第2讲 数据结构: Redis有哪些慢操作
基本数据结构
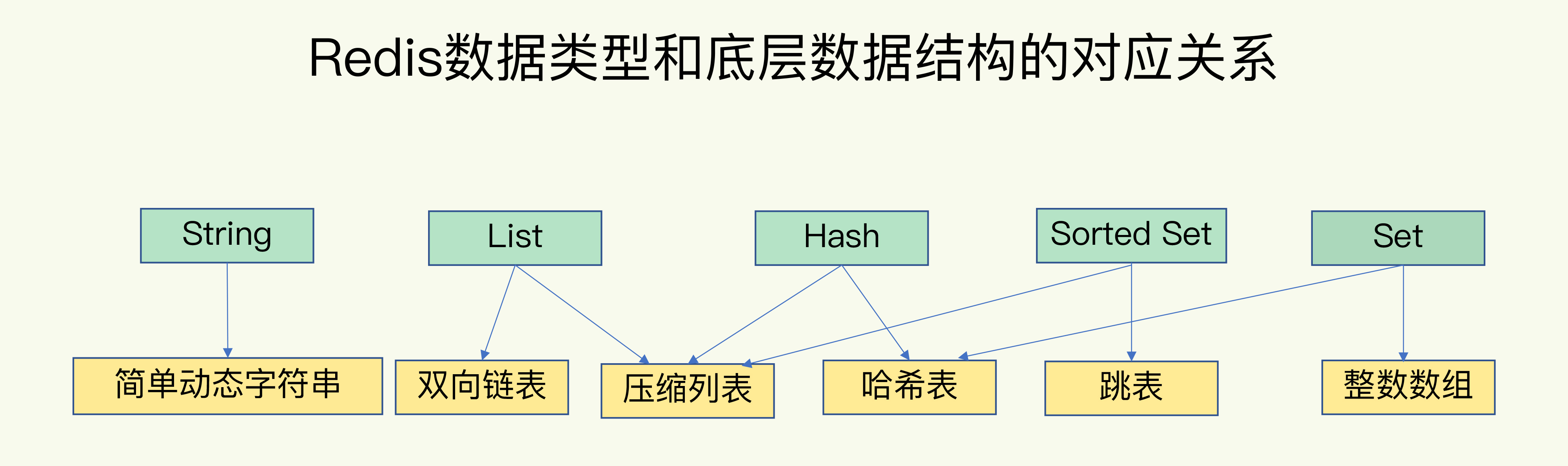
五种数据类型
- String
- List
- Hash
- Set
- Sorted Set
底层数据结构
全局键值对
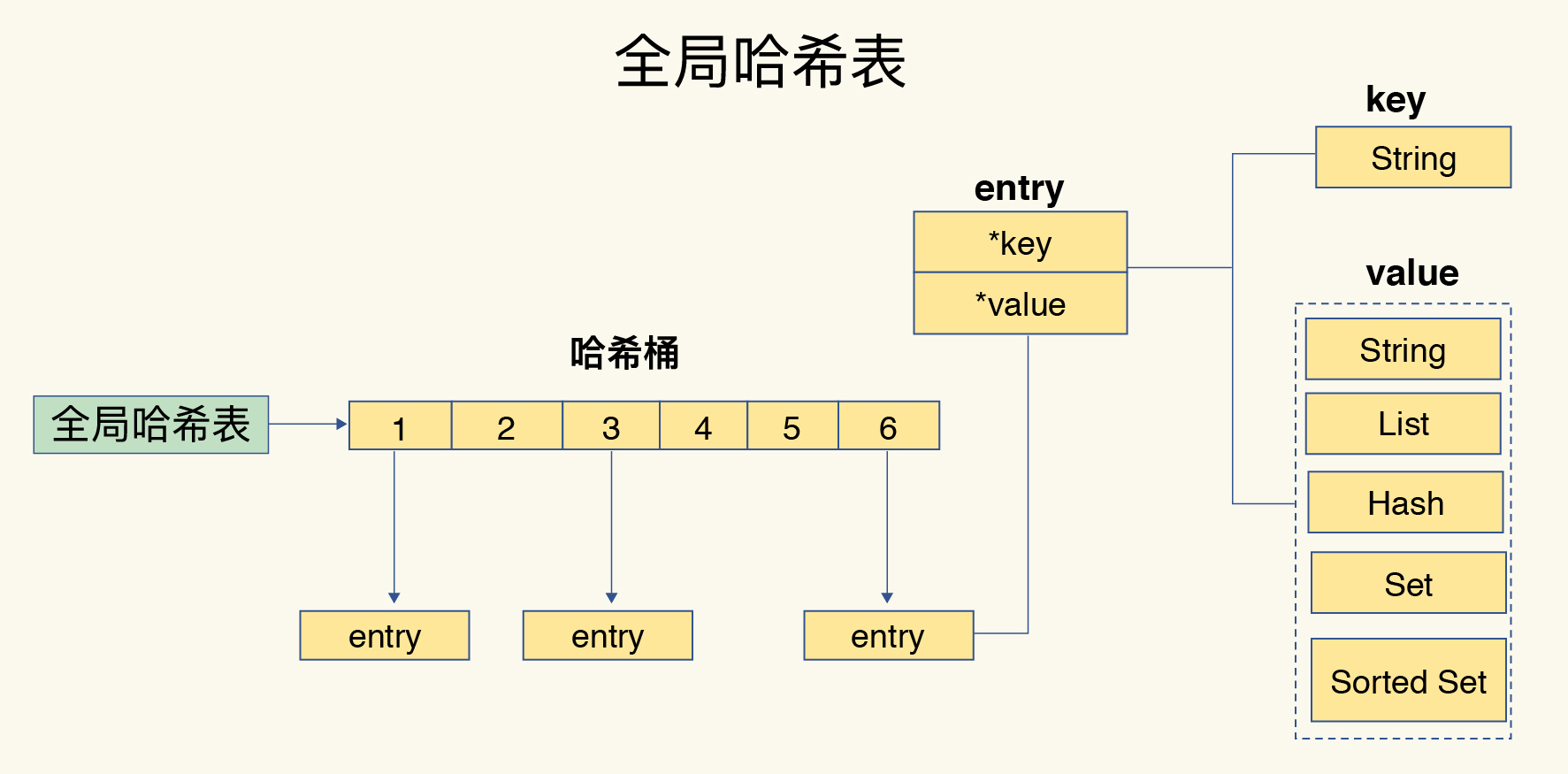
-
桶中的元素都是指向具体值的指针
-
通过链表解决冲突
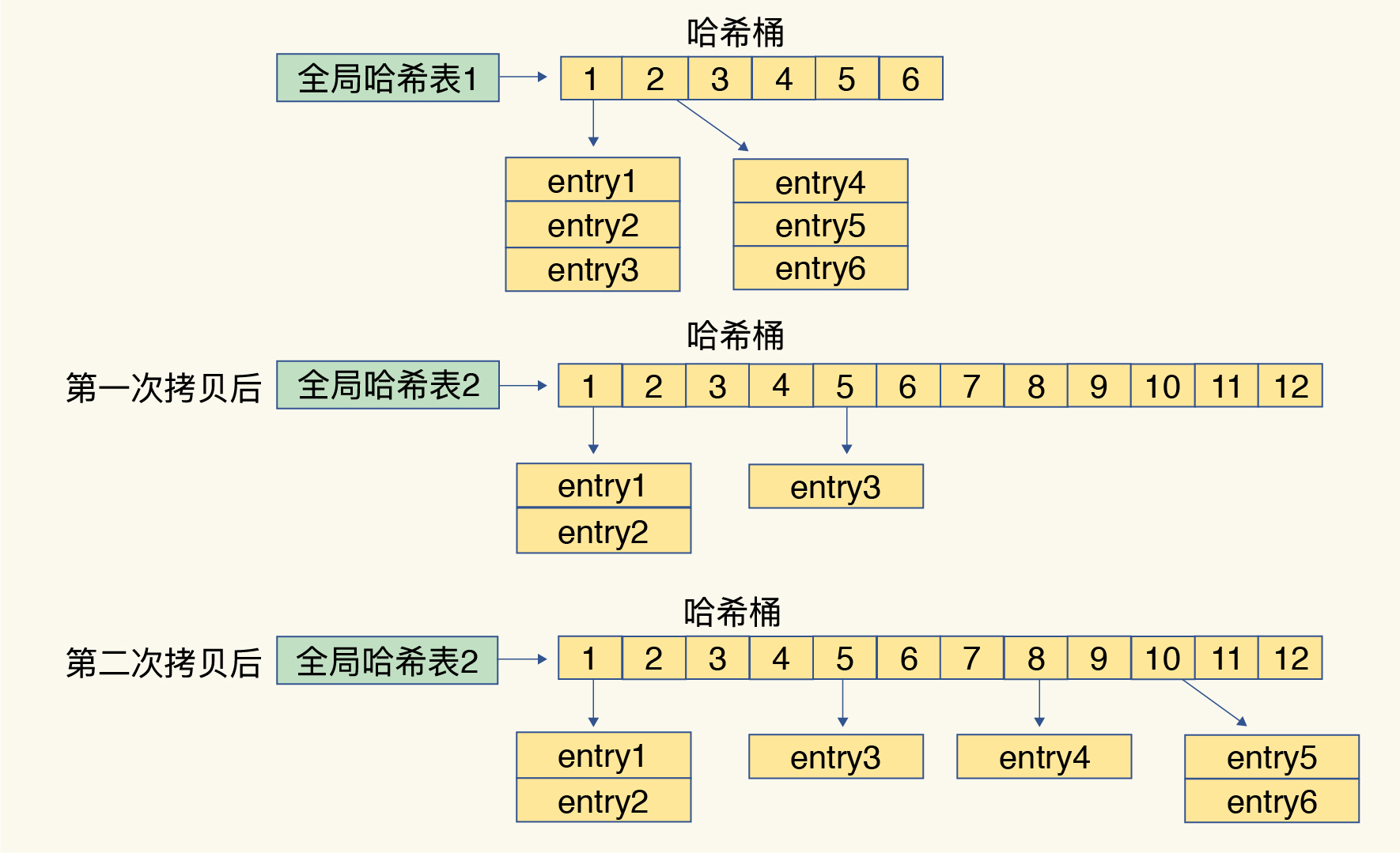
-
rehash
- 使用两个全局哈希表,默认使用表1
- rehash时给表2分配更大的空间
- 渐进式地将表1的数据拷贝到表2,每处理一个请求,将一个桶中的所有数据拷贝走
- 同时也有后台周期(如100ms)迁移任务
- 释放表1的空间
集合数据操作效率
压缩列表
类似数组,在表头前有三个字段zlbytes(列表长度)、zltail(表尾偏移量)、zlen(entry个数), 表尾有一个字段zlend(结束标志位)

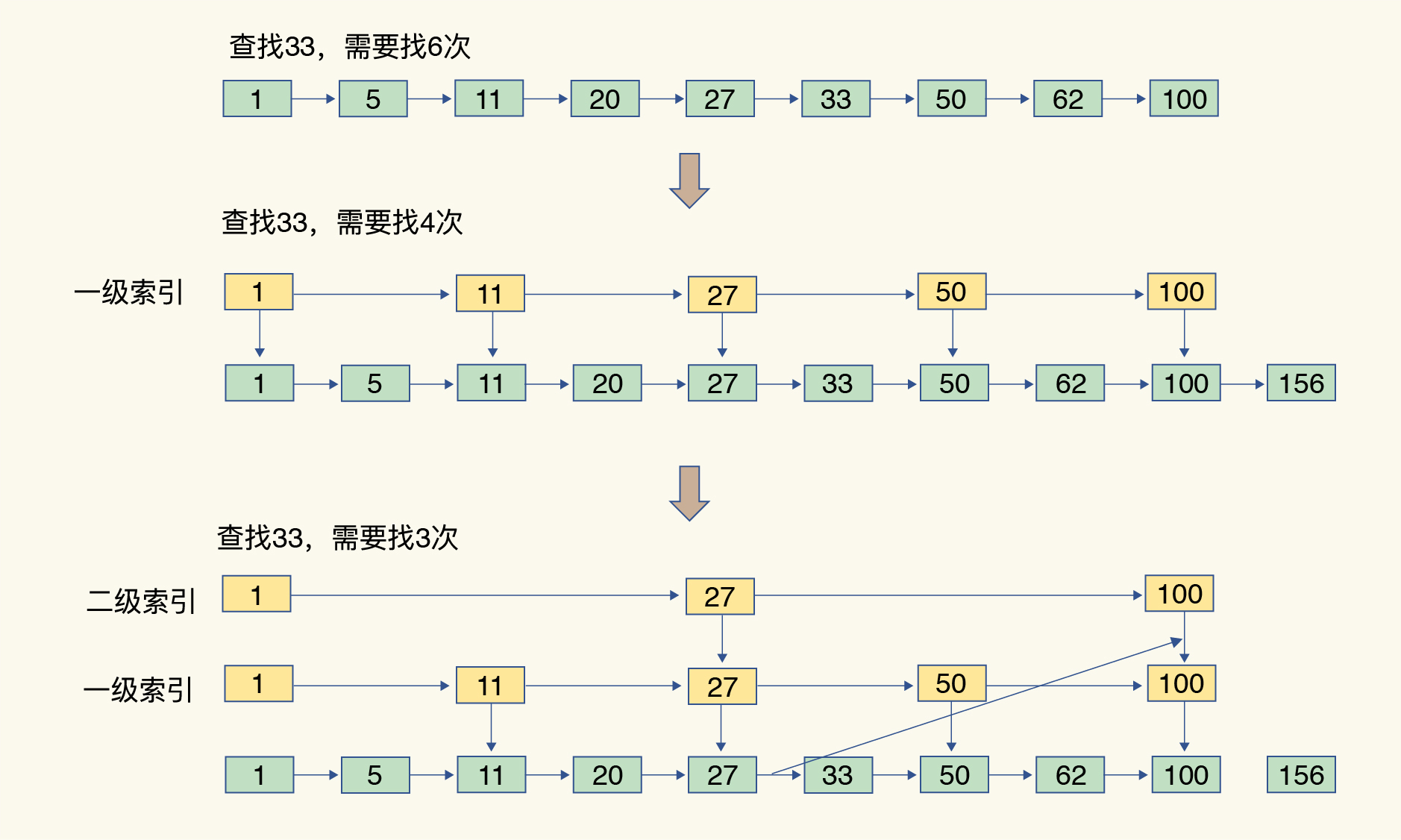
跳表
在链表的基础上,增加了多级索引,实现数据的快速定位
第3讲 高性能模型: Redis单线程为什么那么快
Redis单线程是指网络IO和键值对读写是有同一个线程完成的 其他功能如持久化、异步删除等是有额外线程执行的
快的原因
- 大部分操作在内存中完成
- 高效的数据结构
- IO多路复用机制
同步IO模型
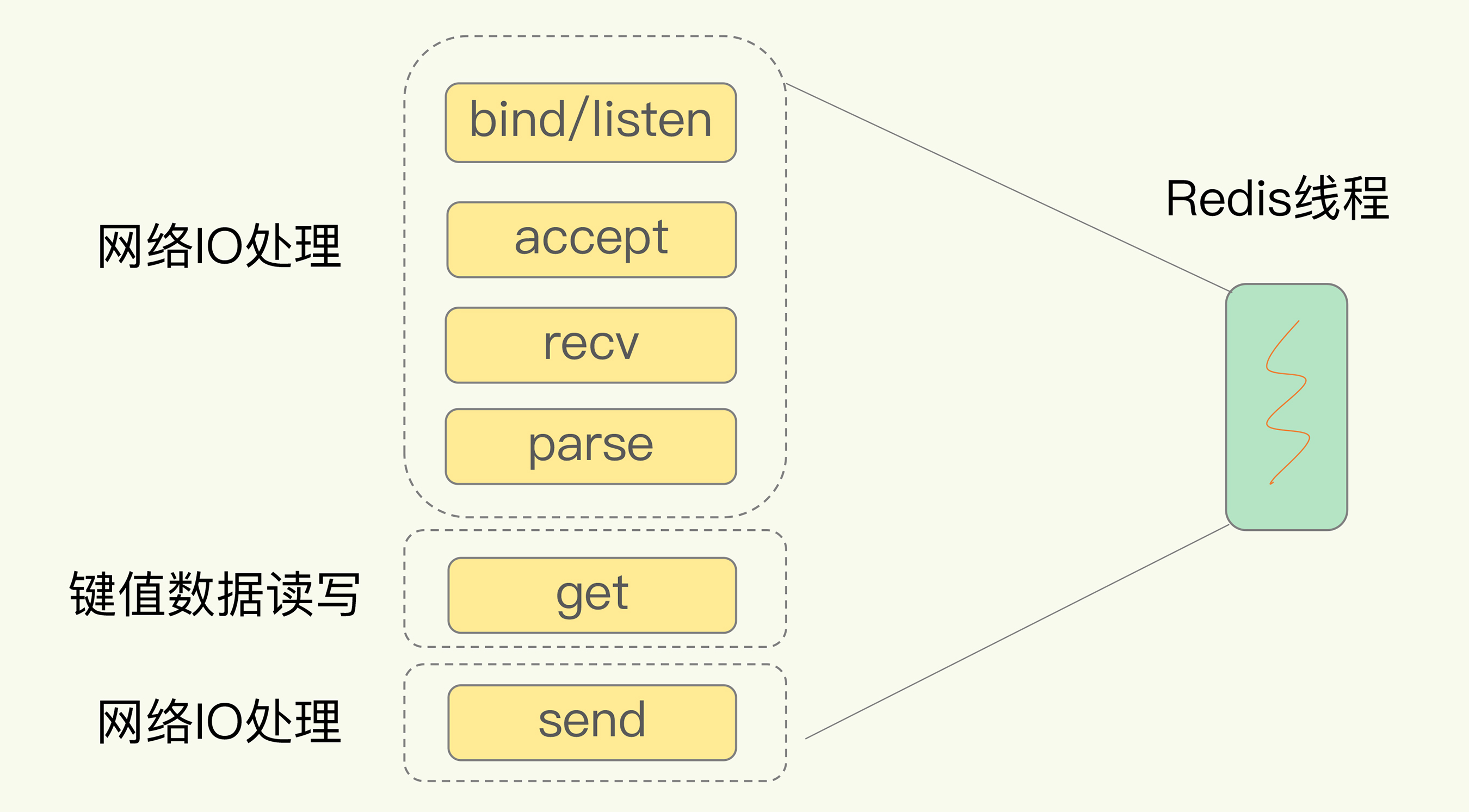
阻塞点:accept, recv, send
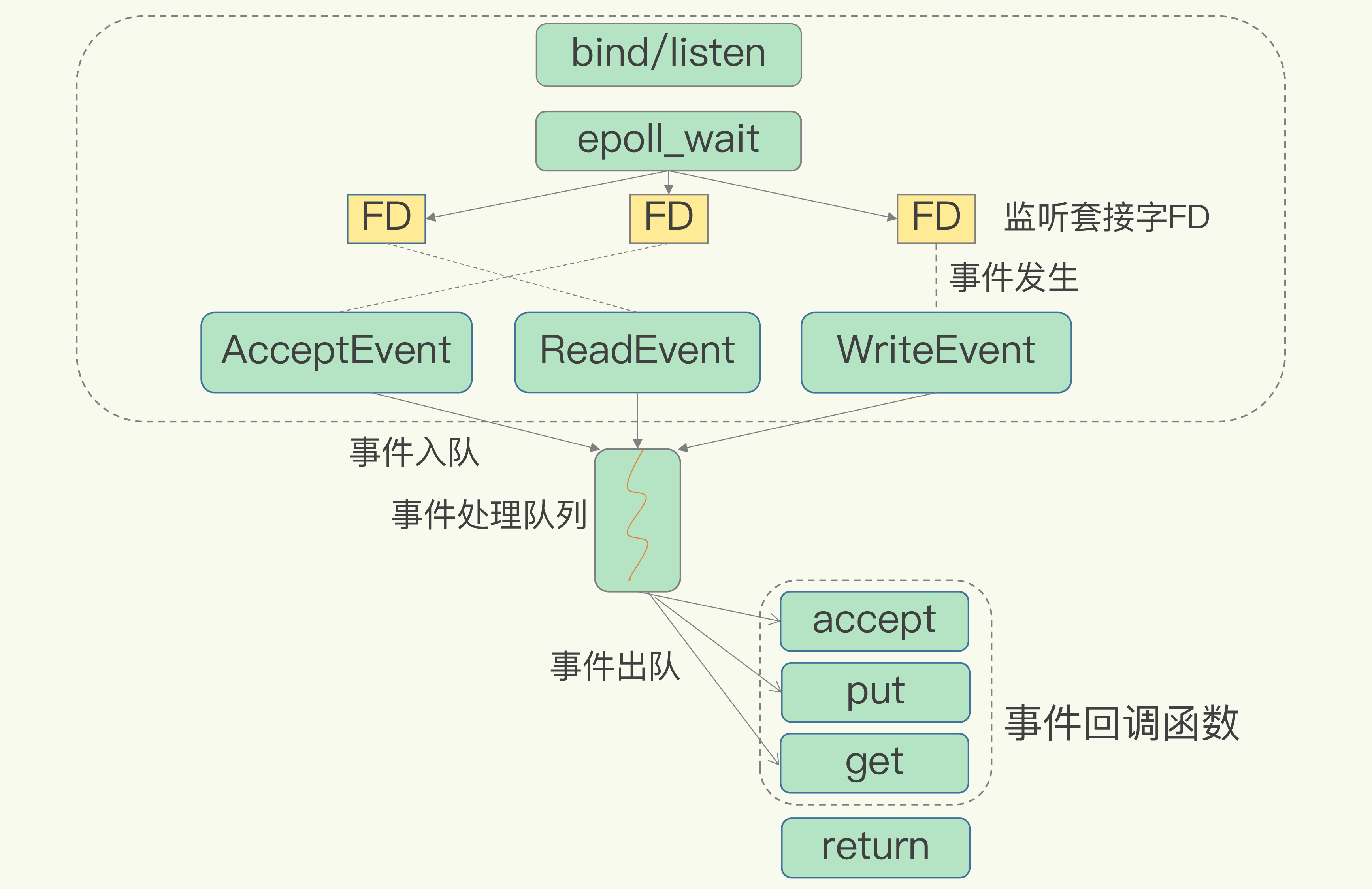
非阻塞IO
IO复用是指一个线程同时处理多个IO流
第4讲 AOF(append only file)日志
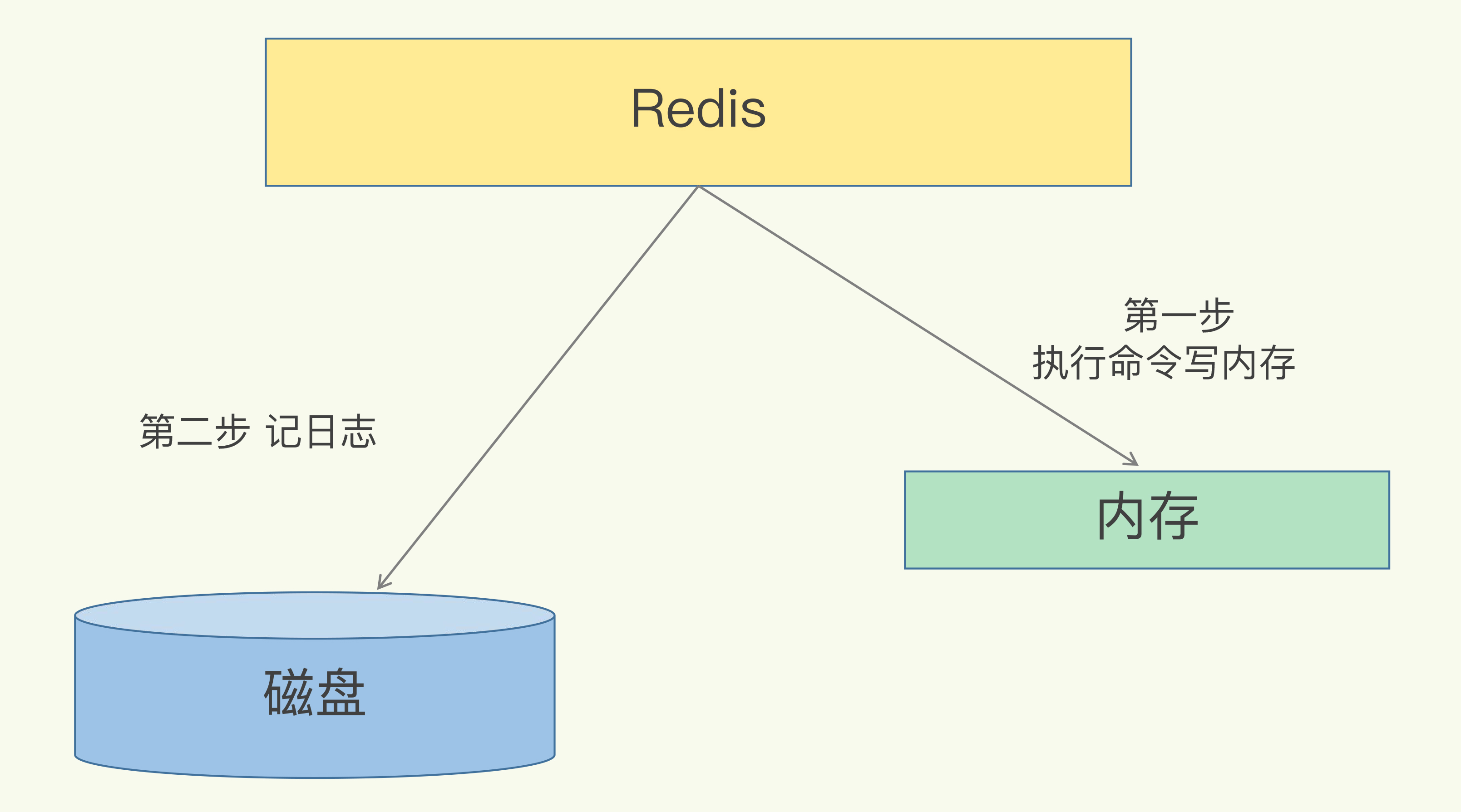
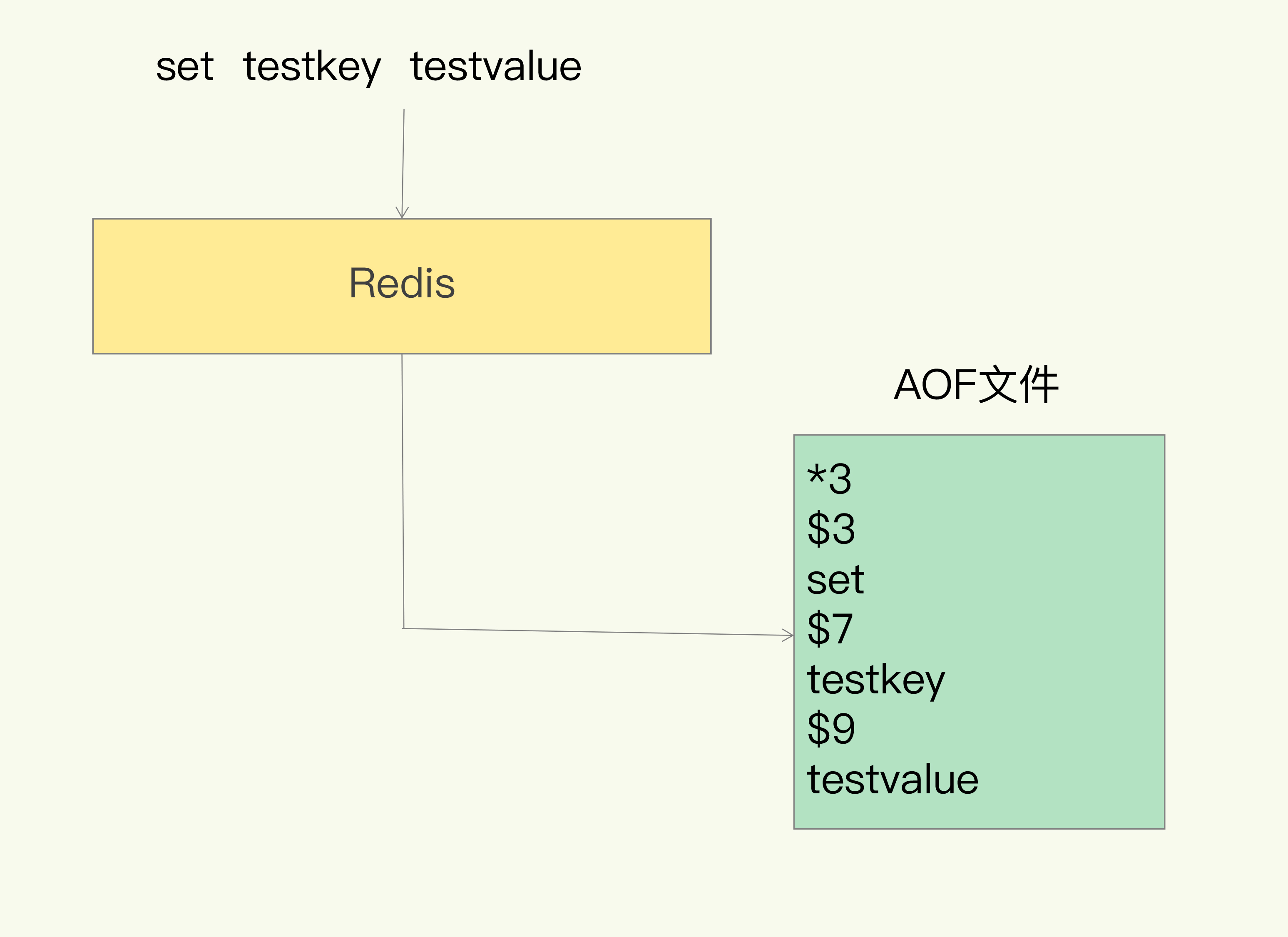
AOF是写后日志,先执行命令后记录日志,避免了额外的检查开销
具体记录的是每条命令,以文本方式保存
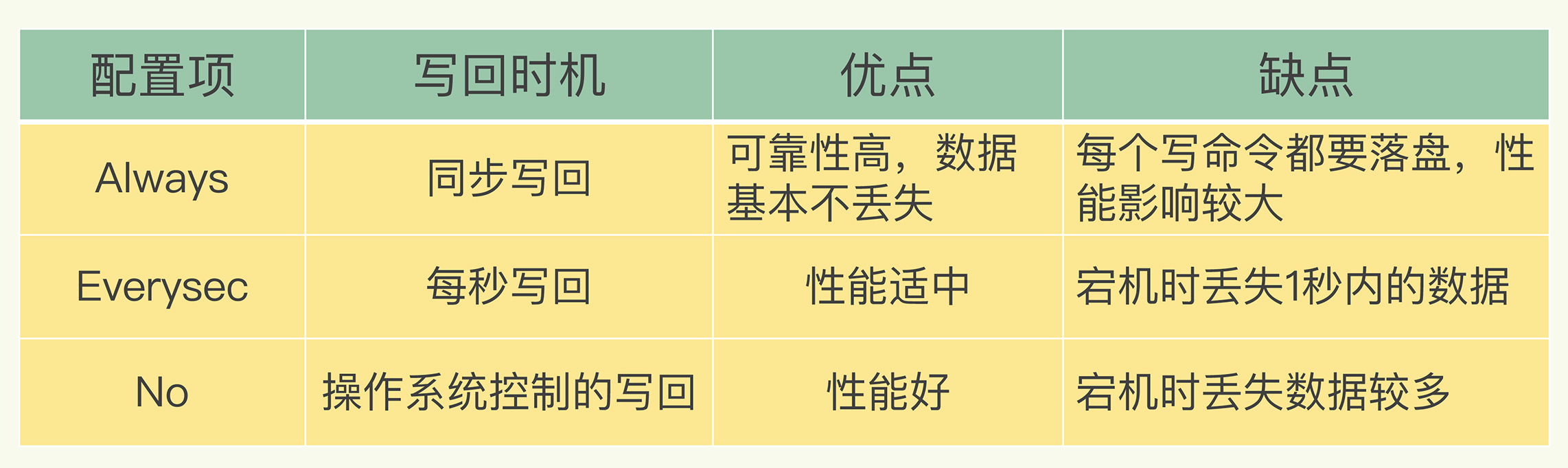
三种写策略
- Always: 每执行一个命令完,立马写磁盘
- Everysec:先把日志写入缓存区,每秒写一次磁盘
- No: 把日志写入缓存区,由操作系统决定何时写入磁盘
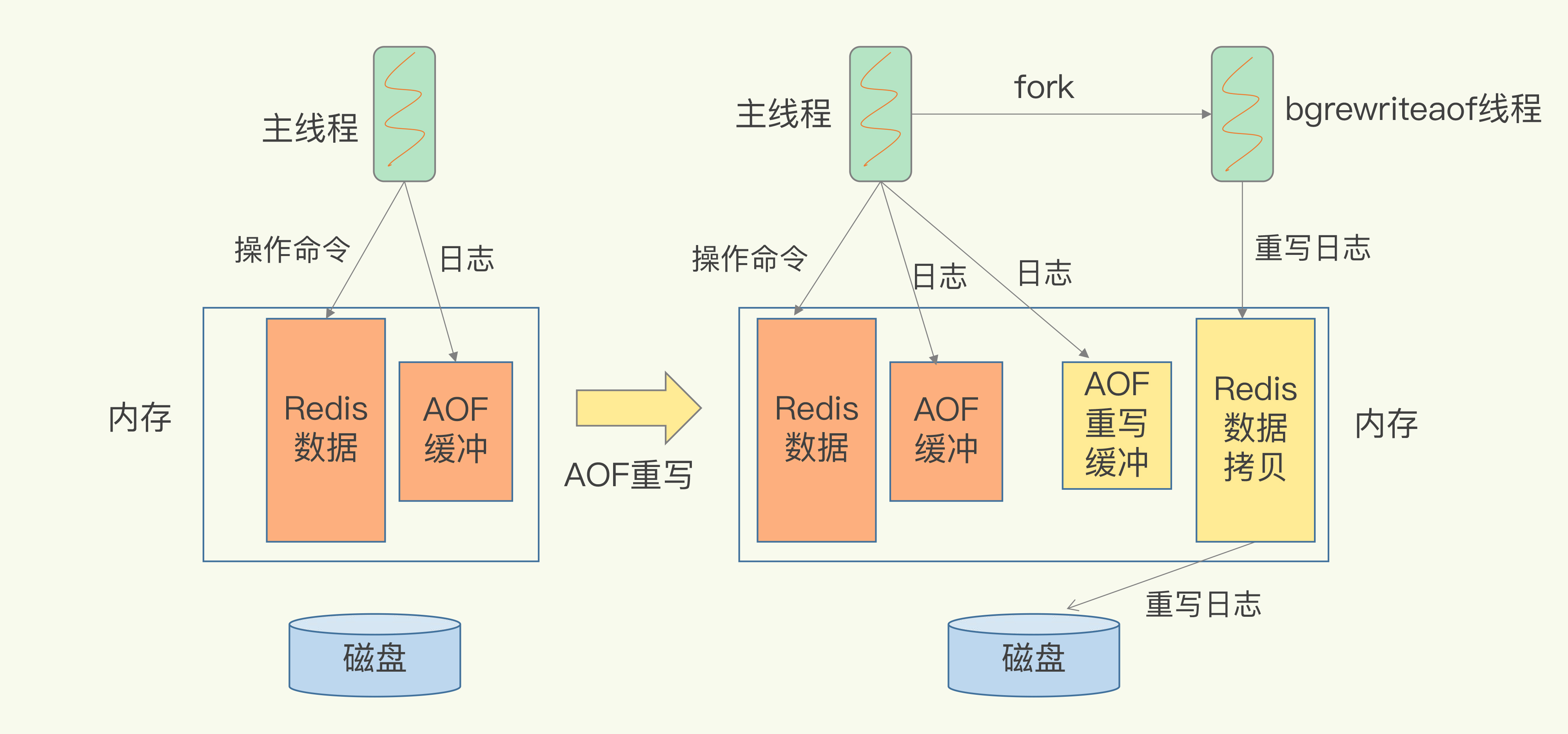
AOF重写
fork一个子进程bgrewriteaof, 子进程读取所有的键值对,然后对每一个键值对用一条命令记录它的写入到临时文件, 主进程在重写期间会将新的写操作会同时写到AOF缓冲和AOF重写缓冲, 等重写完成后,子进程会发信号给父进程, 父进程将新的AOF重写缓冲追加到临时文件, 父进程用临时文件替换原有的AOF文件。
潜在阻塞点
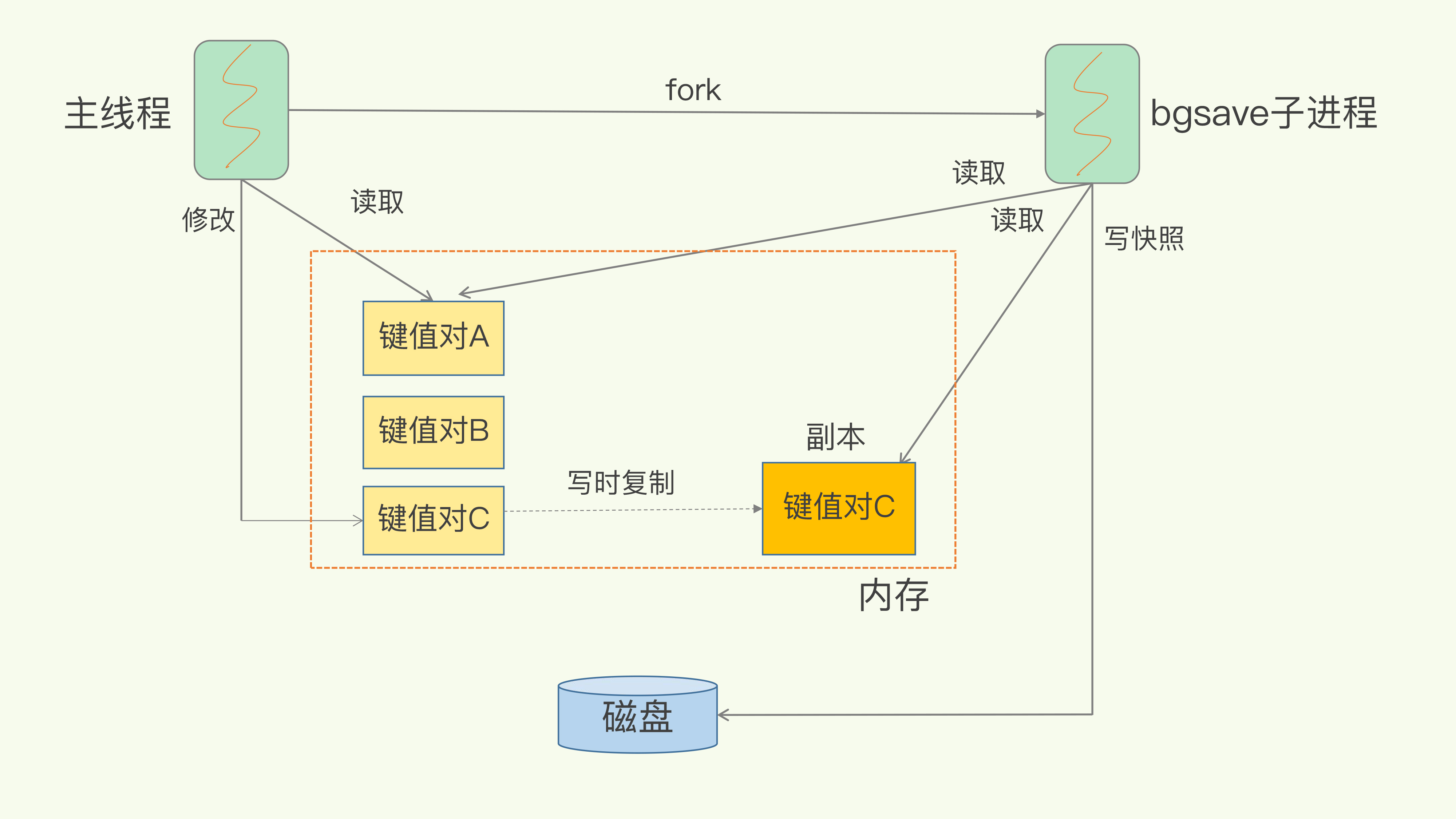
- fork过程是阻塞的,虽然copy-on-write, 但fork还是需要拷贝内存表(虚拟内存和物理内存的映射索引表)
- fork后对父进程操作现有的key,会真正拷贝对应的内存数据,申请新的内存空间
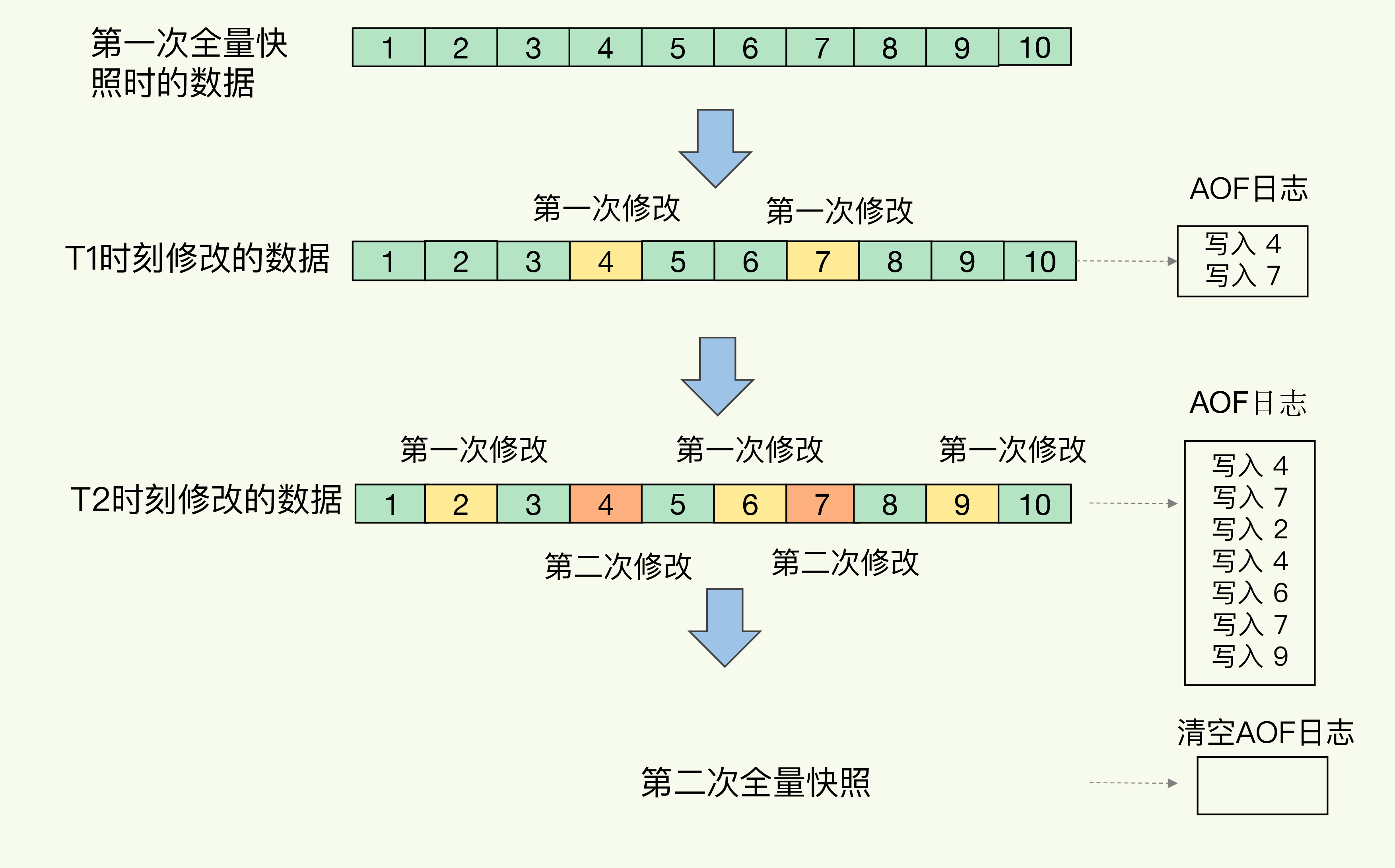
第5讲 RDB内存快照
内存快照是指内存中的数据在某一个时刻的状态的记录
bgsave会fork一个子进程将内存的数据写入RDB文件
内存快照和AOF日志混合使用
两次备份快照期间,中间的写操作用AOF日志记录,开始新的快照备份时清空AOF日志
第6讲 主从库如何实现数据一致
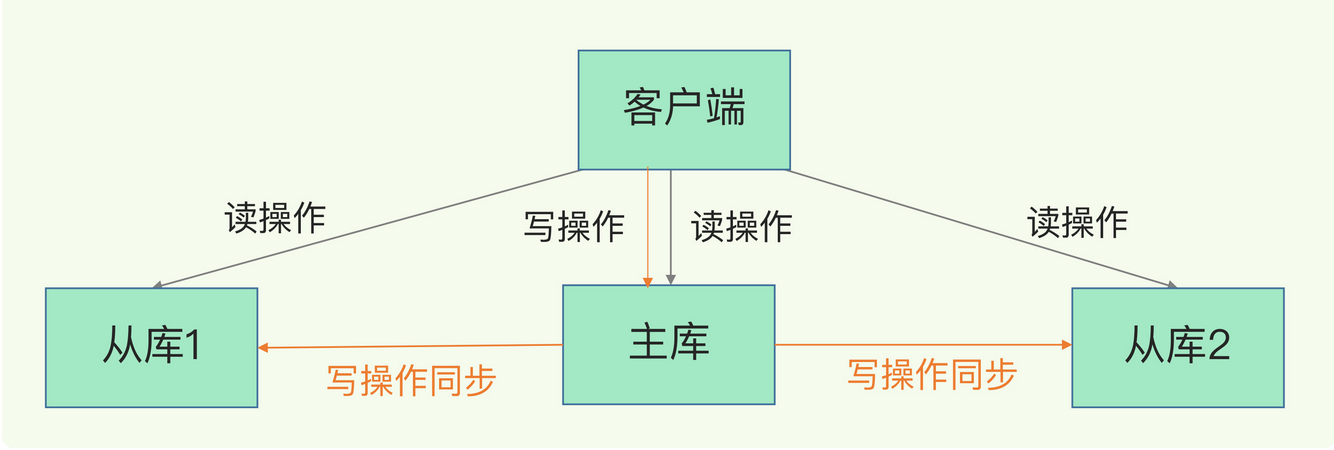
读写分离
- 读操作:主库从库都可以接收
- 写操作:首先到主库执行,然后将写操作同步给从库
主从库间的第一次同步
- 从库发送
psync master_runID offset,因为是第一次复制,将runID设为"?",offset设为-1,表示全量复制 - 主库发送
FULLRESYNC runID offset,发送主库runID和当前复制进度;同时因为是第一次全量复制,主库会执行bgsave,生成RBD文件, 发送给从库,从库收到文件后,会清空当前数据库,然后加载RDB文件,这一阶段新的写操作会记录在这专门给这个slave的replication buffer中 - 主库将replication buffer发送给从库
注: Redis先把数据写到buffer中,然后再把buffer中的数据发到client socket中再通过网络发送出去。 从库作为一个client,也会分配一个buffer,只不过这个buffer专门用来传播用户的写命令到从库,保证主从数据一致,我们通常把它叫做replication buffer。 通过client-output-buffer-limit控制这个buffer的大小

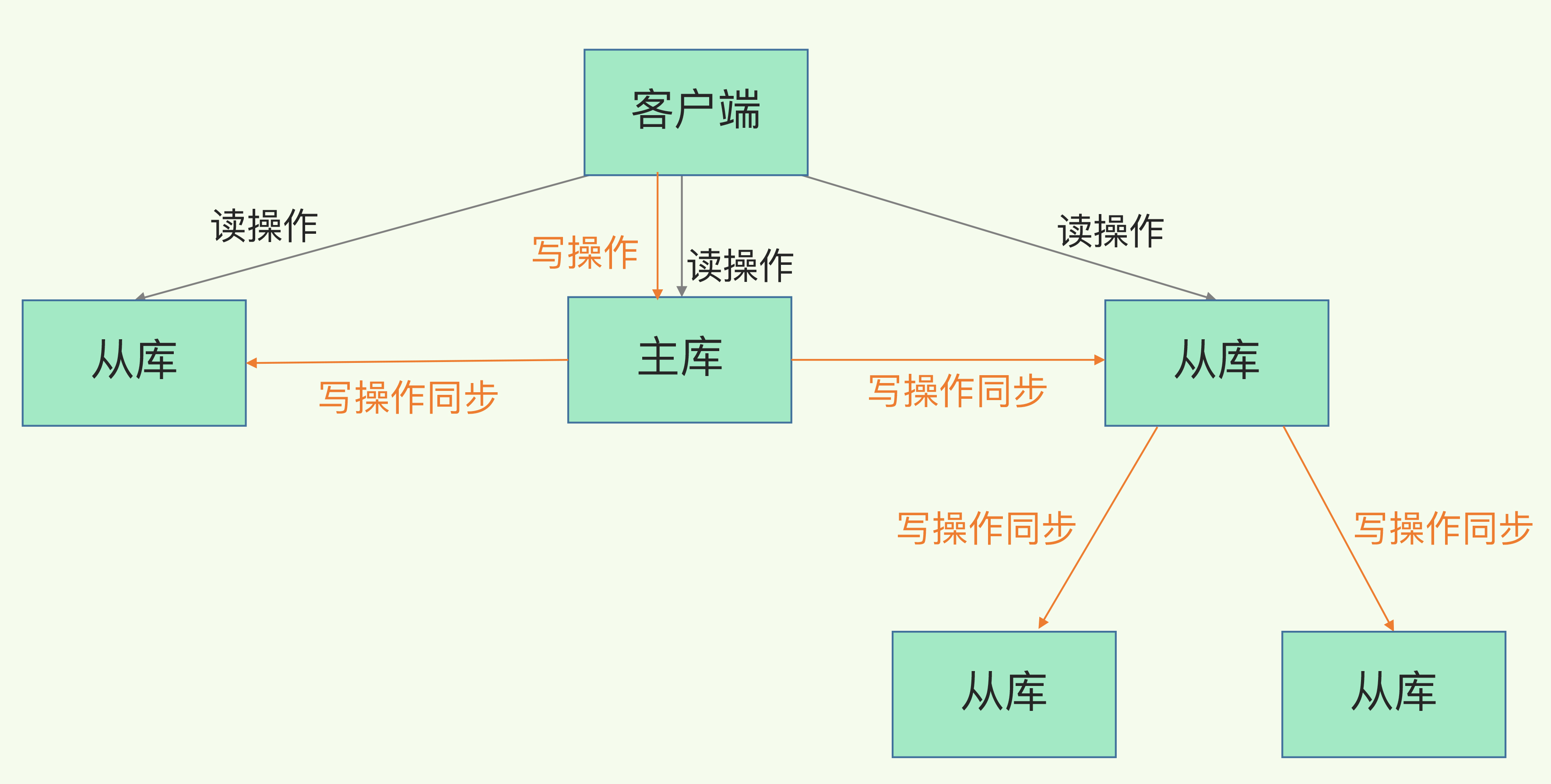
级联模式减轻主库压力
通过"主 - 从 - 从"模式将主库生成RBD和传输RBD的压力以级联的方式分散到从库上
长连接命令传播
主从库之间完成了全量复制之后,他们会维护一个长连接,主库会通过这个连接将后续收到的写操作 同步给从库
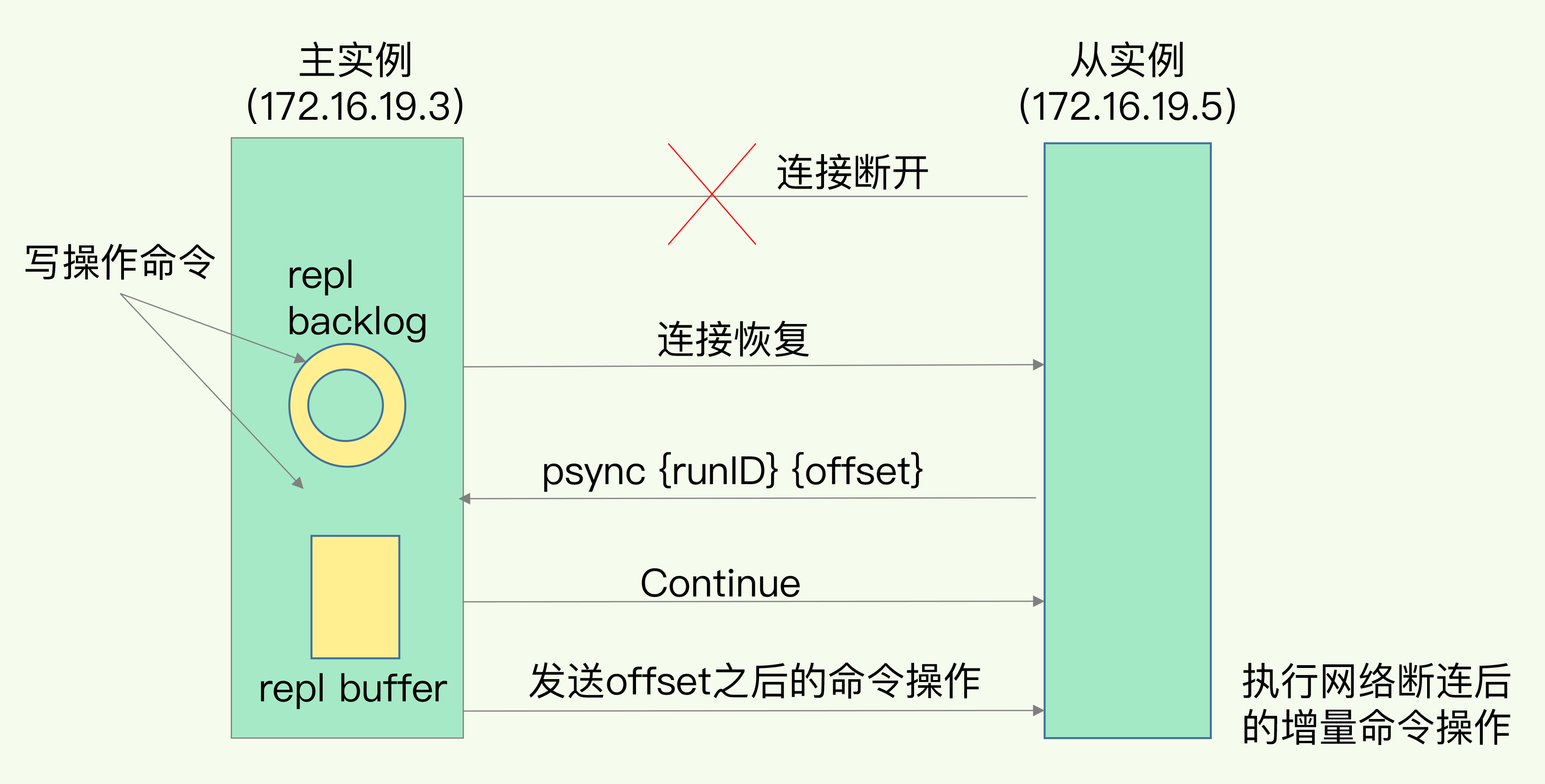
主从增量同步
主从库断连后,主库会将断连期间的写操作继续写到repl_backlog_buffer环形缓冲区中。 主库会记录自己写到的位置master_repl_offset,从库则会记录自己已经读到的位置slave_repl_offset
- 主从库恢复连接后,从库会发送psync命令告知当前的slave_repl_offset, 如果没有被覆写,主库会将 master_repl_offset和slave_repl_offset之间的写操作发送给从库,如果被覆写会进行全量复制
- 环形缓冲区通过repl_backlog_size控制,需要结合主库的写入速度和主从库建的网络传输速度考虑
注:repl_backlog_buffer用于主从间的增量同步。主节点只有一个repl_backlog_buffer缓冲区,各个从节点的offset偏移量都是相对该缓冲区而言的; replication buffer用于主节点与各个从节点间数据通信,每个连接都独享一个buffer