第一讲:一条SQL查询语句的执行过程
MySQL架构
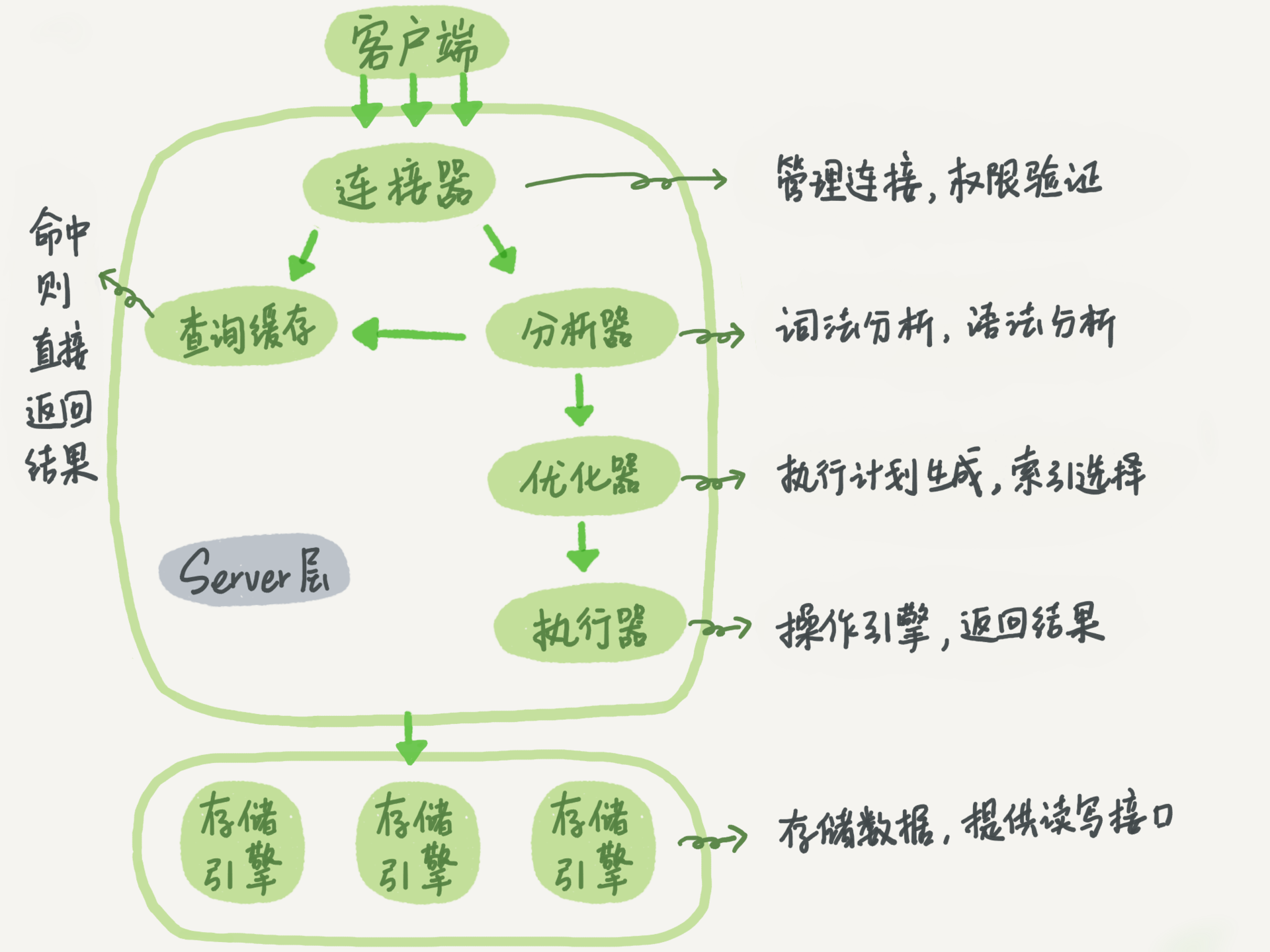
Server层
- 连接器: 管理连接,权限验证
- 分析器:词法分析,语法分析
- 优化器:索引选择,join顺序选择,执行计划制定
- 执行器:操作引擎返回结果
存储引擎层
- 负责数据的存储和提取
第二讲:一条SQL更新语句的执行过程
两种日志
- redo log: InnoDB引擎特有的的日志系统;大小固定,循环写;物理日志,记录的是数据页做的改动
- binlog: Server层的日志, 逻辑日志,记录的是sql语句的原始逻辑
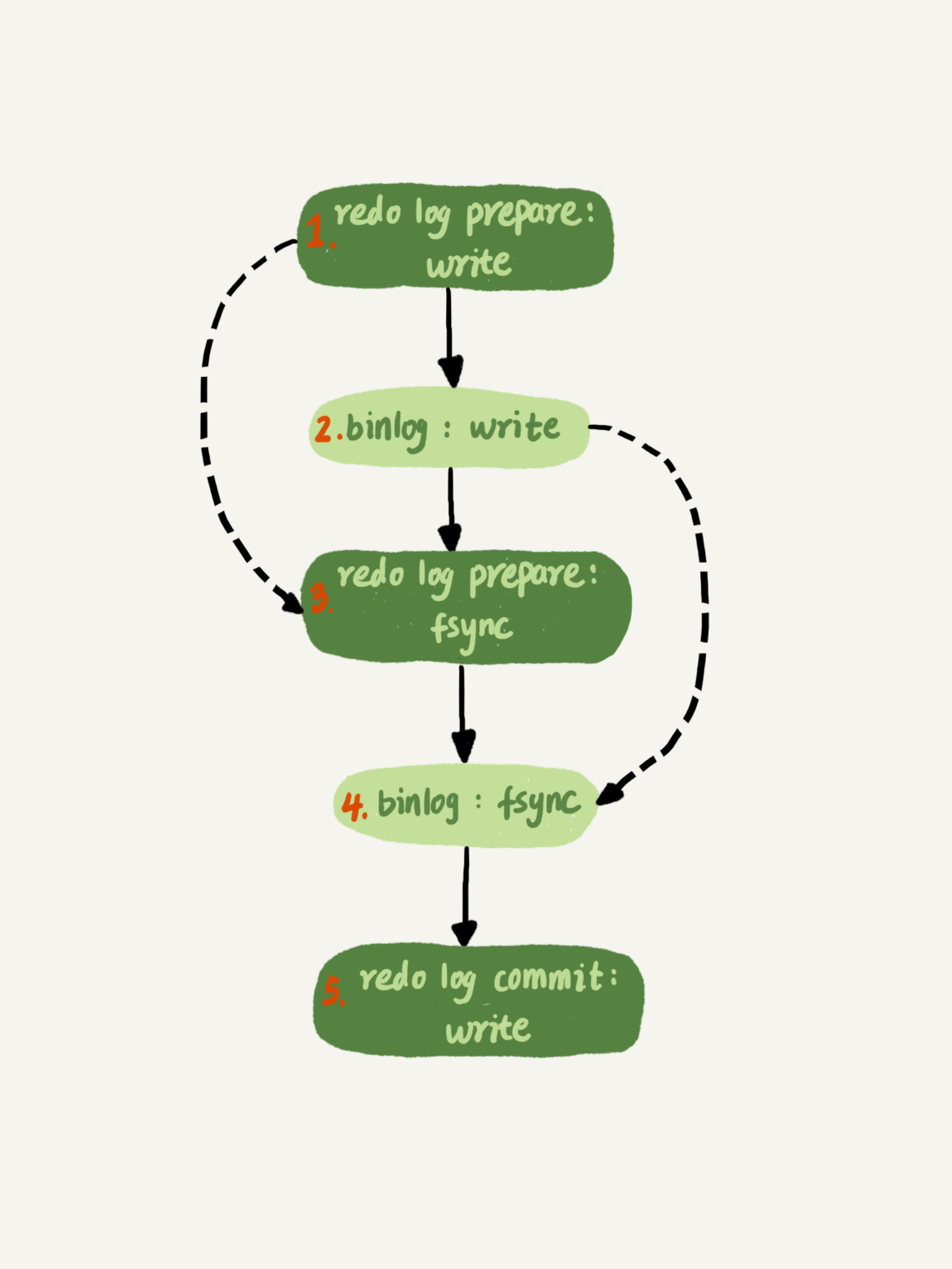
更新流程(浅绿色框表示在InnoDB内部执行)
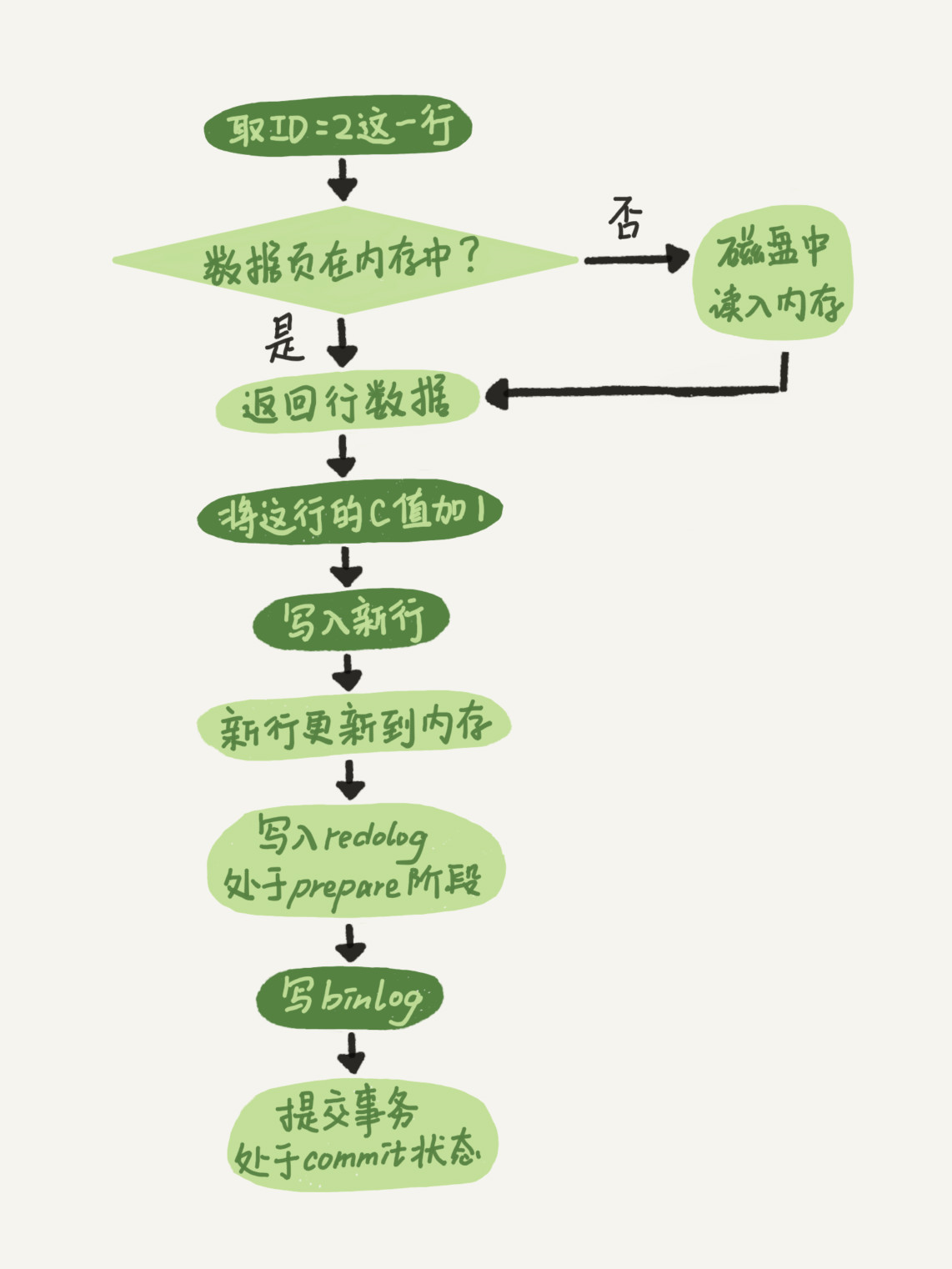
- redo log 两阶段提交
- 相关参数设定:
- innodb_flush_log_at_trx_commit=1表示每次事务的redo log 都持久化到磁盘
- sync_binlog=1表示每次的binlog都持久化到磁盘
第三讲:事务隔离
四种隔离级别
- 读未提交(read uncommitted):
- 事务还未提交时能被其他事务看到
- 读提交(read committed):
- 事务提交后才能被其他事务看到
- 可重复读(repeatable read)(默认选项):
- 事务执行过程中看到的数据和该事务启动时一致
- 串行化(serializable):
- 读写冲突的时候,后一个事务必须等前一个事务执行完成才能继续执行
示例
初始化
|
|
对于如下示例,在不同的隔离级别c1/c2/c3的结果分别是什么?
| 事务A | 事务B |
|---|---|
| start transaction; | |
| select * from t; | |
| start transaction; | |
| update t set c = c + 1 where c = 1; | |
select * from t;(c1) |
|
| commit; | |
select * from t;(c2) |
|
| commit; | |
select * from t;(c3) |
- read uncommitted : 均为2
- read committed : c1为1,c2/c3为2
- repeatable read : c1/c2为1, c3为2
- serializable : c1/c2为1, c3为2 (事务B update时阻塞)
底层实现逻辑
- “读未提交”隔离级别下直接返回记录上的最新值
- “串行化”隔离级别下直接用加锁的方式来避免并行访问
- “读已提交”事务在每次Read操作时,都会建立Read View
- “可重复读”在事务第一次Read时建立一个视图,整个事务存在期间都用这个视图,但是update操作时会读当前并更新视图
第四、五讲:索引
索引的常见模型
- 哈希表: 适合等值查询的场景
- 有序数组:适用于静态存储,等值查询和范围查询都适用
- 搜索树
InnoDB的B+索引模型
- 主键索引(clustered index):叶子节点存有整行数据
- 二级索引(secondary index): 叶子节点存有主键的值
索引维护
- 自增主键是追加操作,不会触发叶子节点的分裂
- 主键长度越小,二级索引的叶子节点就越小,更节省空间
- 数据页太小会加深层数,太大会增加加载时间和查询时间
重建表
alter table T engine=InnoDB 减少数据空洞
覆盖索引
所查询的数据在索引树上,无需再回表
最左前缀原则
索引(a, b)可用于查询条件有a或a和b的情况
索引下推
对索引中包含的字段先做判断, 减少回表次数,如查询 select * from table where name like "王%" and age = 10, 索引为(name, age),有索引下推时会对索引中的age做判断而非在回表后再判断
其他
- 主键为(a, b)的表索引c和索引(c, a)等价
第六讲:全局锁和表锁
全局锁
- 效果: 加上全局锁时整个服务处于只读状态
- 加锁命令:
|
|
- 典型使用场景:做全库逻辑备份
注:
-
对于使用InnoDB的库备份是可用
msyqldump --single-transaction -
全库只读也可用
set global readonly=true的方式,但这个对超级用户无效
表级锁
分类有2种: 表锁和元数据锁(MDL:meta data lock)
表锁
- 语法:
|
|
- 效果:
- 读锁:其他session写会阻塞,当前session不可写,不可访问其他表
- 写锁: 其他session读写都会阻塞,当前session不可以访问其他表
元数据MLD锁
-
获取: 自动获取
-
类型
- 读锁:增删改查操作
- 写锁:变更表结构
-
互斥性
- 读锁之间不互斥
- 读写锁之间、写写锁之间互斥,会发生阻塞
评论区拾遗
- OnlineDDL 过程
- 拿MDL写锁 (避免并发DDL)
- 降级成MDL读锁
- 真正做DDL
- 升级成MDL写锁
- 释放MDL锁
第七讲 行锁
行锁是由引擎层实现的,如MyISAM就不支持
两阶段
- 执行相应语句时加上,事务结束时释放
- 尽量将最可能锁冲突的的语句放在事务最后
死锁
- 参数innodb_lock_wait_timeout 锁超时, 默认50s
- 参数innodb_deadlock_detect,检测死锁,默认打开,复杂度O(n2),所以尽量控制并发事务量
- 死锁检测只会在阻塞时才会执行,只会检测依赖的事务
第八讲 视图
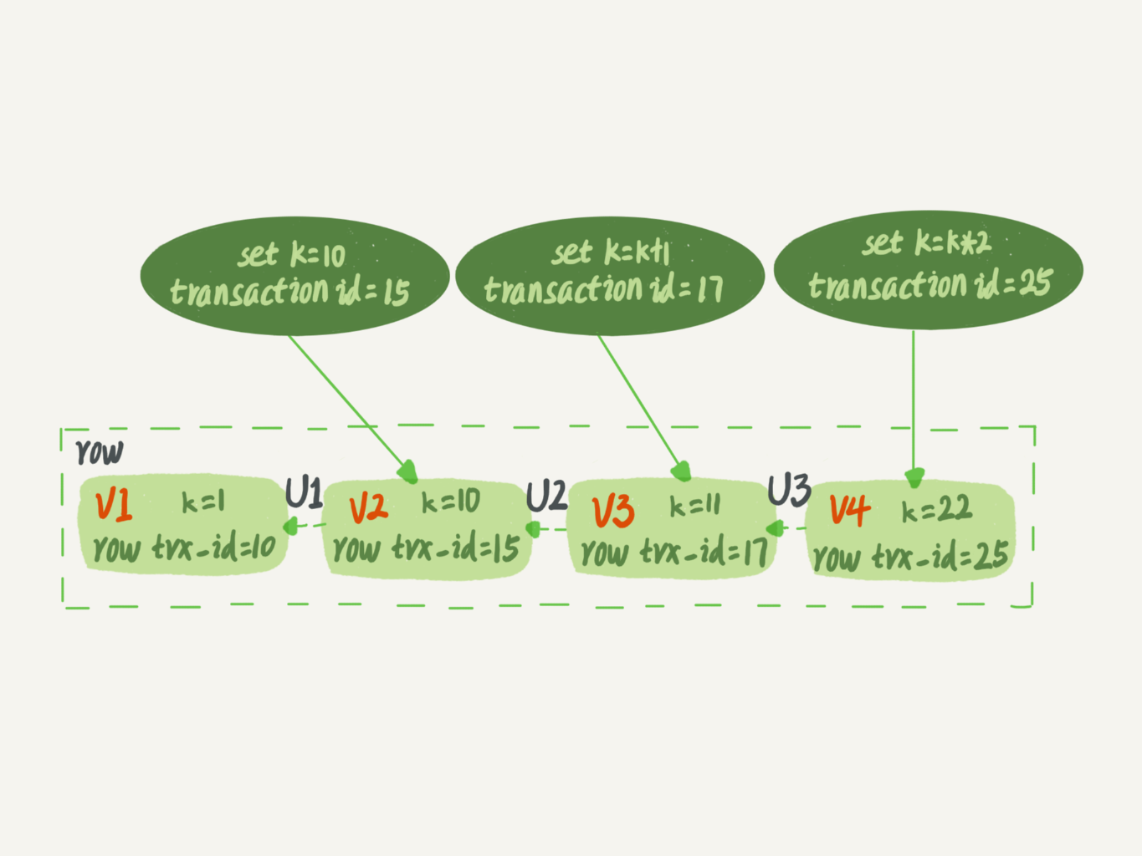
一致性读视图(consistent read view)
- 用于RC和RR隔离级别的实现
- begin/start transaction并不会马上启动事务,需要等到第一个执行操作才启动,显式启动可用start transaction with consistent snapshot
- 每行数据可能有多个版本,每个版本有自己的trx_id(即对应的事务id),旧的版本需要根据当前版本和undo log计算出了
- 更新数据都是先读后写,读指读当前的值(current read), 如果当前的记录的行锁被其他事务占用,就需要等待
- 读语句加上lock in share mode或for update 也是当前读
- 读提交隔离级别下,每个语句执行前都会重新算出一个视图
- 重复读隔离级别下, 第一个执行操作时会建立一个视图,后续复用这个视图
第九讲 唯一索引和普通索引的抉择
查询过程
- 数据按页读入内存,InnoDB默认页大小为16KB
更新过程
-
当数据在内存中时直接更新
-
当数据不在内存中, 将更新操作缓存在change buffer中,之后再merge, change buffer减少了随机磁盘访问
-
merge的流程
- 从磁盘读入数据页到内存
- 依次更新change buffer中相关记录
- 将内存数据的变更和change buffer的变更写入redo log
-
唯一索引需要将数据页读入内存中才能判断唯一性,故不能使用change buffer
-
对于普通索引,如果是写多读少的场景如日志系统,适合change buffer
-
change buffer用的是buffer pool里面的内存,innodb_change_buffer_max_size设置其百分比
-
redo log 会记录在内存数据页更新数据的操作和change buffer的操作;redo log 主要节省的是随机写磁盘的IO消耗,改为顺序写,而change buffer主要节省的是随机读存盘的IO消耗
-
change buffer的数据会持久化到ibdata系统表里,内存不足或checkpoint的时候会触发落盘
第十讲 Mysql为什么会选错索引
优化器选择索引的逻辑
采样统计预估扫描行情
-
方式:选择N个数据页,统计这些页面的不同值,得到一个平均值,然后乘以这个索引的页数,得到这个索引的基数cardinality,基数越大,表示区分度也好
-
更新: 当变更的数据行数超过1/M,会自动触发重新做索引统计
回表也会被优化器列入考虑因素
analyze table 来解决统计信息不准确的问题
选择异常和处理
- 使用force index
- 修改语句,引导MySQL使用我们期望的索引
- 新建更适合的索引或者删除多余的索引
评论区拾遗
- where a in (1,3) and b in (2, 4)会转换成 (a=1 and b=2) or (a=1 and b=4) or (a=3 and b=2) or (a=3 and b=4)
第十一讲 字符串索引
前缀索引
|
|
使用前缀索引,定义好长度,可以做到既省空间又不用额外增加太多的查询成本,使用前缀索引可能会损失区分度,需要预设一个可接受的比例
|
|
使用前缀索引用不上覆盖索引,对应字段只存了前缀部分
其他
- 如果前缀区分度比后缀区分度低,可倒序存储再建前缀索引提高区分度
- 可以增加一个int32字段存hash值
第十二讲 MySQL为什么会“抖动”
原因: flush刷脏页
触发场景:
- redo log写满了
- 系统内存不足
- Mysql空闲时
- Mysql正常关闭时
刷脏页策略控制
- innodb_io_capacity: 磁盘IO能力,可设成磁盘的IOPS,IOPS可用如下命令测试
|
|
- 刷盘速度参考因素: 脏页比例,redo log写盘速度
- innodb_max_dirty_pages_pct 脏页比例上限,默认值75%, 计算方式Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total
- innodb_flush_neighbors控制是否把相邻的脏页也顺便一起flush, MySQL8.0默认为0
- LSN(log sequence number)日志序号 可以用show engine innodb status 查看
第十三讲 表删除
表
- 参数innodb_file_per_table控制每个表是否单独存一个文件, 默认为on, 表数据存储在一个以.ibd为后缀的文件中,如果使用drop table, 会直接删除这个文件
行
- 删除数据时只是把对应数据标记为已删除,对应位置可以复用,符合范围条件的数据可以复用这个空间
- 如果整个数据页都标记为删除,可以复用到任何位置
- 如果相邻的两个数据页利用率都很小,系统会将数据合并到一个页,另外一个数据页被标记为可复用
- 如果用delete删除整个表,所有的数据页被标记为可复用,但文件不会变小
- 插入数据可能导致数据页分裂
重建表
- 重建表可以减少数据空洞(每个页留了1/16给后续的更新用): alter table A engine=InnoDB
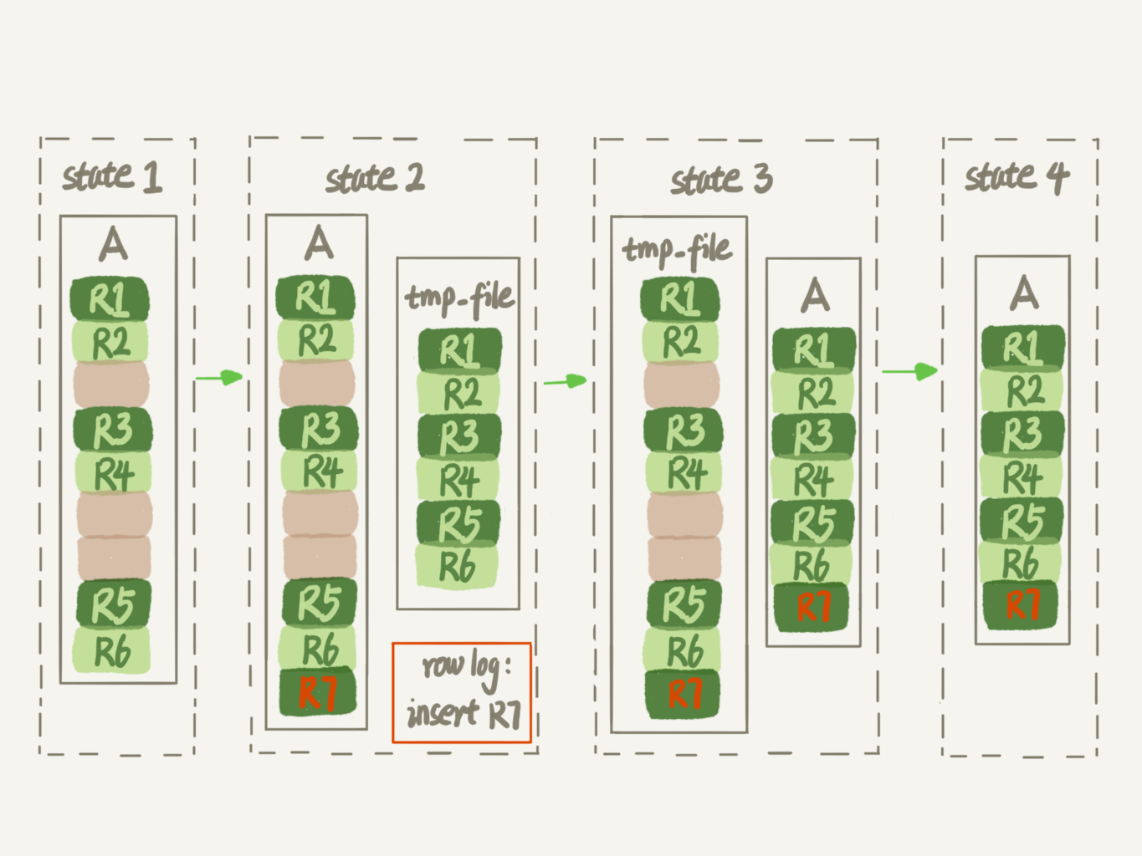
-
Online DDL(data definition Language)(5.6起重建表的默认流程)
- 建立一个临时文件,用原始表的记录生成B+树,存储到临时文件
- 同时把期间原始表的操作记录到一个日志文件中
- 临时文件生成后,将日志中的操作应用到到临时文件
- 用临时文件提花原始表的数据文件
-
optimize talbe = recreate table + analyze table(对索引信息做重新统计)
评论区拾遗
- truntace table t 等于 drop table + create table
- 重建表时数据页会按90%满的比例来重新整理页数据(10%留给UPDATE使用)
第十四讲 count(*)
实现方式
- MyISAM: 把表的总行数存在了磁盘,查询的时候直接返回这个数
- InnoDB:一行一行读取,累计计数
- show table status能取得估算的总行数
单独实现计数
- 存redis,高效
- 存mysql另一张表,持久化,可用事务保证一致性
不同count的区别
- count(1):引擎遍历整张表,但不取值
- count(id):引擎层遍历整张表逐行解析数据将id返回给server层,
- count(字段):引擎层遍历整张表逐行解析数据将对应字段值返回给server层
结论:count(字段)<count(主键 id)<count(1)≈count(*)
第十五讲 日志和索引相关问题答疑
日志相关
两阶段提交过程中crash
|
|
- 时刻A crash: binlog未写入,redo log未提交,事务会回滚
- 时刻B
- 如果binglog完整则提交事务
- binlog不完整则回滚
binlog如何验证完整性
- statement格式:最后会有comit
- row格式:最后会XID event
- 5.6.2版本之后还引入了binlog-checksum参数
redo log 和binlog如何关联
通过XID关联
奔溃恢复的时候,按顺序扫描redo log,如果既有prepare又有commit的redo log,就直接提交,如果没找commit,则拿XID找对应的binlog
redo log buffer
一个事务可能有多个操作,操作对应的red log先在redo log buffer中缓存,等执行commit时在写入文件
第十六讲 order by
using filesort表示需要排序,MySQL会给每个线程分配一块内存sort_buffer用于排序
全字段排序
把需要查询的字段一行一行查询出放入sort_buffer,再进行快速排序,如果要排序的数据量小于sort_buff_size,排序在内存中完成,否则会利用磁盘临时文件辅助排序,外部排序一般使用归并排序算法。
rowid排序
max_length_for_sort_data控制用于排序的行数据长度上限,如果超过这个值就只将排序用到的列和主键列放入sort_buffer,在排完序后再回表找到其他需要的字段. 所以会有两次访问主索引数
课后问题: sessionA 最后看到的A是多少
| sessionA | sessionB |
|---|---|
| start transaction; | |
| select * from t where id =1; (query result: a=3) | |
| update t set a = 5 where id = 1; | |
| update t set a = 5 where id = 1; | |
| select * from t where id =1; |
答: 取决于binlog_row_image,binlog_row_image=minimal时a=3,binlog_row_image=full为5。因为mysql在full时会读出所有字段,更新前会判断是否需要更新
第十七讲 随机消息
order by rand
rand是建一个临时表,每行给一个随机值(0, 1),然后在sort buffer中排序,内存中会用到快排,文件中会用归并排序
|
|
internal_tmp_disk_storage_engine控制临时表的类型,默认建内存临时表,如果超过了tmp_table_size就会转成磁盘临时表
随机排序法
- 方法一
|
|
- 方法二
|
|
第十八讲 隐式转换
-
函数:对字段做了函数操作,就用不上索引,因为可能会破坏索引值的有序性
-
隐式类型转化,字符串和数字做比较的话,是将字符串转换成数字
|
|
- 隐式字符编码转换
|
|
第十九讲 常见的阻塞场景
查询长时间不返回
- 等MDL锁
|
|
可以通过查询 sys.schema_table_lock_waits 这张表,我们就可以直接找出造成阻塞的 process id
- 等flush
|
|
- 等行锁
查询锁占用信息
|
|
查询慢
- 没有命中索引
- 一致性读时 undolog太多,回滚到对应版本耗时长,这种情况会比当前读慢(
lock in share mode)
第二十讲 幻读
- 幻读:一个事务,相同查询语句后一次查询看到了前一次查询没有看到的行。
- RR级别默认可重复读不会发生幻读,只有当前读(for update)才会出现幻读
- 行锁只能锁住行, 新插入记录可能是行之间的间隙。所以需要引入了间隙锁
- 间隙锁:锁住两个值之间的空隙, 间隙锁之间不存在冲突关系(即多个session可以锁同一个区间)
- 间隙锁和行锁合成next-key lock,每个next-key lock 都是前开后闭区间
- 间隙锁可能导致死锁,如下表,在id=9不存在的情况下,两个sesson会锁住间隙,insert时互相等待。
| sessionA | sessionB |
|---|---|
| begin; select * from t where id=9 for update | |
| begin; select * from t where id=9 for update | |
| insert into values(9,9,9) | |
| insert into values(9,9,9) |
- RC级别没有间隙锁,可能会出现数据和日志不一致的情况,binlog格式需要设为row
- 下表sessionA会加锁:
- next-key lock: (5, 10], (10, 15], (15, 20]
- gap lock: (20, 25)
| sessionA | sessionB | sesionC |
|---|---|---|
| begin; select * from t where c>=15 and c <=20 order by c desc for update | ||
| insert into values(11,11,11) | ||
| insert into values(9,9,9) |
第二十一讲
|
|
加锁规则
- 原则1:基本单位是next-key lock
- 原则2:查找过程中访问到的对象才会加锁
- 优化1:唯一索引的等值查询,给唯一索引加锁的时候,next-key lock会退化为行锁
- 优化2:索引的等值查询,向右遍历到最后一个值不满足等值条件时,next-ket lock会退化为间隙锁
- bug1: 唯一索引上的范围查询,会访问到不满足条件的第一个值为止
案例一 等值查询间隙锁
|
|
根据原则1和优化2,最终加锁范围是(5, 10)
案例二 非唯一索引等值锁
|
|
- 根据原则1、原则2和优化2,最终加锁范围是(0, 5],(5, 10),因为使用可覆盖索引,所以主键索引上没有锁。
- lock in share mode 只锁覆盖索引,但是如果是 for update 就不一样了。 执行 for update 时,系统会认为你接下来要更新数据,因此会顺便给主键索引上满足条件的行加上行锁。你要用 lock in share mode 来给行加读锁避免数据被更新的话,就必须得绕过覆盖索引的优化,在查询字段中加入索引中不存在的字段。
案例三 主键索引范围锁
|
|
首次定位查找id=10是按等值查询判断,之后范围判断,最终加锁是是行锁10,next-key lock (10, 15]
案例四 非唯一索引范围锁
|
|
根据原则1 (5, 10], (10, 15]
案例五 唯一索引范围的bug
|
|
根据原则1和bug1: (10, 15], (25, 20]
案例六 limit语句加锁
|
|
因为有limit加锁区间为(5, 10]
案例七 死锁案例
| sessionA | sessionB |
|---|---|
| begin; select * from t where id=10 lock in share mode; | |
| update t set d=d+1 where c=10;(blocked) | |
| insert into values(9,9,9); | |
| ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction |
sessionA开始加上了(5,10],(10,15), insert导致sessionB死锁说明,session加上了gap lock (5, 10),即next-lock加锁是分两步(加间隙锁和加行锁)执行的,间隙锁不是排他的而行锁是
案例八
| sessionA | sessionB |
|---|---|
| begin; select * from t where c>=15 and c <=20 order by c desc lock in share mode; | |
| insert into values(6,6,6); |
- c: (5, 25)
- id: 15 ,20
第二十二讲 饮鸩止渴的方法
max_connectio超标
方案一 清理空闲的线程
- 清理空闲的线程 kill connction $thread_id
- 查看事务详情: select * from information_schema.innodb_trx
方案二 减少连接过程的消耗
- 重启数据库 使用–skip-grant-tables参数启动,这样连接过程和语句执行过程都会跳过权限验证阶段,mysql8.0之后默认吃屎只能本地客户端连接,提高安全性
慢查询
索引没有设成好
- 5.6之后可以在线DDL: alter table add index
语句没有写好
- 查询重写
|
|
MySQL选错索引
- 使用force index
第二十三讲 MySQL如何保证数据不丢
binlog的写入机制
- binlog先写入binlog cache,每个线程都有独立的cache, 事务提交的时候再写到binlog中
- 一个事务的binlog是是一次性写入的,如果超过了binlog_cache_size,会用到临时文件
- 参数sync_binlog控制写入机制
- 0,只write(写入文件系统page cache)
- 1, 每次都fsync,持久化到磁盘
- n, 积累n个事务才fsync(通常n为100~1000之间)
- binlog_group_commit_sync_delay 参数 表示延迟n微秒后fysync, 判断顺序会先判断参数sync_binlog,满足后才会对该参数判断
- binlog_group_commit_sync_no_delay_count 积累n次后才调用fsync,和上一个参数是或的关系
redo log写入机制
- 同样也有三种状态,在redo log buffer中、page cache 中、 磁盘中
- innodb_flush_log_at_trx_commit参数
- 0, 写入redog buffer
- 1, 每次都持久化到磁盘
- 2, 只write到page cache
- InnoDB后台线程会每隔一秒将buffer中的日志调用write和fsync持久到磁盘
- 组提交(group commit): fsync的时候会将当前所有事务一起fsync
第二十四讲 MySQL如何保证主从一致
从库同步逻辑
- io_thread负责和主库建立长连接,接收主库发送过来的binlog, 并写入本地文件relay log
- sql_thread读取relay log,并执行
- binlog中有server id信息,如果发现server id和自己一样,就会丢弃,这样避免了双Master架构循环写入的问题
binlog
三种格式
- statement SQL原始语句
- row 记录具体操作和主键id以及其他字段的值
- mixed(上面两种格式混合)
格式优缺点
- statement可能导致主备不一致(如删除操作主从库选择的索引可能不一样)
- row格式占用空间大
- mixed MySQL自己判断SQL语句是否会引起主备不一致,如有可能就用row格式,否则用statement格式
- mixed格式中使用了now函数的语句会用statements格式,因为binlog记录了上下文
SET TIMESTAMP=xxxxxxx
部分操作命令
- show variables like ‘%log-bin%’ 查看binlog是否打开
- show binlog events in ’master.000001‘ 查看binlog
- mysqlbinlog -v data/master.000001 -start-position=100 查看binlog 详细信息
第二十五讲 MySQL如何保证高可用
主备延迟
-
定义 指的是同一个事务,在备库执行完成的时间和主库执行完成的时间的差值,如下面的
T1-T3T1: 主库执行完成一个事务,写入binlog T2: 备库B接收完这个binlog T3: 备库B执行完成这个事务 -
seconds_behinds_master 表出差当前备注延迟了多少秒
- 可用
show slave status查看 - 计算方式: binlog中有一个字段记录了主库写入时间,这个时间和备库当前系统时间的差值
- 备库连接到主库时会通过
SELECT UNIX_TIMESTAMP()获取主库的系统时间,计算seconds_behind_master会自动扣掉系统时间的差值
- 可用
延迟引入的原因
- 备库服务器性能不如主库
- 备库查询压力大
- 大事务
主备切换(可靠性优先)
- 等待seconds_behind_master小于某个阈值(如5s)
- 将主库改为只读,即设置readonly=true
- 等待seconds_behind_master变为0
- 将备注改成可读写状态,即设置readonly=false
- 将写入请求切换到备库
主备切换(可用性优先)
可能出现数据不一致的情况
第二十六讲 备库为什么会延迟好几个小时
并行复制策略
-
由一个sql_thread变成一个coordinator+多个work线程
-
coordinator分发规则
- 同一个事务放到同一个worker
- 涉及同一行数据的事务放到同一个workder
-
Mysql5.6开始持DB级别的并行复制
-
MariaD支持 commid_id相同(组提交)的binlog并行复制
-
MySQL5.7 通过slave-parallel-type参数控制并行复制策略
- DATABASE: DB级别的并行复制
- LOGICAL_CLOCK: 同时处于prepare或commit状态的日志可以并行复制
-
MySQL5.7.22新增了binlog-transaction-dependency-tracking参数
- COMMIT_ORDER 同上
- WRITESET: 事务涉及的每一行,计算出hash值,组成writeset, 如果两个事务没有操作相同的行,及它们的writeset没有交集,就可以并行
- WRITE_SESSION:在WRITESET的基础上添加一个约束:主库上同一个线程先后执行的两个事务,从库上也保证先后执行
第二十七讲 主库出问题了,从库怎么办
-
一主多备切换时发成冲突
- 主动跳过错误
set global sql_slave_skip_counter=1 - 忽略常见的错误(唯一键冲突,删数据到不到行):slave_skip_errors 设置为 “1032,1062”
- 主动跳过错误
-
使用GTID (global transaction identifier)
- 全局事务ID,提交的时候生成,是事务的唯一标识
- 格式
server_uuid:gno, server_uuid是实例第一次启动时自动生成的,gno是一个整数,初始值是1,每次提交事务的时候分配给这个事务并加1 - 开启: 实例启动时加上参数gtid_mode=on 和 enforce_gtid_consistency=on
第二十八讲 读写分离有那些坑
常用读写分离方案
- 客户端主动选择主库还是备库进行查询。
- 加入中间代理层proxy, proxy根据请求分发路由
常用处理过期度的方案
方案一 判断主备无延迟
- show slave status
- 查看seconds_behind_master是否==0
- 对比位点Read_Master_Log_Pos和Exec_Master_Log_Pos
- 对比GTID集合Retrieved_Gtid_Set和Executed_Gtid_Set
- 配合semi-sync: 主库收到一个从库binlog的ack后才会提交事务
方案二 等主库位点
|
|
- 参数 file 和 pos 指的是主库上的文件名和位置, timeout 可选
- 正常返回的结果是一个正整数, 等待超过N秒,就返回-1, 开始执行的时候,就发现已经执行过这个位置了,则返回0, 备库同步线程发生异常,则返回NULL
- 所以>=0, 从库读, 否则走主库

方案三 等GTID
|
|
- 超时返回1,等到从库执行的事务包含传入的gtid_set返回0
- MySQL 5.7.6 版本开始,允许在执行完更新类事务后,把这个事务的GTID返回给客户端,可以通过mysql_session_track_get_first获取
第29讲 如何判断数据库是否出问题了
select 1
-
select 1只能说明进程还在,并不能说明主库没问题 -
反例
| session1 | session2 |
|---|---|
| set global innodb_thread_concurrency=1; (设置并发查询上限为1) | |
| select sleep(100) from t; | |
| select 1; (Query OK) | |
| select * from t; (blocked) |
查表判断
select * from db.health_check
- 磁盘满后,binlog无法写入,更新操作会被堵住,但读操作仍可正常进行
更新判断
- 版本1
update mysql.health_check set t_modified=now(); 这个情况不是和双M架构,双M同时发起检测的话可能会冲突 - 版本2
insert into mysql.health_check(id, t_modified) values (&&server_id, now()) on duplicate key update t_modified=now();
内部统计
外部检测具有随机性,可能不能及时发现问题, Mysql5.6之后提供了performance_schema库,file_summary_by_event_name统计了每次IO请求的时间。
使用redo log
开启监控
|
|
查看
|
|
- COUNT_STAR: 所有IO的总次数, 后4列分别是总和,最小值,平均值,最大值,单位是皮秒
- COUNT_READ 读操作
- COUNT_WRITE 写操作
- COUNT_MISC 其他
使用bin log
|
|
检测
检测单次IO请求时间是否超过200毫秒
|
|
清空数据
|
|
第30讲 用动态的观点看加锁
不等号条件里面的等值查询
|
|
加锁范围(0, 5], (5, 10], (10, 15)
15没有锁因为树搜索开始定位记录时用的是等值查询,优化器找第一个id<12的值时找到了(10, 15)这个间隙
等值查询的过程
|
|
加锁过程
- c=5:(0, 5], (5, 10)
- c=10: (5, 10], (10, 15)
- c=20: (15, 20], (20, 25)
|
|
加锁过程
- c=20: (15, 20], (20, 25)
- c=10: (5, 10], (10, 15)
- c=5:(0, 5], (5, 10)
查看死锁
|
|
- lock_mode X waiting表示next-key lock;
- lock_mode X locks rec but not gap是只有行锁;
- 还有一种 “locks gap before rec”,就是只有间隙锁;
锁范围变化
| session1 | session2 |
|---|---|
| begin;select * from t where id>10 and id<=15; | |
| delete from t where id=10; (Query OK) | |
| insert into i valus(10, 10, 10); (blocked) |
delete操作导致两个间隙锁(5, 10), (10, 15)变成了一个(5,15), 其实所谓间隙就是间隙右边的那个记录定义的。
| session1 | session2 |
|---|---|
| begin;select c from t where id>5 lock in share mode; | |
| update t set c = 1 where id=5 ; (Query OK) | |
| update t set c = 5 where c = 1; (blocked) |
(5,10]、(10,15]、(15,20]、(20,25]和 (25,supremum] 变成了(1,10]、(10,15]、(15,20]、(20,25]和 (25,supremum]
评论收集
评论1
|
|
- 先定位索引c上最右边c=20的行,所以第一个等值查询会扫描到c=25
- 然后通过优化2,next-key lock退化为间隙锁,则会加上间隙锁(20,25)
- 紧接着再向左遍历,会加 next-key lock (15, 20], (10, 15], 因为要扫描到c=10才停下来,所以也会加next-key lock (5,10]
第31讲 删除数据除了跑路还能怎么办
删除行
- 修改binlog然后回放,前提是binlog_format为row和binlog_row_image=FULL
删表/库
- 近期备份+binlog
- 使用延迟从库
评论收集
评论1
对生产数据库操作,公司DBA提出的编写脚本方法,个人觉得还是值得分享,虽说可能大部分公司也可能有这样的规范。修改生产的数据,或者添加索引优化,都要先写好四个脚本:备份脚本、执行脚本、验证脚本和回滚脚本。备份脚本是对需要变更的数据备份到一张表中,固定需要操作的数据行,以便误操作或业务要求进行回滚;执行脚本就是对数据变更的脚本,为防Update错数据,一般连备份表进行Update操作;验证脚本是验证数据变更或影响行数是否达到预期要求效果;回滚脚本就是将数据回滚到修改前的状态。虽说分四步骤写脚本可能会比较繁琐,但是这能够很大程度避免数据误操作。
第32讲 为何有kill不掉的语句
两个kill命令
kill query thread_id: 将session 的运行状态改为 THD::KILL_QUERY,并发信号给执行线程,表示终止这个线程正在执行的语句kill thread_id: 将session 的运行状态改为 THD::KILL_CONNECION并断开执行线程网络连接, 并发信号给执行线程
kill无效的情况
- 线程状态虽然改了,但线程还没有执行到判断线程状态的逻辑
- 终止逻辑比较长,如大事务被kill时回滚也比较耗时,某些操作用到的临时文件,删除临时文件也可能受到IO资源的影响耗时较久
客户端ctrl+c
此时客户端会另起一个连接发一个kill query
第33讲 查太多数据,内存会不会打爆?
- MySQL是边读边发的,如果state一直处于
sending to client,表示服务器端的socket send buffer写满了 - MySQL进入执行阶段后,state会置于
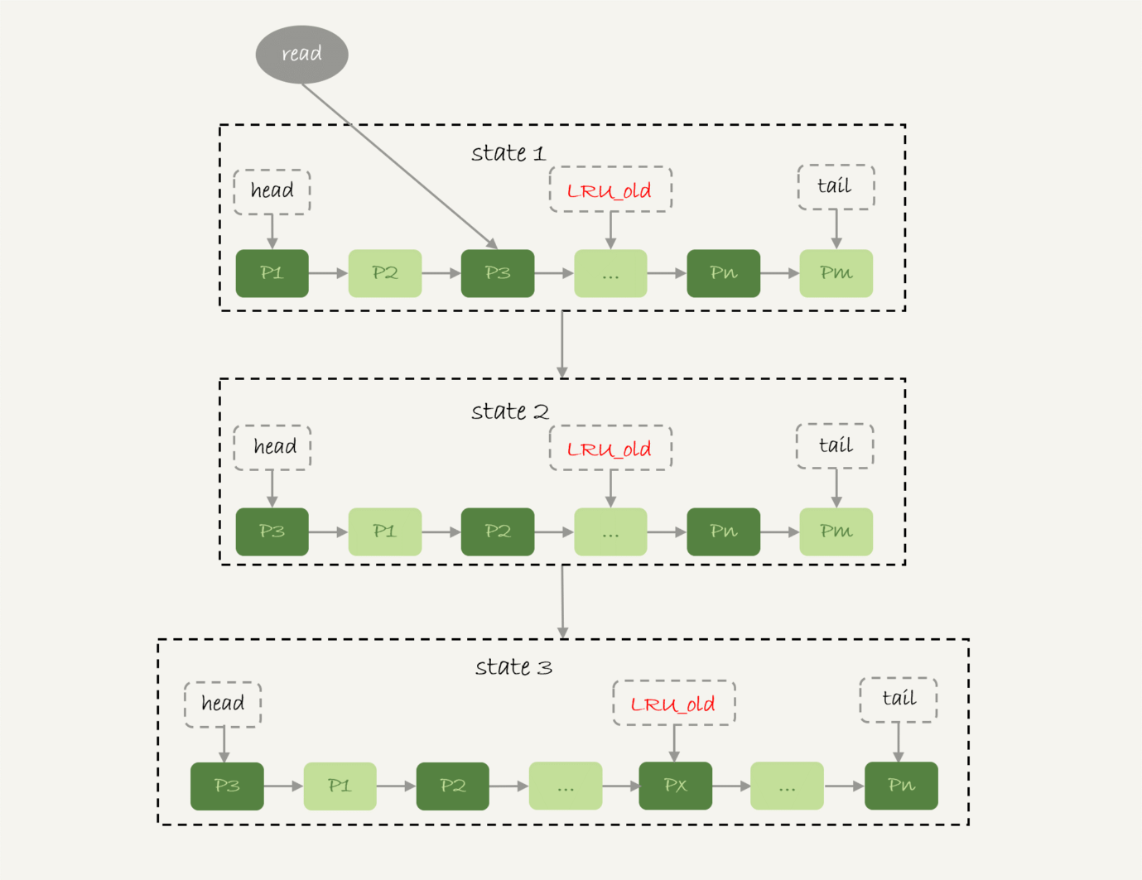
sending data - 由于Innodb对于LRU算法的改进,冷数据的全表扫描不会影响到buffer pool的查询命中率
- 按5:3的比例把整个链表分成了young区域和old区域,前5/8为young区域
- LRU_old指针指向old区域第一个位置
- 新插入的数据页先放在LRU_old处
- 访问old区域的数据页时,如果存在的时间超过了1s,则将其移动至整个链表的头部
第34讲 可不可以用join
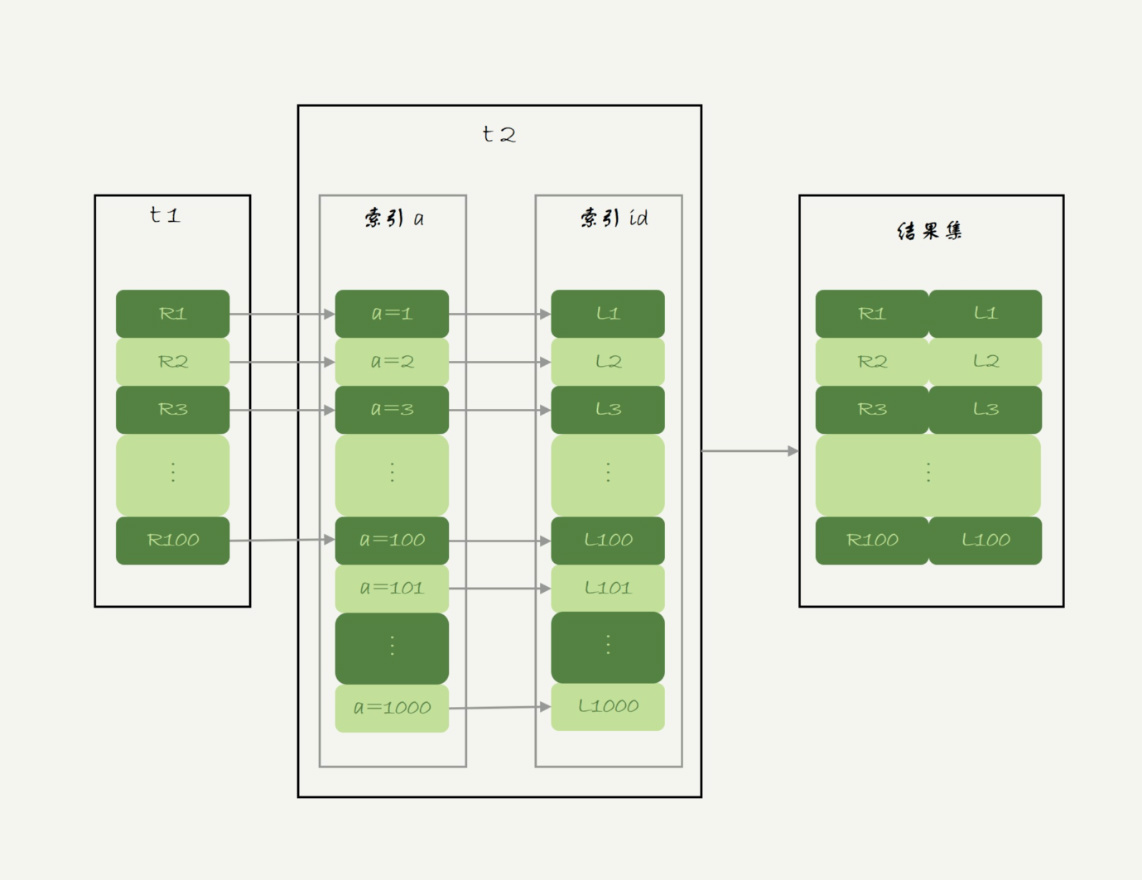
Index Nested-Loop Join
被驱动表能使用索引
|
|
- straight_join 关闭优化器优化,这样t1必定为驱动表,t2必定为被驱动表
- 执行流程
- 从表t1读出一行数据R
- 从R中找出a到t2中查找
- 取出t2中满足条件的行,和R组合,作为结果集的一部分
- 重复1~3
- join的复杂度 假设被驱动表的行数是M,搜索树的复杂度为log2M,走两次索引,则查询一行的时间复杂度为2*log2M,驱动表的行数为N,整合执行过程的复杂度是N+N*2*log2M (2倍是因为需要回表) 这种情况显然驱动表的行数N对复杂度的影响更大
Simple Nested-Loop Join
被驱动表没有索引,每次匹配一行都要全表扫描
|
|
- join复杂度
- 扫描行数 N + N*M
- 判断次数 N*M
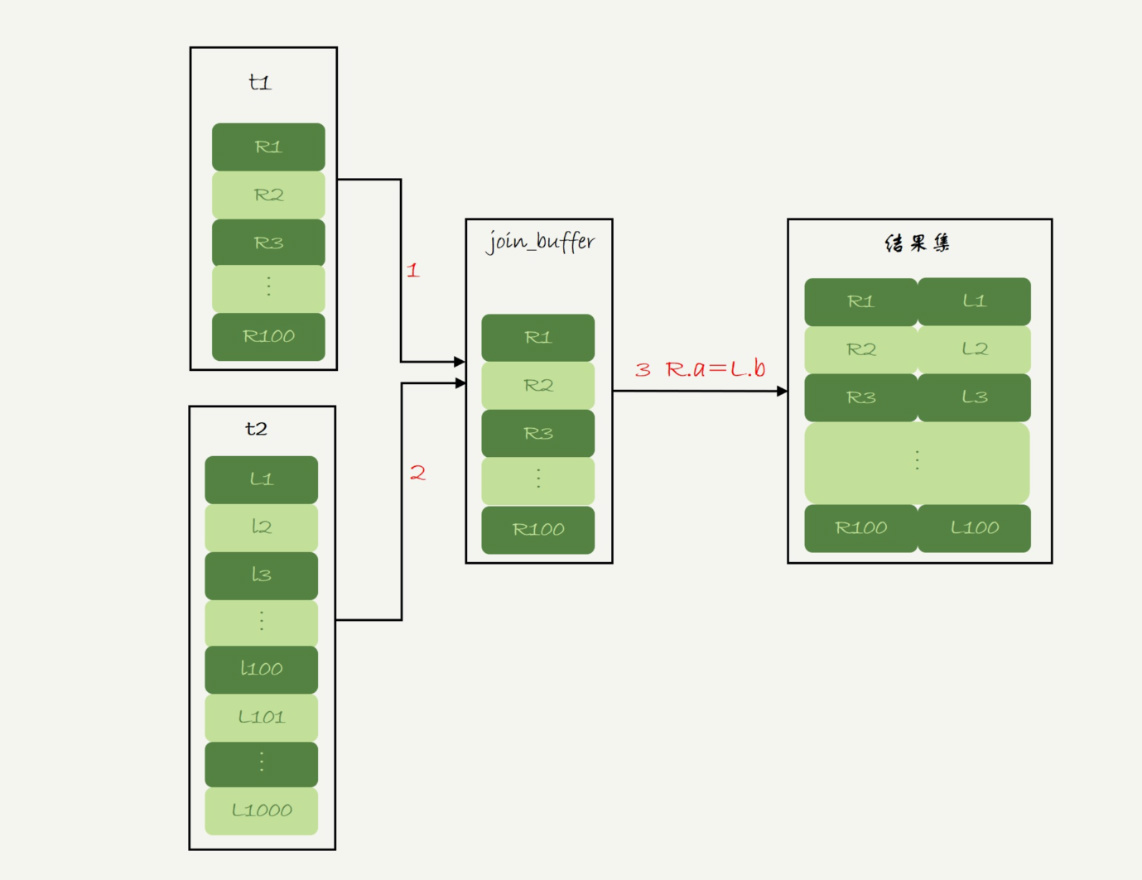
Block Nested-Loop Join
被驱动表没有索引,但将驱动表的数据载入join_buffer中
- 执行流程
- 将驱动表的数据读入join_buffer(如果buffer满了会分批加载)
- 扫描被启动表,按行取出和join_buffer中的数据对比,满足条件的作为结果集的一部分返回
- join复杂度
- 扫描行数 N + M(如果join_buffer只能一次只能加载一半数据,则扫描行数为 N + 2*M)
- 判断次数 N*M
结论
- 能用Index-Nested-Loop Join时可以使用
- 尽量不用Block Nested-Loop Join算法,尤其在大表上的join
- Index Nested-Loopp Join 应该选择小表做驱动
- Block Nested-Loop Join在join buffer够大的情况下没有影响,否则应该选小表做驱动
- 小表是以按条件过滤之后参与join的数数据量做判断
案例
|
|
应该选t2做驱动表,这样只需再出50条数据
|
|
应该选t1做驱动表,只需要放一个字段b,而t2需要三个字段id, a, b
第35讲 join优化
基础表
|
|
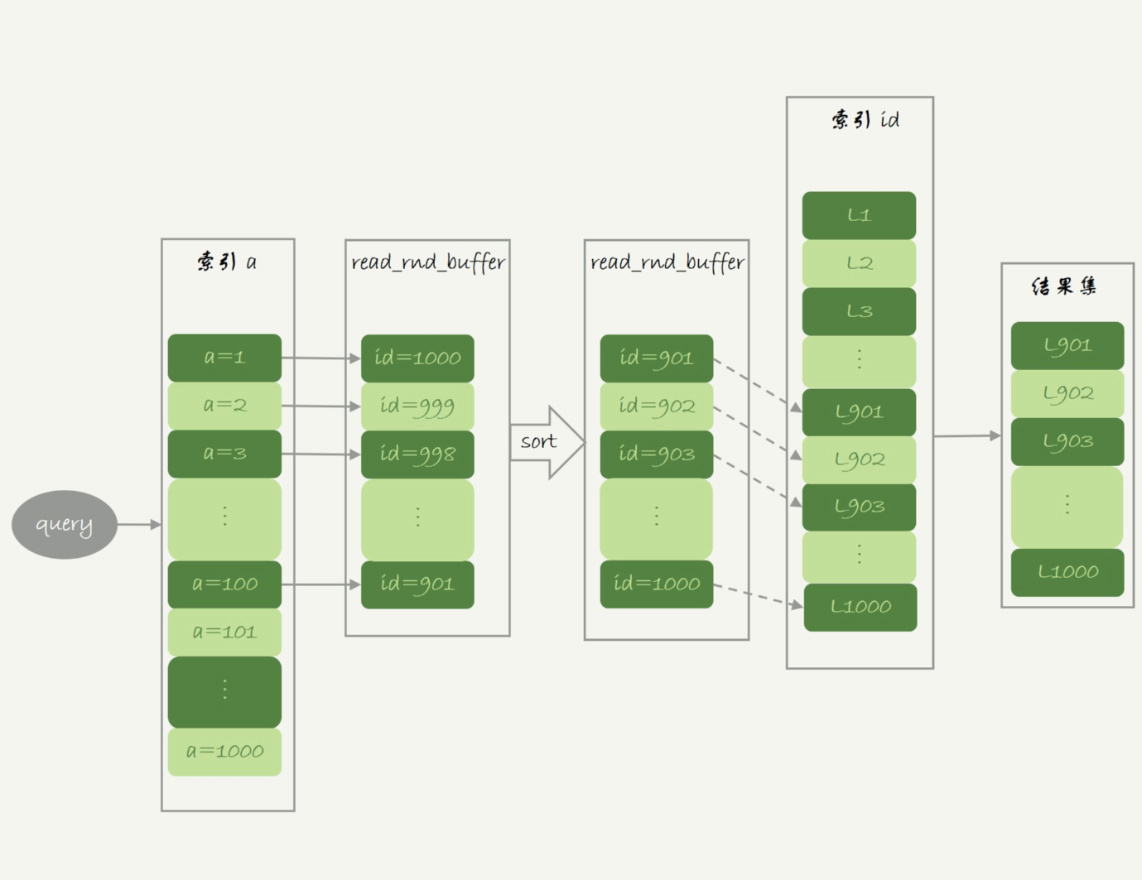
Multi-Range Read优化
|
|
- 回表的时候将id值先放入read_rnd_buffer中,排序后再依次查数据,按主键递增顺序查询,对磁盘的读比较接近顺序读,能够提升读性能。
- 通过设置
set optimizer_switch="mrr_cost_based=off"开启
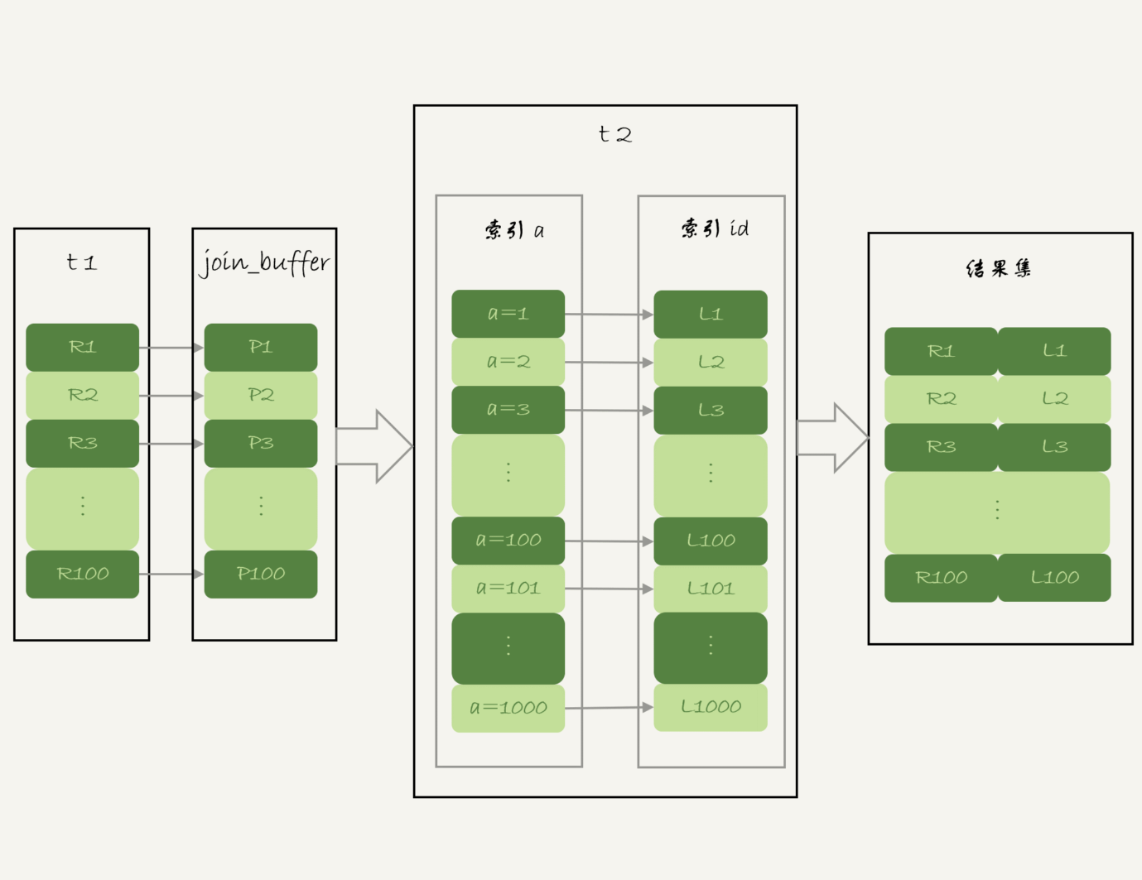
Batched Key Access(BKA)
BKA是对 Index Nested-Loop Join(NLJ)的优化: 将驱动表的数据缓存存到join_buffer中, 一次性的将数据传给被驱动表取匹配
开启
|
|
BNL性能问题
- 可能会多次扫描被驱动表,占用磁盘IO
- join需要执行M*N次对比,占用CPU
- 影响buffer pool的命中率
- 如果数据量小于buffer pool的3/8(即能完全放入old区域),多次扫描可能导致数据进入lru的头部
- 如果数据量很大,正常的业务数据可能没有机会进入young区,因为可能old区域的数据在1s内就被完全淘汰了
BNL转BKA
如果合适在被驱动表上建索引,可以直接建索引转BKA
如果被驱动表不合适建索引,如下情况
|
|
- 可以通过建立和被驱动表同结构临时表tmp_t,且给字段b加上索引,然后满足条件的数据放入临时表
|
|
- 也可以业务端模拟hash join: 将t1的1000行数据放入hash set,然后将满足条件的2000行数据依次取去hash set中匹配
第36讲 为什么临时表可以重名
临时表不一定是内存表
- 内存表指的engine=memory的表,数据保存在内存中,表结构保存在磁盘
- 临时表可以使用各种engine
临时表的特性
| session A | session B |
|---|---|
| create temporary table t(c int)engine=myisam; | |
| show create table t; // table ’t’ doesn’t exist | |
| create table t(id int primary key)engine=innodb;show tables; | |
| insert into values(1); select * from t; //返回1 | |
| select * from t // Empty set |
- 创建语法:
create temporary table - 临时表只能被创建它的session可见
- 临时表可以和普通表同名,同名时show create table语句和增删改查访问的是临时表
- show tables不显示临时表
- session结束时会自动删除临时表
应用
- 分库分表的场景:先建立临时表,每个表的执行结果插入临时表,最后在临时表执行查询语句即可
为什么临时表可以重名
- 表结构存在临时目录(select @@tmpdir), 文件命名格式为
#sql{procees_id:hex}_{thread_id}_num.frm - table_def_key在库名+表名的基础上,又加上了“server_id+thread_id”
- 每个线程维护了一个临时表链表,对表进行操作时,会先遍历链表,没有找到才会找普通表;session结束的时候会对链表中的临时表进行drop temppory table
主备复制
- 如果 binlog_format=row, 和临时表有关的语句不会记录
- 备库创建临时表时table_def_key会加上thread_id信息,避免主库不同session建立同名的临时表时冲突
第37讲 什么时候会使用内部临时表
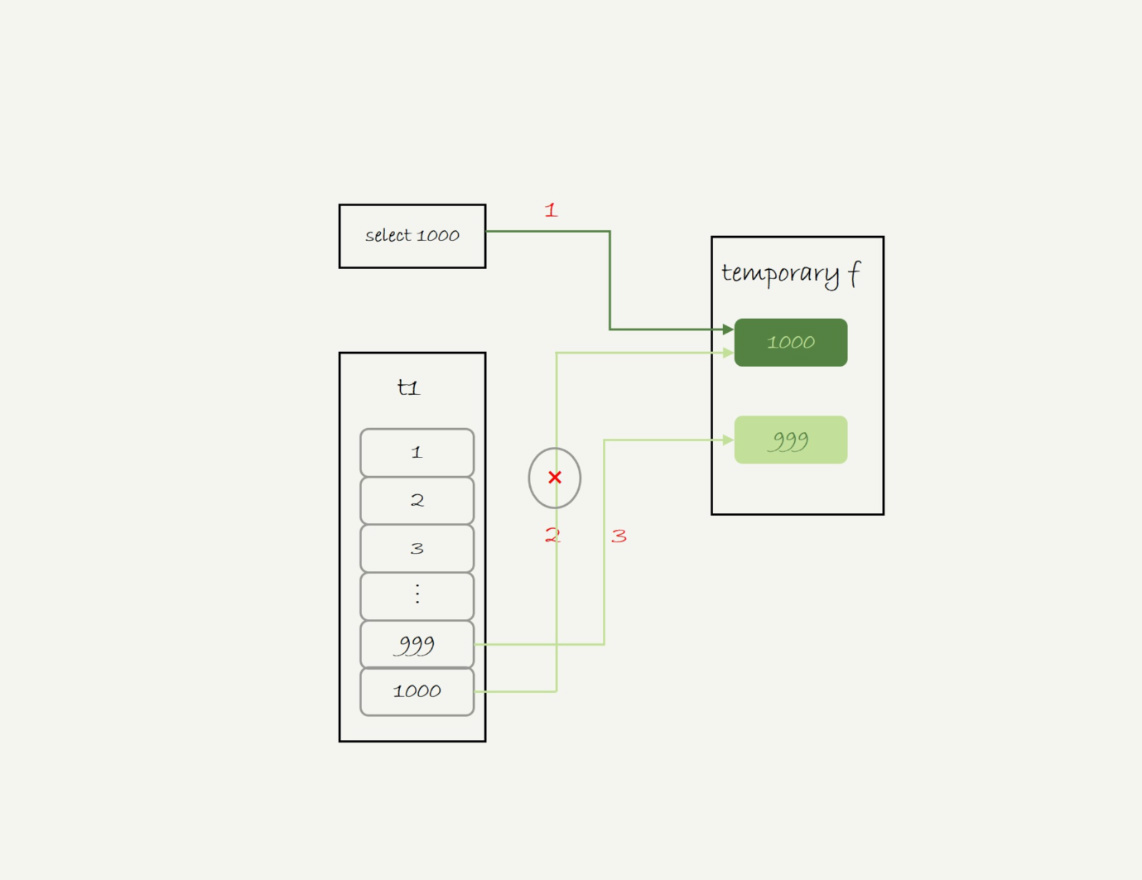
union执行流程
|
|
- 创建内存临时表,该表只有一个字段f,且为主键
- 执行第一个子查询,得到1000这个值,并存入临时表
- 执行第二个子查询:
- 拿到第一行id=1000, 试图插入临时表,但由于1000这个值已经存在于临时表,违反了唯一性约束,所以插入失败,然后继续执行
- 取到第二行id=999, 插入临时表成功
- 从临时表中按行取出数据,返回结果,并删除临时表
注:如果改成union all,就没有了去重的语义,所以不需要临时表
group by执行流程
|
|
从Extra信息中可以看出:使用了覆盖索引a,使用了临时表,使用了filesort
- 创建临时表,表里有两个字段m和c, 主键是m;
- 扫描表t1的索引a,依次取出叶子节点的id值,计算id%10的结果,记为x:
- 如果x不存在,则插入一个记录(x, 1)
- 否则将x这一行的c值加1
- 根据字段m进行排序,然后返回给客户端
如果不需要排序可以加上order by null
如果执行过程中发现内存临时表存储大小达到了上限,会转成磁盘临时表
group by优化—索引
group by需要构造一个带唯一索引的表,如果保证输入数据是有序的那就只需要从左到按顺序扫描就可以了, 因此我们可以利用mysql的索引,而不再需要构建临时表 mysql5.7支持了generated column机制,用来实现列数据的关联更新
|
|
所以原来的语句可以替换为
|
|
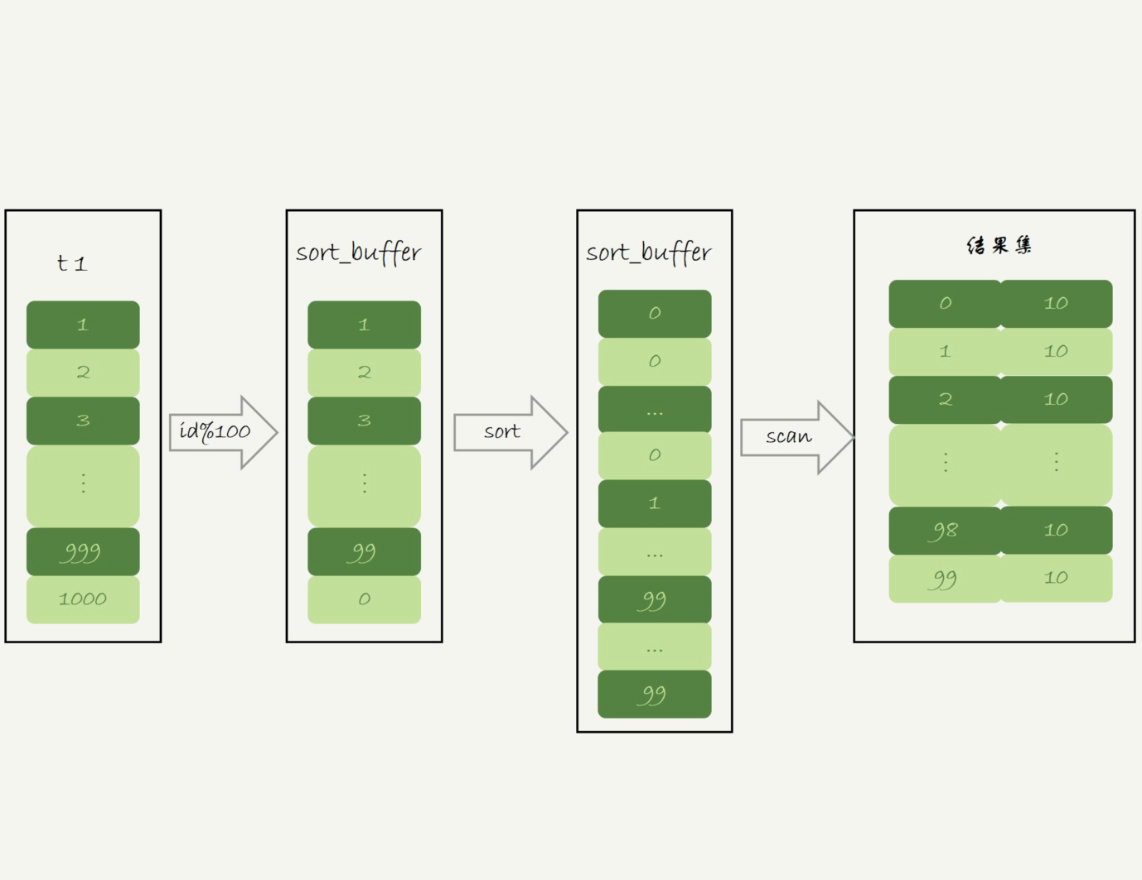
group by优化—直接排序
如果知道数据量很大,内存临时表放不下,可以加SQL_BIG_RESULT提示直接走磁盘临时表
|
|
由于磁盘临时表是B+树存储, 存储效率不如数组效率来得高,优化器会直接用数组
- 初始化sort buffer, 确认放入一个整形字段,记为m;
- 扫描索引a,依次取出里面的id值,将id%1000的值存入sort buffer
- 扫描完后对m排序,如果sort buffer内存不够用,就会用磁盘临时文件辅助排序
- 排完序后就得到了一个有序数组
执行流程如下图
第38讲 要不要用Memory引擎
memory引擎的区别
- 数据和索引分开存放,数据部分以数组的形式单独存放
- 主键使用hash索引, 索引的key并不是有序的
- 范围查询的时候需要全表扫描,也就是顺序扫描数组
- 数据按写入顺序存放,有空洞就可以插入新值
- 数据位置发生变化时,内存表需要修改所有索引,innodb只要改主键索引
- 内存表不支持变长数据类型,varchar(N)会当做char(N),所以每行的数据长度相同
使用B-tree索引
|
|
内存表的局限
- 只支持表锁,有任何更新,会堵住其他所有读写操作
- 数据可能会被清空
使用场景
- 临时表: 其他线程不可见,没有并发;不需要持久化
第39讲 自增主键为什么不是连续的
自增值的存储
- MyISAM: 自增值保存在数据文件中
- InnoDB: 自增值保存在内存中
- 5.7及之前: 重启后第一次打开表的时候会去找max(id)然后将max(id)+1作为当前的自增值
- 8.0开始自增值的变更记录存在了redo log中,重启的时候依靠redo log恢复
自增值的修改机制
- 插入数据时如果字段指定为0、null或未指定值,那就把这个字段设为自增值
- 否则用指定的值
自增主键不连续的原因
- 唯一索引冲突
- 事务回滚
表自增锁释放策略 innodb_autoinc_lock_mode
- 0: 语句结束后再释放锁
- 1: 对于普通insert语句自增锁在申请之后马上释放,类似insert… select这种不知道具体插入数据量的语句,等语句结束后再释放锁
- 2(8.0.3版本默认值): 申请后就释放锁 (对于insert…select语句可以设置为2同时binlog_format=row, 这样既提升并发性,也不会出现数据不一致的问题)
批量申请自增id策略
对于批量插入数据的语句
- 第一次申请分配1个
- 第n次分配2^(n-1)个
第40讲 insert语句锁为什么这么多
- insert…select 在RR隔离级别下,会给select的表扫描到的记录和间隙加读锁
- insert 和select的对象是同一个表时可能造成循环写入,需用临时表做优化
- insert语句如果出现唯一键冲突,会在冲突的唯一值上加上next-key lock
第41讲 怎么快速复制一张表
使用mysqldump
|
|
参数解释
--single-transaction: 使用start transaction with consistant snapshot而非加表锁--add-locks=0: b表示输出文件里不增加lock tables t write--no-create-info: 不要导出表结构--set-gtid-pruged-id=off: 不输出和GTID相关的信息
导出csv文件
|
|
|
|
物理拷贝
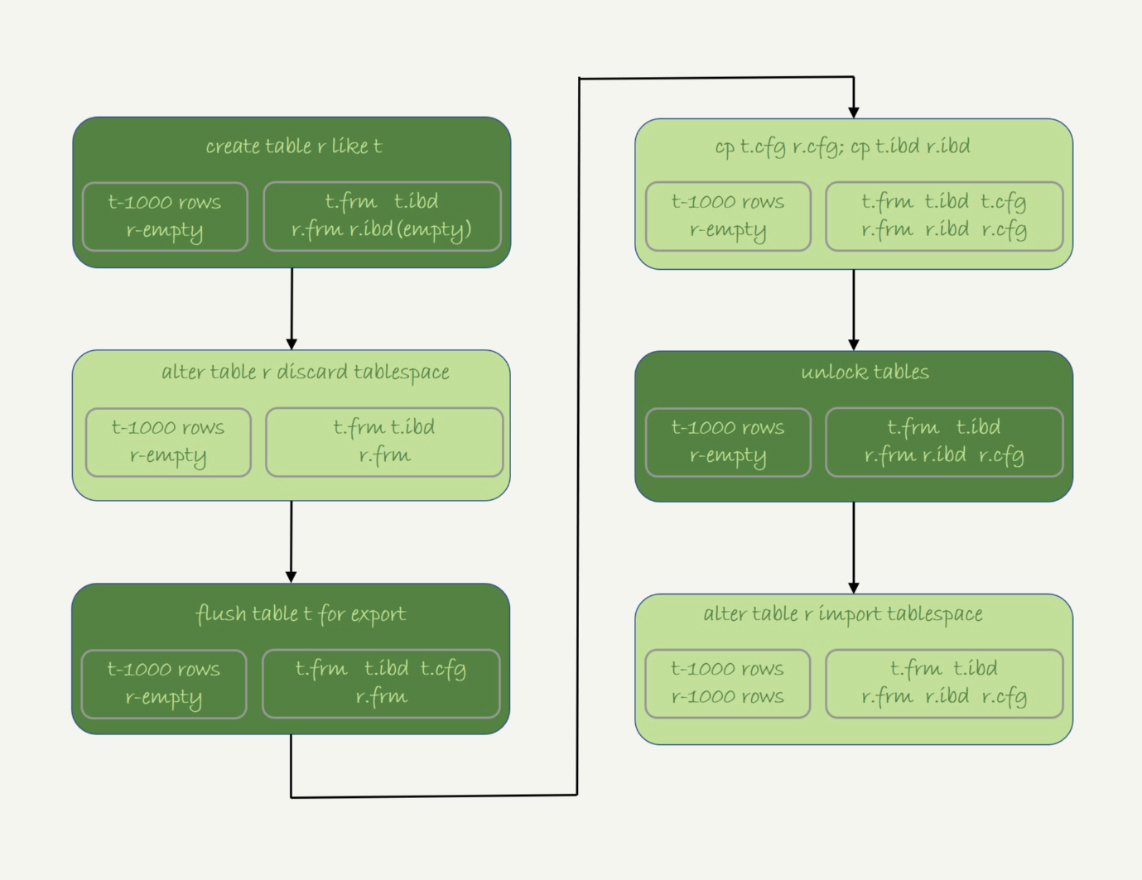
对比
- 物理拷贝最快,只能服务器上拷贝,只能全表拷贝,只能都是innoDB引擎
- mysqldump支持where
- select …info outfile最灵活
第42讲 grant
创建测试用户
|
|
全局权限
|
|
这个grant命令做了两个动作
- 磁盘中,将mysql.user表该用户所有表示权限的字段都改为‘Y’
- 内存里,从数组acl_users中找到这个用户对应的对象,将access二进制值全改为1
grant不会影响到已经登录的连接
db权限
|
|
这个grant命令做了两个动作
- 磁盘中,将mysql.db表该用户所有表示权限的字段都改为‘Y’
- 内存里,从数组acl_dbs中找到这个用户对应的对象,将access二进制值全改为1
db权限在use db时会将权限保存在会话变量中。所以不会受到权限变更影响,除此之外其他已有的连接会受到影响
表权限和列权限
表权限定义存储在mysql.tables_priv中,列权限定义存在mysql.columns_priv中,这两类权限组合起来存在内存的hash结果column_priv_hash中。
变更时会同步更新内存中的hash结构,因此会影响到已存在的连接
flush_privileges
flush privileges命令会清空全局内存权限数据,然后从表中读取数据重新构造。所以当内存权限数据和磁盘权限数据相同的话不需要flush privilefes
需要该操作往往是因为直接使用DML语句操作系统权限表造成的

删除用户应该使用drop user
第43讲 要不要使用分区表
|
|
对于引擎层来说是多个表,对于Server层来说是一个表
因为服务层是单个表,所以共用一个MDL锁
因为在引擎层是多个表,等值查询产生的间隙锁,引擎层加锁的时候只会锁一个表
第一次访问的时候需要访问所有分区
分区策略可以使用range list hash等
第44讲 答疑三
join的写法
初始数据
|
|
- Q1
|
|
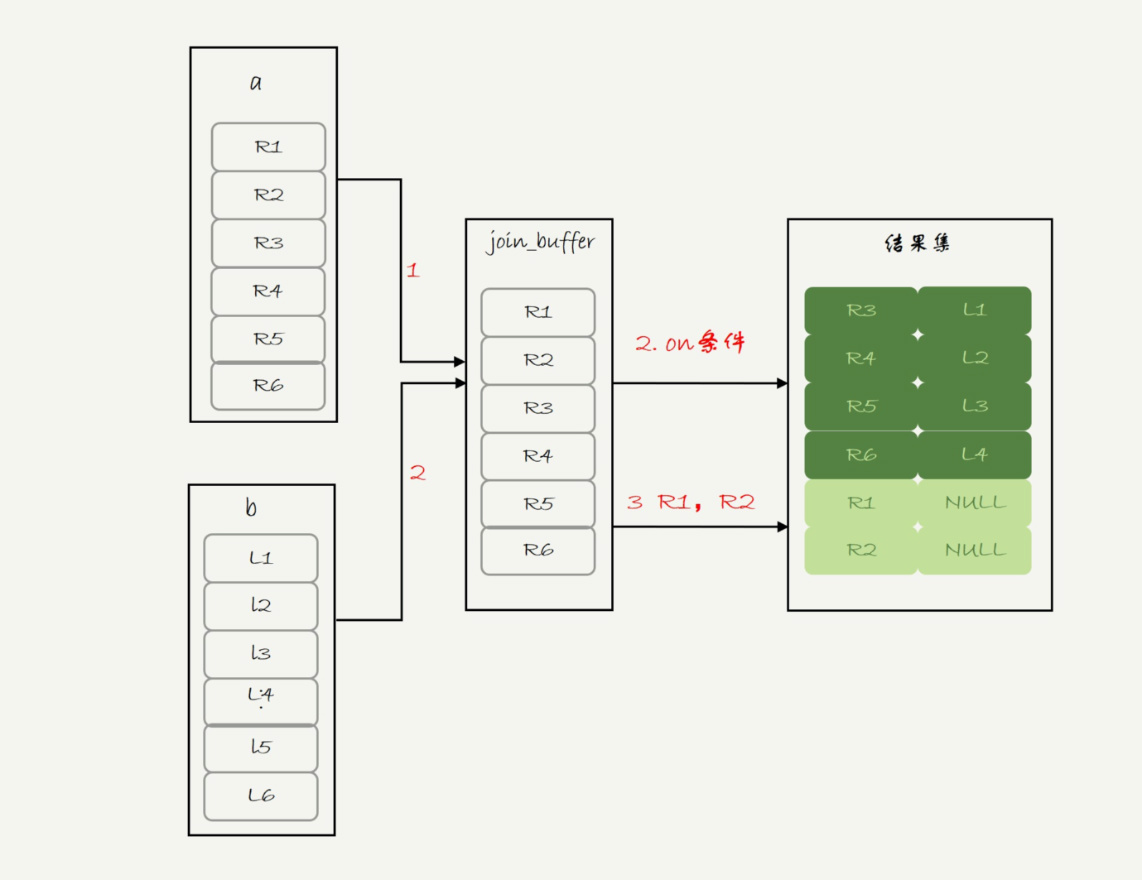
驱动表为a,因为b.f1没有索引使用Block Nested Loop Join算法。执行的流程是: 把表a的内容读入join_buffer中,顺序扫描b,判断是否符合join条件,符合的话作为结果集的一行返回。最后对于没有被匹配的表a的行,把剩余字段补NULL返回
- Q2
|
|
驱动表为b,使用Index Nested-Loop Join, 顺序扫面b,每一行用b.f1到a中去查,然后再判断f2字段是否相等,如果是则作为结果集的一行.
因为与NUll值比较永远返回NULL, where a.f2 = b.f2就不会包含b.f2是NULL的行。优化器把left join改成了join, 因为a.f1有所以所以把b作为了驱动表,可以通过show warning查看这个改写的结果
所以left join 左表不一定是驱动表
如果要符合left join语句,就不能把驱动表的字段放在where条件里做等值判断
- Q3
|
|
- Q4
|
|
通过show warnings 可以看到Q3/Q4都被转换了为
|
|
distinct和group by的性能
|
|
由于group不需要聚合,以上两句语句执行流程是一样的
- 创建临时表,只有字段a,且创建唯一索引a
- 遍历全表,将数据一次插入临时表,如唯一键冲突则跳过
- 遍历完之后将临时表作为结果集放回给客户端
备库自增主键问题
自增id的生成顺序和binlog的写入顺序可能不同,在binlog=statement格式下,insert语句之前会记录SET INSERT_ID=XXX,所以不会出现问题
第45讲 自增id用完怎么办
表定义自增id
|
|
达到上限后AUTO_INCREMENT不会改变,后续插入后报主键冲突
系统自增row_id
创建InnoDB表如果没有指定主键,会创建一个不可见的长度为8字节的无符号整形,数据写入时,只取了后面6字节, 所以到row_id == 2^48时,想当时row_id=0, 这是会覆盖已经存在的行
thread_id
thread_id_counter: 4字节 全局变量
|
|