2, sys_open)
__SYSCALL_COMMON(3, sys_close)
__SYSCALL_COMMON(4, sys_newstat)
__SYSCALL_COMMON(5, sys_newfstat)
__SYSCALL_COMMON(6, sys_newlstat)
__SYSCALL_COMMON(7, sys_poll)
__SYSCALL_COMMON(8, sys_lseek)
//……
__SYSCALL_COMMON(435, sys_clone3)
__SYSCALL_COMMON(436, sys_close_range)
__SYSCALL_COMMON(437, sys_openat2)
__SYSCALL_COMMON(438, sys_pidfd_getfd)
__SYSCALL_COMMON(439, sys_faccessat2)
__SYSCALL_COMMON(440, sys_process_madvise)
//linux/arch/x86/include/generated/uapi/asm/unistd_64.h
#define __NR_read 0
#define __NR_write 1
#define __NR_open 2
#define __NR_close 3
#define __NR_stat 4
#define __NR_fstat 5
#define __NR_lstat 6
#define __NR_poll 7
#define __NR_lseek 8
//……
#define __NR_clone3 435
#define __NR_close_range 436
#define __NR_openat2 437
#define __NR_pidfd_getfd 438
#define __NR_faccessat2 439
#define __NR_process_madvise 440
#ifdef __KERNEL__
#define __NR_syscall_max 440
#endif
|
系统调用表
使用 sys_call_table 函数指针数组,存放所有的系统调用函数的地址,
通过数组下标就能索引到响应的系统调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
#define __SYSCALL_COMMON(nr, sym) __SYSCALL_64(nr, sym)
//第一次定义__SYSCALL_64
#define __SYSCALL_64(nr, sym) extern asmlinkage long sym(unsigned long, unsigned long, unsigned long, unsigned long, unsigned long, unsigned long) ;
#include <asm/syscalls_64.h>//第一次包含syscalls_64.h文件,其中的宏会被展开一次,例如__SYSCALL_COMMON(2, sys_open)会被展开成:
extern asmlinkage long sys_open(unsigned long, unsigned long, unsigned long, unsigned long, unsigned long, unsigned long) ;
这表示申明
//取消__SYSCALL_64定义
#undef __SYSCALL_64
//第二次重新定义__SYSCALL_64
#define __SYSCALL_64(nr, sym) [ nr ] = sym,
extern asmlinkage long sys_ni_syscall(unsigned long, unsigned long, unsigned long, unsigned long, unsigned long, unsigned long);
const sys_call_ptr_t sys_call_table[] ____cacheline_aligned = {
[0 ... __NR_syscall_max] = &sys_ni_syscall,//默认系统调用函数,什么都不干
#include <asm/syscalls_64.h>//包含前面生成文件
//第二次包含syscalls_64.h文件,其中的宏会被再展开一次,例如__SYSCALL_COMMON(2, sys_open)会被展开成:
[2] = sys_open, 用于初始化这个数组,即表示数组的第二个元素填入sys_open
};
int syscall_table_size = sizeof(sys_call_table);//系统调用表的大小
|
添加系统调用
我们以添加一个返回CPU数量的函数来说明如何添加系统调用。
- 下载内核源码
1
|
git clone git://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git/
|
- 申明系统调用
在 syscall_64.tbl 文件末尾添加 441 号指令,这个文件格式是四列,分别是
系统调用号、架构、服务名和服务入口函数。
1
2
3
4
5
6
7
8
|
//linux-5.10.13/arch/x86/entry/syscalls/syscall_64.tbl
0 common read sys_read
1 common write sys_write
2 common open sys_open
//……
440 common process_madvise sys_process_madvise
441 common get_cpus sys_get_cpus
|
- 定义系统调用
在 syscall.h 文件中使用 SYSCALL_DEFINE0 来定义
1
2
3
4
5
6
7
8
9
10
11
12
13
|
//linux-5.10.13/include/linux/syscalls.h
#ifndef SYSCALL_DEFINE0
#define SYSCALL_DEFINE0(sname) \
SYSCALL_METADATA(_##sname, 0); \
asmlinkage long sys_##sname(void); \
ALLOW_ERROR_INJECTION(sys_##sname, ERRNO); \
asmlinkage long sys_##sname(void)
#endif /* SYSCALL_DEFINE0 */
//linux-5.10.13/kernel/sys.c
SYSCALL_DEFINE0(get_cpus)
{
return num_present_cpus();//获取系统中有多少CPU
}
|
- 编译系统内核
1
2
3
4
5
6
7
8
|
# 配置内核
make menuconfig
# 先编译内核,再编译内核模块
make -j8 bzImage && make -j8 modules
# 先安装内核模块,再安装内核
sudo make modules_install && sudo make install
|
- 编写应用测试
1
2
3
4
5
6
7
8
9
10
|
#include <stdio.h>
#include <unistd.h>
#include <sys/syscall.h>
int main(int argc, char const *argv[])
{
//syscall就是根据系统调用号调用相应的系统调用
long cpus = syscall(441);
printf("cpu num is:%d\n", cpus);//输出结果
return 0;
}
|
第四十三讲 虚拟机内核
虚拟化
定义
虚拟化的本质是一个资源管理的技术,把计算机的实体资源(如 CPU、内存、网络等 )进行
转换和抽象,让这些资源重新分割、排列与组合,实现最大化使用物理资源的目的。
核心思想
在OS和硬件之间引入了一个叫 Hypervisor/Virtual Machine Monitor的层
KVM核心原理
要实现成功的虚拟化,核心是要对 CPU、内存 、I/O 进行虚拟化
CPU 虚拟化
Intel 定义了 Virtual Machine Extension (VMX)这个处理器特性,也就是传说中的
VT-x 指令集,开启这个特性之后 ,就会存在两种操作模式,分别是:跟操作(VMX root operation)和非根操作(VMX non-root operation)
前面说到的 Hypervisor/VMM,就是 运行在根操作模式下,对处理器和平台硬件有完全控制权限。
而虚拟机、应用程序等客户软件(Guest software)则运行在非根操作模式下,需要执行一些
特殊指令时会触发 VM-Exit 指令切回根操作模式。
内存虚拟化
内存虚拟化也借鉴了虚拟内存的思想,这样就又多了两种内存地址,共四种地址:
- 客户机虚拟地址 GVA (Guest Virtual Address)
- 客户机物理地址 GPA (Guest Physical Address)
- 宿主机虚拟地址 HVA (Host Virtual Address)
- 宿主机物理地址 HPA (Host Physical Address)
地址转换主要基于影子页表(Shadow Page Table),Intel 在硬件上设计了 EPT(Extended Page Tables),来提升内存地址转换效率。
I/O 虚拟化
I/O 虚拟化基于 Intel 的 VT-d 指令集来实现,这是一种基于北桥芯片的硬件辅助虚拟技术。
通过 VT-d 技术 ,虚拟机不用通过中间通道 ,使用基于直接 I/O 设备分配方式。
总结
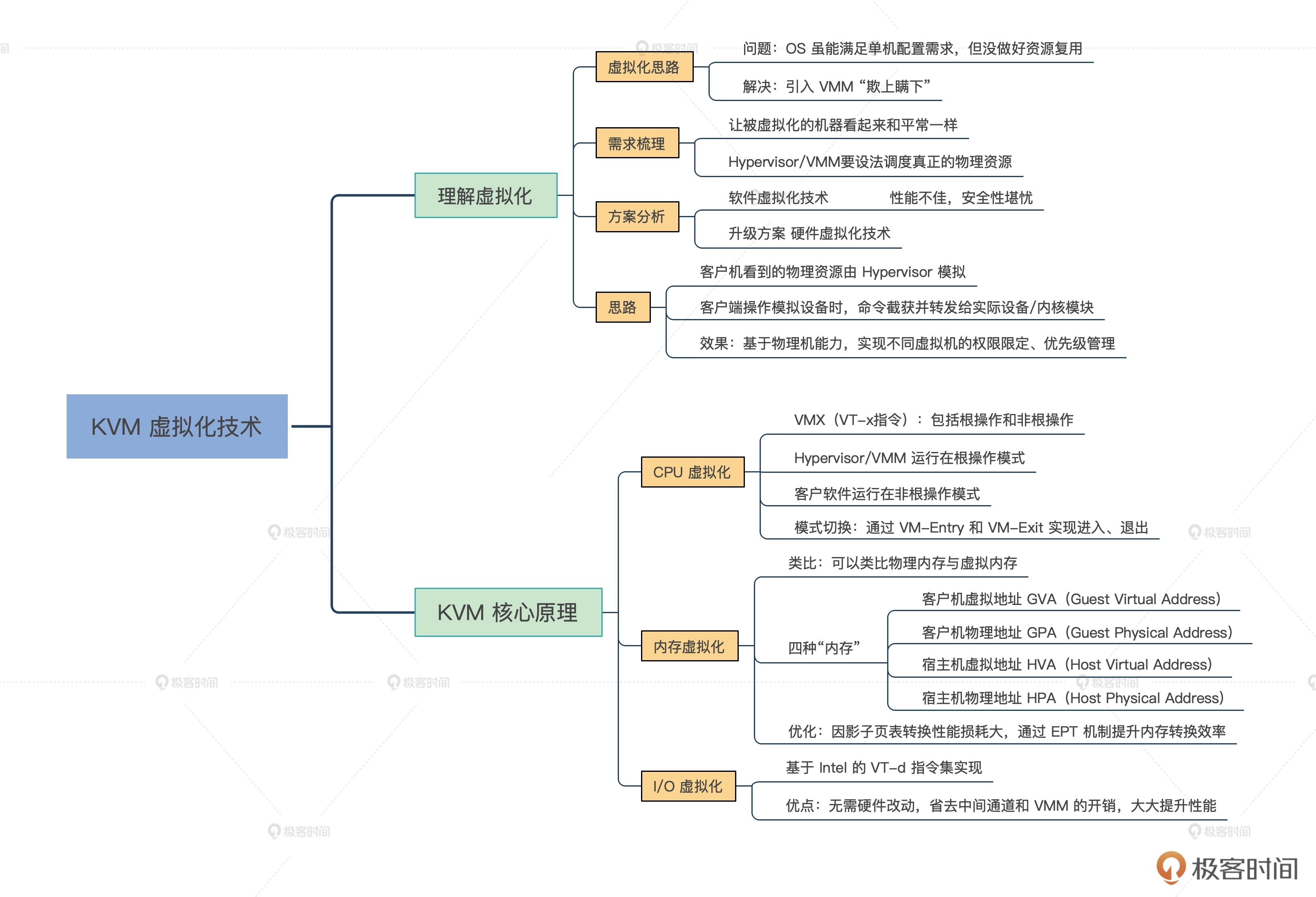
第四十四讲 容器实现机制
Docker 容器基础架构
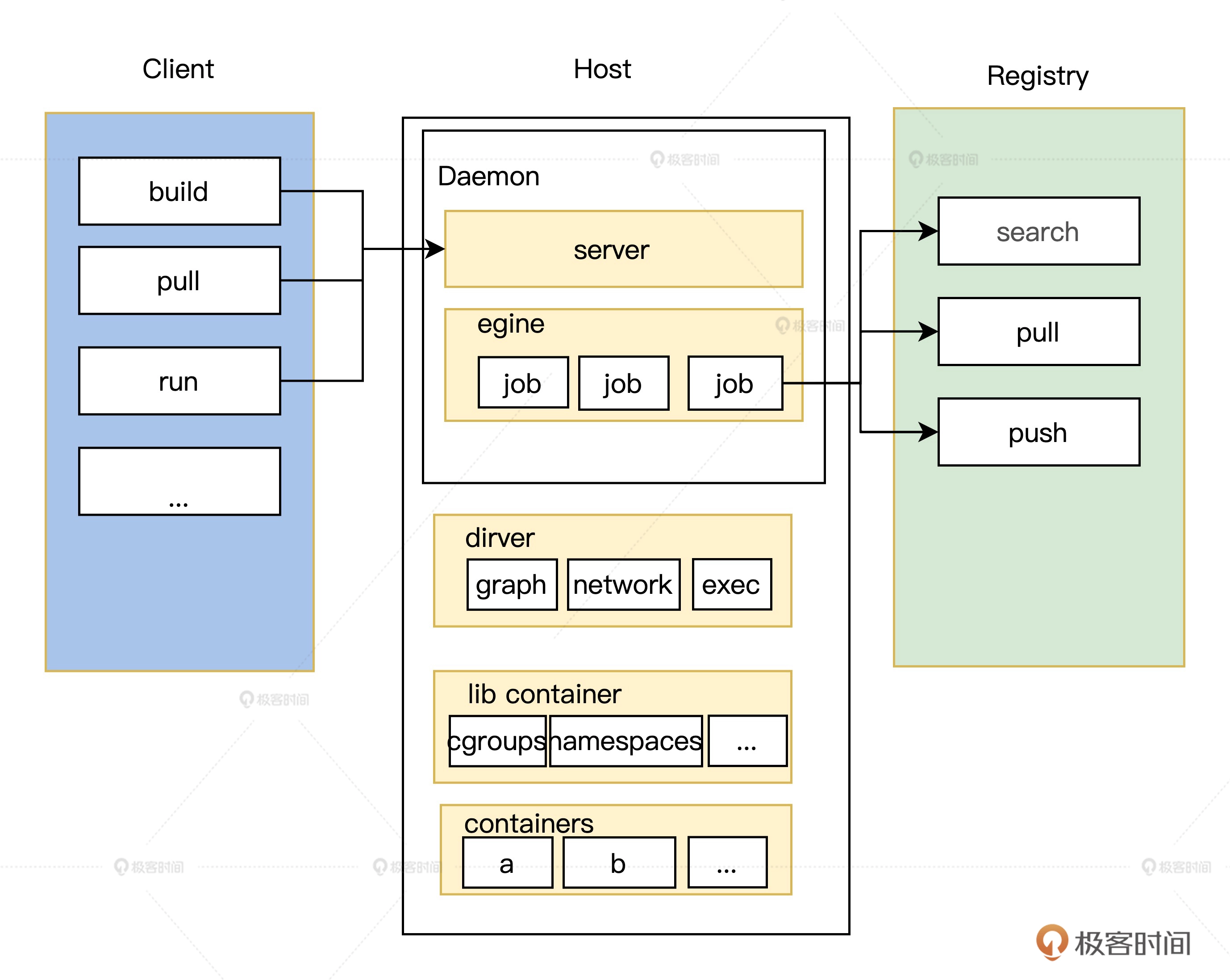
Docker 是最经典的容器技术,Docker应用是一种 C/S 架构,包括 3 个核心部分。
客户端 Client
客户端主要任务就是解析用户的操作指令和参数,通过 HTTP API 和 Docker 守护进程
交互,并将结果返回给用户。
镜像仓库 Registry
守护进程通过网络和 镜像仓库进行通信,如查询、下载、推送镜像等操作
镜像仓库可以部署在公网环境,也可以私有化部署到内网
管理引擎进程 Host
引擎进程是 Docker 架构的核心,包括运行 Docker Daemon(守护进程)、Image(镜像)、Driver(驱动)、Libcontainer (容器管理)等
Daemon
Daemon 负责监听客户端请求,然后执行后续的对应逻辑;还管理 Docker 对象(容器、镜像 、网络、磁盘)。
Daemon 分为三大部分:Server、Job、Engine。
Server 负责接收客户端请求,然后分发给相应 Handler 执行请求,最后将结果返回给客户端。
Engine 是运行引擎,执行的每一项工作,都可以拆分成多个最小动作 — Job。
Job 负责执行各项操作。
Driver
Driver 的作用是解耦,将镜像管理、网络和隔离执行逻辑从 Daemon 中剥离
- graphdriver 负责镜像管理
- networkdriver 负责网络环境配置
- execdriver 负责执行,通过操作 Lxc 或 libcontainer 实现资源隔离
libcontainer 提供了访问内核和容器相关的 API,负责对容器进行具体操作。
容器基础技术
Namespace
Namespace 实现了各种资源的隔离功能,具体如下表
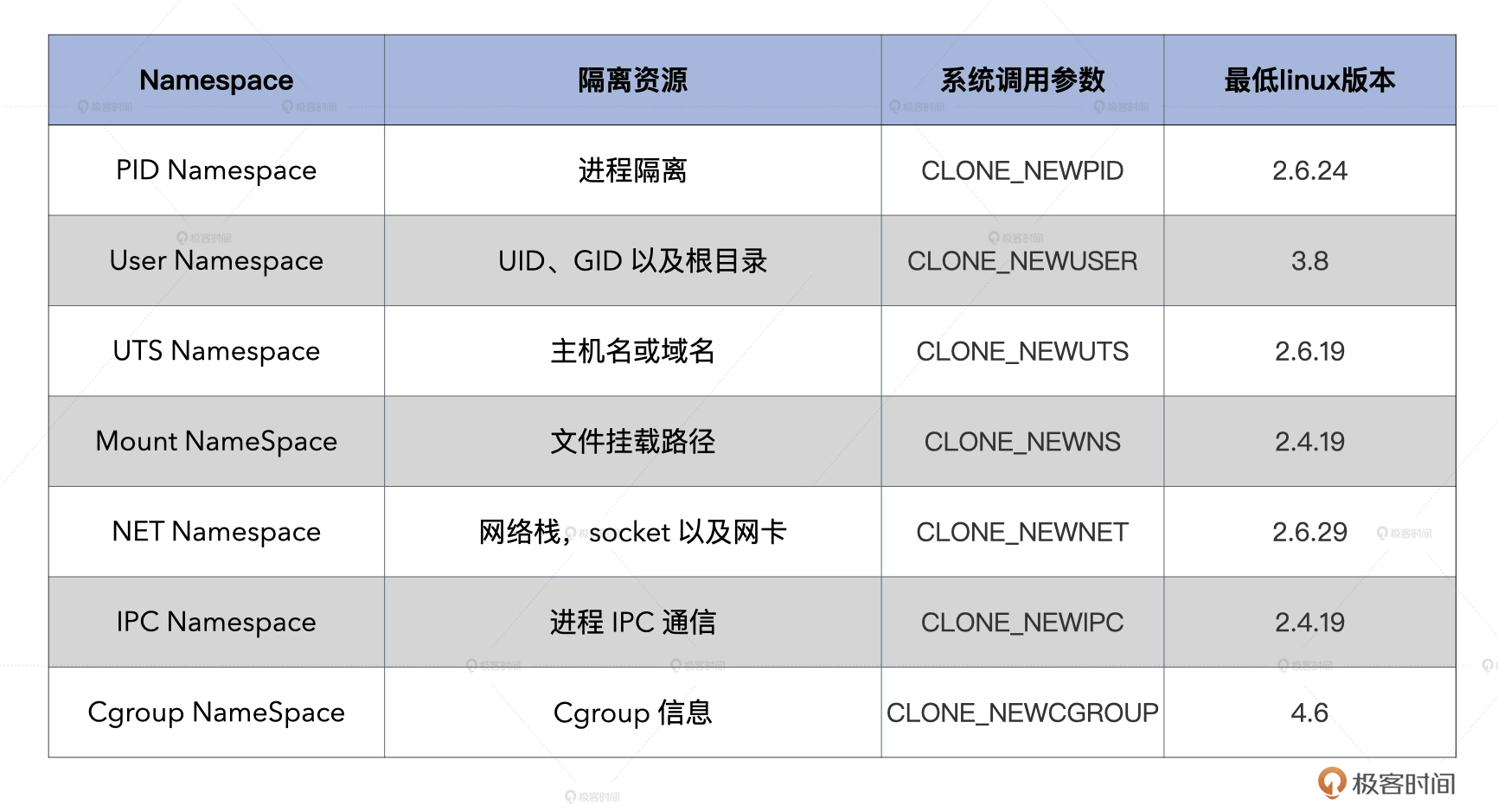
- PID Namespace: 用于进程隔离,每个容器都以 PID=1 的 init 进程来启动
- User Namespace: 用于隔离容器中 UID、GID、根目录等。在当前 Namespace下 ,用户是 root 权限的,但是在宿主机上,他还是那个用户。
- UTS Namespace: 用于主机名或域名隔离,每个容器有独立的主机名
- Mount Namespace: 用于隔离挂载路径。
- Net Namespace: 用于隔离网络资源,每个容器都已独立的网络设备
- IPC Namespace: 用于隔离 IPC 通信,只用在相同 IPC 命名空间的容器进程之间才可以共享内存、信号量
- Cgroup Namespace: 用于隔离 cgroup 视图
Namespace 主要用到 3 个系统调用函数
- clone: 用户创建新进程,根据传入的不同 Namespace 类型, 来创建不同的 NameSpace 来进行隔离,其子进程也会被包含到这些 Namespace 中
1
2
3
|
//flags就是标志用来描述你需要从父进程继承哪些资源,
//这里flags参数为将要创建的NameSpace类型,可以为一个或多个
int clone(int (*child_func)(void *), void *child_stac, int flags, void *arg);
|
- unshare: 将进程 移出指定类型的 Namespace,并加入到新创建的 Namespace 中
1
|
int unshare(int flags);
|
- setns: 将进程加入到 Namespace 中
1
2
3
|
//fd: 加入的NameSpace,指向/proc/[pid]/ns/目录里相应NameSpace对应的文件,
//nstype:NameSpace类型
int setns(int fd, int nstype);
|
Namespace 的主旨就是隔离容器的运行环境
Cgroups
Cgroups (Control Groups) 主要负责对指定的一组进程做资源限制,具体包括 CPU、内存、存储、I/O、网络等资源。
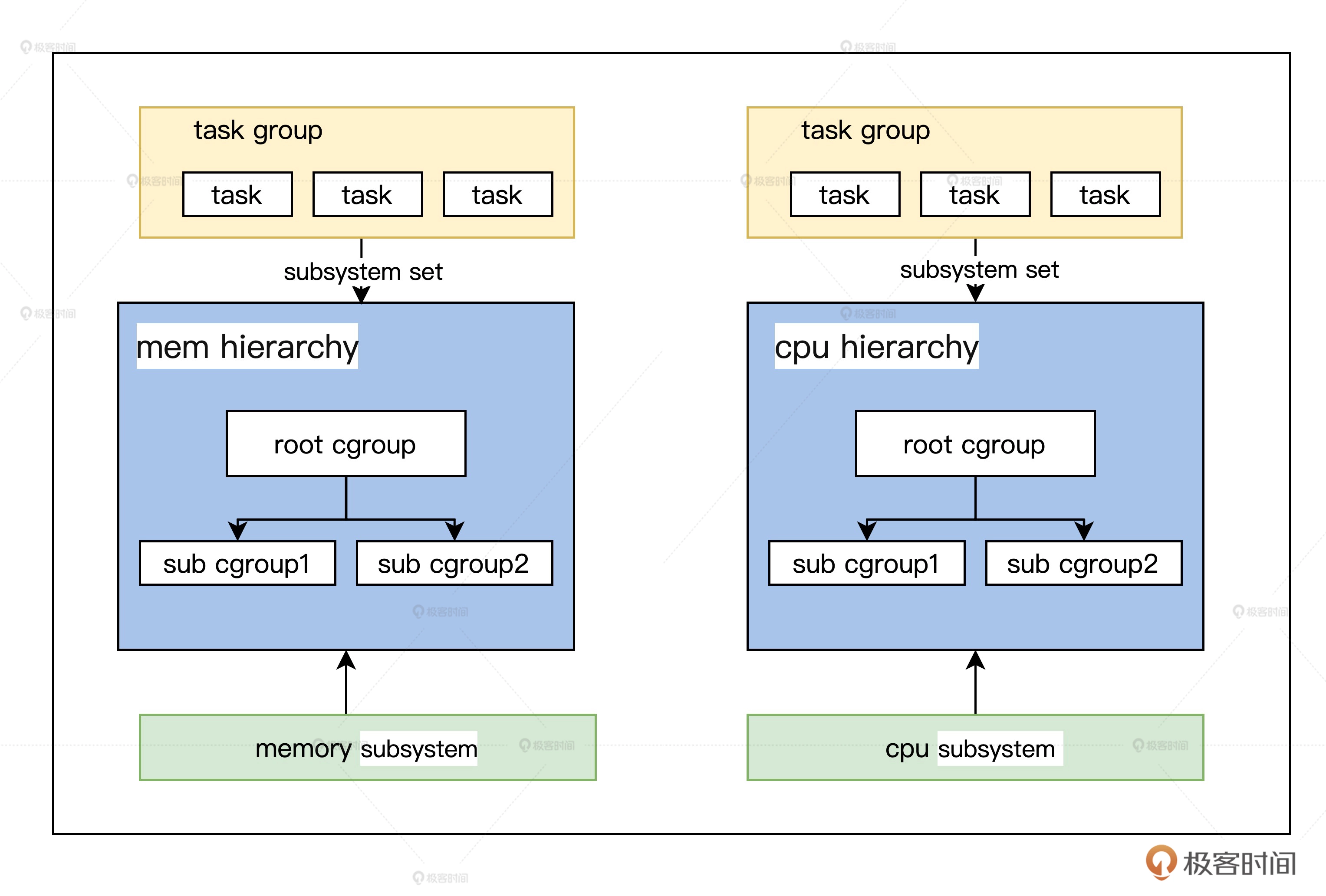
Task: 任务, 是 Cgroup 中的一个进程
hierarchy: Cgroups 层级树,将 Cgroup 通过 树状结构串起来,通过虚拟文件系统的方式暴露给用户。
subsystem: 子系统,是一组资源控制模块,控制资源占用。常用的子系统有 cpu group 、memory group 等。
第四十五讲 苹果 M1 芯片因何而快
CPU 原理初探
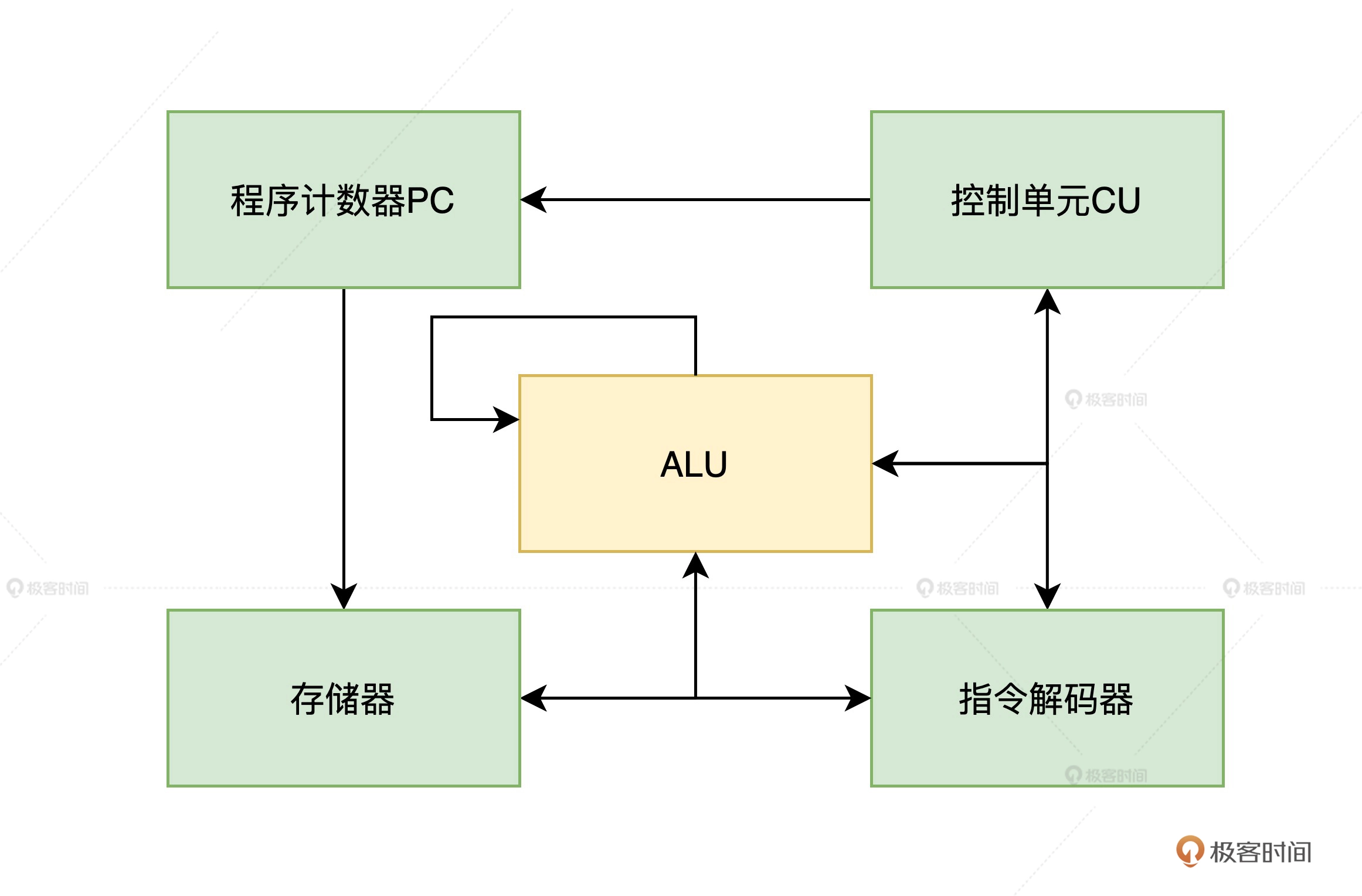
CPU 的运行过程可以抽象成这样 6 步:
- 首先从存储器中取出指令,这里把寄存器、RAM 统一抽象成了存储器
- 指令解码器解码指令
- 根据指令需要决定是否继续从存储器取数据
- 控制单元(CU)根据解指令决定要进行哪些计算,计算工作由算术逻辑单元(ALU)完成
- 控制单元(CU)根据解指令决定是否要将计算结果存入存储器
- 修改程序计算器(PC)的指针,为下一次取指令而做准备。
以上整体执行过程是由控制单元(CU)在时钟信号的驱动下,周而复始的有序运行。
ALU 的需求梳理和方案设计
我们可以使用 Verilog 语言来实现一个运行简单计算 ALU, 模块简图如下:
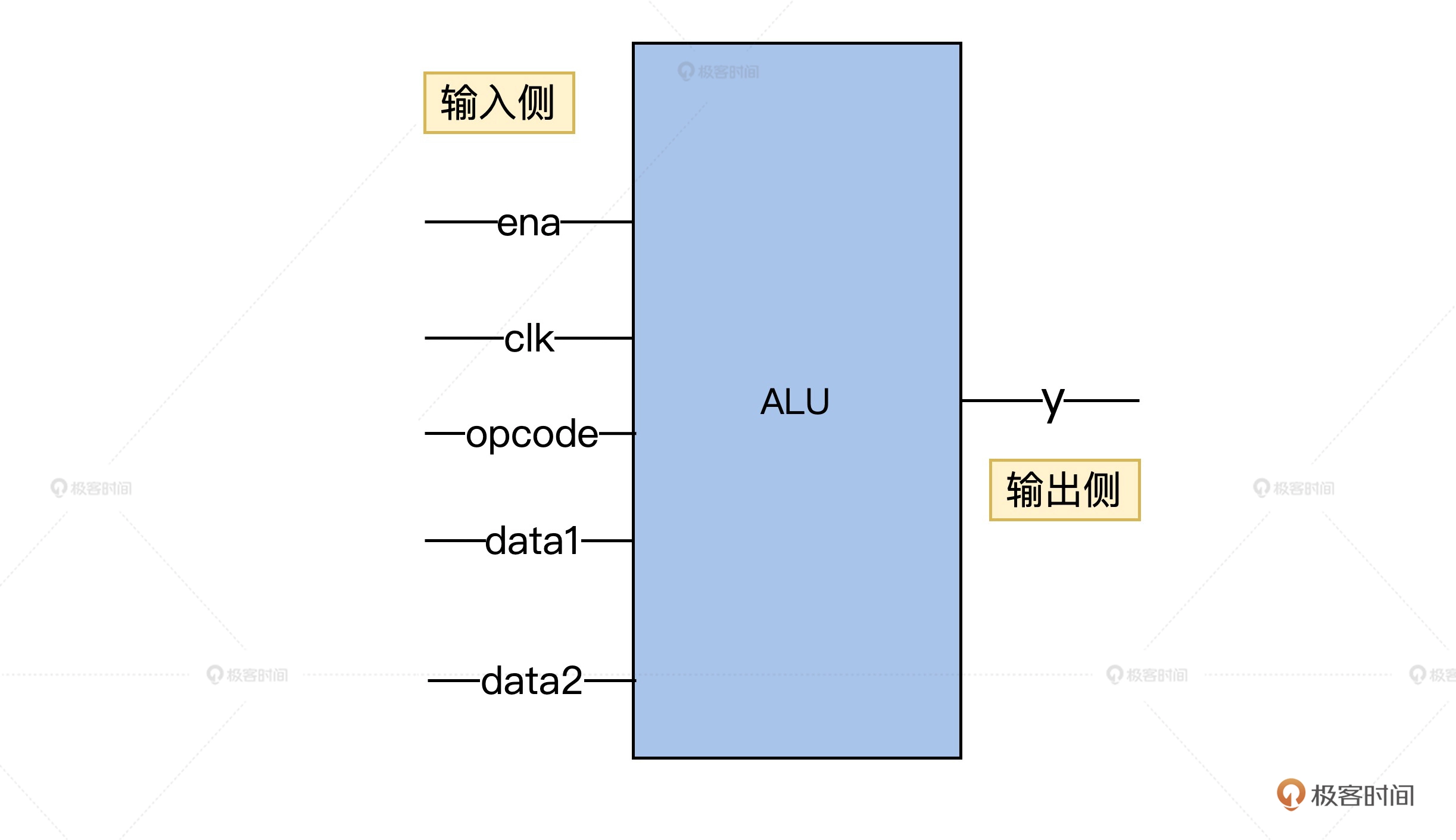
输入侧抽象出了五根引脚,作用分别是:
- ena: 使用信号,取值 0 和 1 分别代表 ALU 的关和开。
- clk: 时钟信号,时钟信号是 0 1 交替运行的方波。
- opcode: 操作码,取值 00、01、10 分别代表加、减、比较运算
- data1/2: 参与运算的两个数据
ALU 实现代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
/*----------------------------------------------------------------
Filename: alu.v
Function: 设计一个N位的ALU(实现两个N位有符号整数加 减 比较运算)
-----------------------------------------------------------------*/
module alu(ena, clk, opcode, data1, data2, y);
//定义alu位宽
parameter N = 32; //输入范围[-128, 127]
//定义输入输出端口
input ena, clk;
input [1 : 0] opcode;
input signed [N - 1 : 0] data1, data2; //输入有符号整数范围为[-128, 127]
output signed [N : 0] y; //输出范围有符号整数范围为[-255, 255]
//内部寄存器定义
reg signed [N : 0] y;
//状态编码
parameter ADD = 2'b00, SUB = 2'b01, COMPARE = 2'b10;
//逻辑实现
always@(posedge clk)
begin
if(ena)
begin
casex(opcode)
ADD: y <= data1 + data2; //实现有符号整数加运算
SUB: y <= data1 - data2; //实现有符号数减运算
COMPARE: y <= (data1 > data2) ? 1 : ((data1 == data2) ? 0 : 2); //data1 = data2 输出0; data1 > data2 输出1; data1 < data2 输出2;
default: y <= 0;
endcase
end
end
endmodule
|
现代 CPU 加速套路
更多硬件指令
现代 CPU 会实现更多硬件指令,这样能在一个时钟周期内实现更多的功能,从而提高效率。
缓存
现代 CPU 会在内部设计多级缓存,来提高指令读写速度
流水行乱序执行和分支预测
多核
超线程
指令集相关
CISC
Complex Instruction Set Computer 复杂指令集
RISC
Reduced Instruction Set Computer 精简指令集
ARM 和 M1 芯片
ARM 是 Advanced RISC Machine 的缩写。 ARM 公司制作指令集和 CPU 的设计,授权给厂商生产
M1 是 基于 ARM 架构的,并在其做优化
M1 中的解码器由 4 个增加到了 8 个,指令缓冲空间比常见 CPU 大了 3 倍。严格讲 M1 芯片
并不是 CPU,它集成了 CPU、GPU、IPU、DSP、NPU、IO控制器、网络模块、视频编解码器等
总结
参考